 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeBERTis: A Framework for Producing Classifiers of Security-Related Issue Reports
Dec 17, 2025Monitoring issue tracker submissions is a crucial software maintenance activity. A key goal is the prioritization of high risk, security-related bugs. If such bugs can be recognized early, the risk of propagation to dependent products and endangerment of stakeholder benefits can be mitigated. To assist triage engineers with this task, several automatic detection techniques, from Machine Learning (ML) models to prompting Large Language Models (LLMs), have been proposed. Although promising to some extent, prior techniques often memorize lexical cues as decision shortcuts, yielding low detection rate specifically for more complex submissions. As such, these classifiers do not yet reach the practical expectations of a real-time detector of security-related issues. To address these limitations, we propose SEBERTIS, a framework to train Deep Neural Networks (DNNs) as classifiers independent of lexical cues, so that they can confidently detect fully unseen security-related issues. SEBERTIS capitalizes on fine-tuning bidirectional transformer architectures as Masked Language Models (MLMs) on a series of semantically equivalent vocabulary to prediction labels (which we call Semantic Surrogates) when they have been replaced with a mask. Our SEBERTIS-trained classifier achieves a 0.9880 F1-score in detecting security-related issues of a curated corpus of 10,000 GitHub issue reports, substantially outperforming state-of-the-art issue classifiers, with 14.44%-96.98%, 15.40%-93.07%, and 14.90%-94.72% higher detection precision, recall, and F1-score over ML-based baselines. Our classifier also substantially surpasses LLM baselines, with an improvement of 23.20%-63.71%, 36.68%-85.63%, and 39.49%-74.53% for precision, recall, and F1-score.
The Power of Types: Exploring the Impact of Type Checking on Neural Bug Detection in Dynamically Typed Languages
Nov 22, 2024



Motivation: Automated bug detection in dynamically typed languages such as Python is essential for maintaining code quality. The lack of mandatory type annotations in such languages can lead to errors that are challenging to identify early with traditional static analysis tools. Recent progress in deep neural networks has led to increased use of neural bug detectors. In statically typed languