 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Customized SAT-based Solver for Graph Coloring
Apr 07, 2025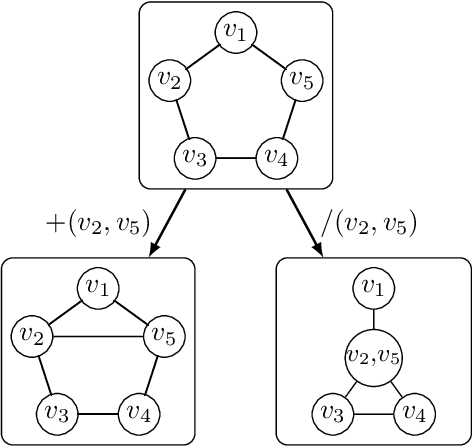
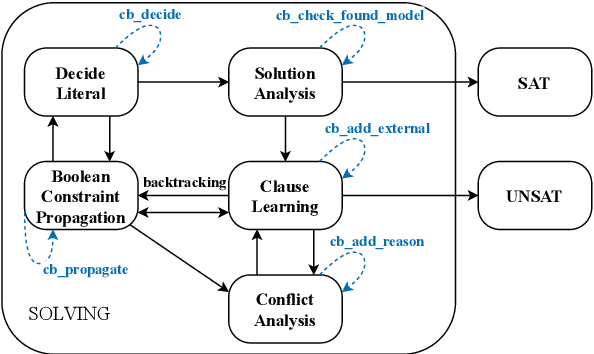

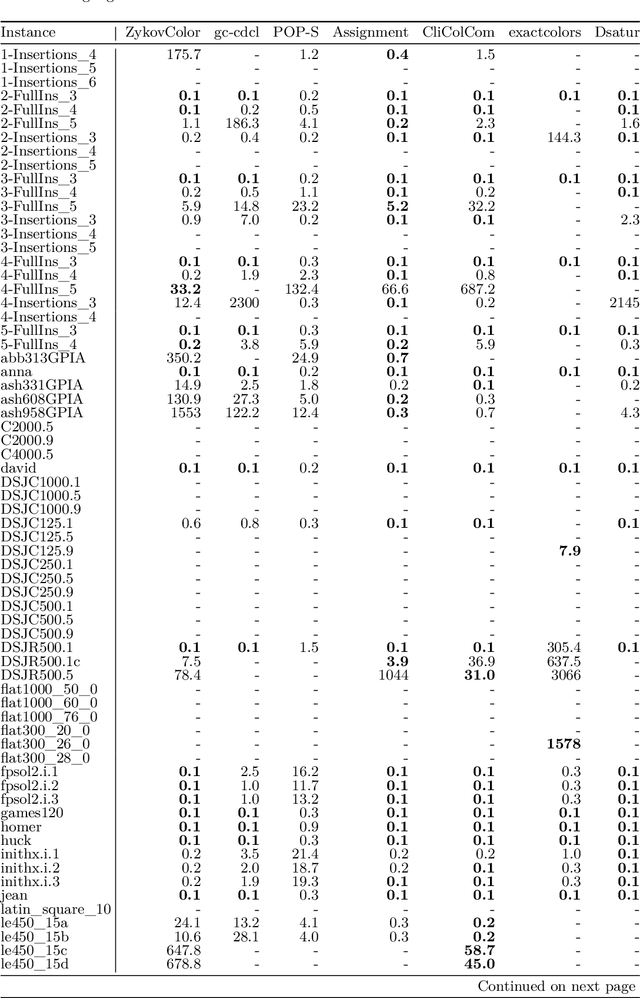
We introduce ZykovColor, a novel SAT-based algorithm to solve the graph coloring problem working on top of an encoding that mimics the Zykov tree. Our method is based on an approach of H\'ebrard and Katsirelos (2020) that employs a propagator to enforce transitivity constraints, incorporate lower bounds for search tree pruning, and enable inferred propagations. We leverage the recently introduced IPASIR-UP interface for CaDiCal to implement these techniques with a SAT solver. Furthermore, we propose new features that take advantage of the underlying SAT solver. These include modifying the integrated decision strategy with vertex domination hints and using incremental bottom-up search that allows to reuse learned clauses from previous calls. Additionally, we integrate a more efficient clique computation to improve the lower bounds during the search. We validate the effectiveness of each new feature through an experimental analysis. ZykovColor outperforms other state-of-the-art graph coloring implementations on the DIMACS benchmark set. Further experiments on random Erd\H{o}s-R\'enyi graphs show that our new approach dominates state-of-the-art SAT-based methods for both very sparse and highly dense graphs.
SAT Encoding of Partial Ordering Models for Graph Coloring Problems
Mar 23, 2024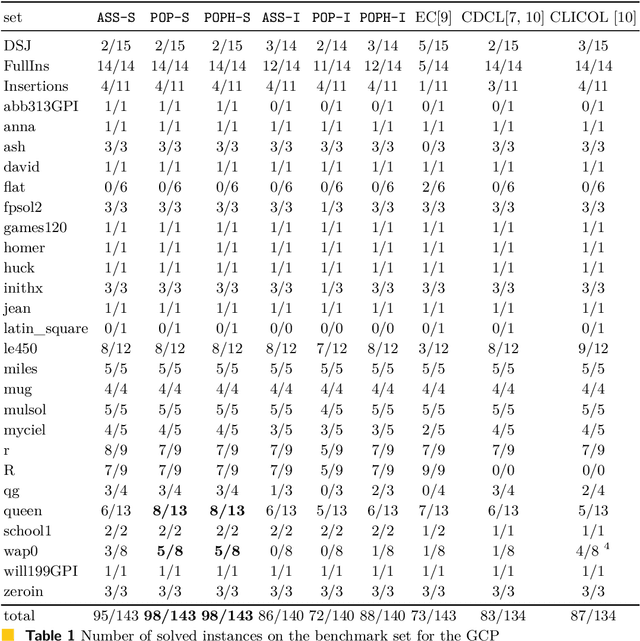
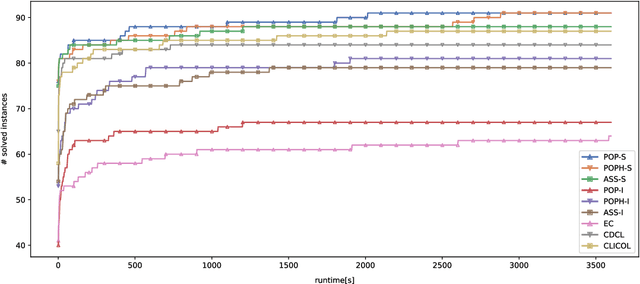
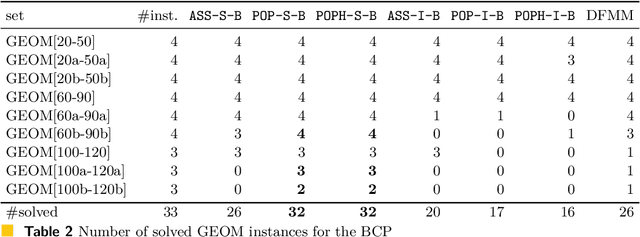
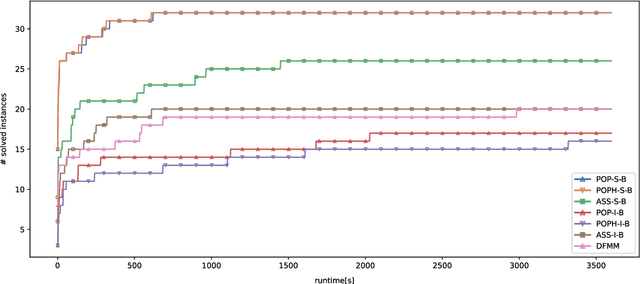
In this paper, we suggest new SAT encodings of the partial-ordering based ILP model for the graph coloring problem (GCP) and the bandwidth coloring problem (BCP). The GCP asks for the minimum number of colors that can be assigned to the vertices of a given graph such that each two adjacent vertices get different colors. The BCP is a generalization, where each edge has a weight that enforces a minimal "distance" between the assigned colors, and the goal is to minimize the "largest" color used. For the widely studied GCP, we experimentally compare our new SAT encoding to the state-of-the-art approaches on the DIMACS benchmark set. Our evaluation confirms that this SAT encoding is effective for sparse graphs and even outperforms the state-of-the-art on some DIMACS instances. For the BCP, our theoretical analysis shows that the partial-ordering based SAT and ILP formulations have an asymptotically smaller size than that of the classical assignment-based model. Our practical evaluation confirms not only a dominance compared to the assignment-based encodings but also to the state-of-the-art approaches on a set of benchmark instances. Up to our knowledge, we have solved several open instances of the BCP from the literature for the first time.
Mining Legal Arguments in Court Decisions
Aug 12, 2022



Identifying, classifying, and analyzing arguments in legal discourse has been a prominent area of research since the inception of the argument mining field. However, there has been a major discrepancy between the way natural language processing (NLP) researchers model and annotate arguments in court decisions and the way legal experts understand and analyze legal argumentation. While computational approaches typically simplify arguments into generic premises and claims, arguments in legal research usually exhibit a rich typology that is important for gaining insights into the particular case and applications of law in general. We address this problem and make several substantial contributions to move the field forward. First, we design a new annotation scheme for legal arguments in proceedings of the European Court of Human Rights (ECHR) that is deeply rooted in the theory and practice of legal argumentation research. Second, we compile and annotate a large corpus of 373 court decisions (2.3M tokens and 15k annotated argument spans). Finally, we train an argument mining model that outperforms state-of-the-art models in the legal NLP domain and provide a thorough expert-based evaluation. All datasets and source codes are available under open lincenses at https://github.com/trusthlt/mining-legal-arguments.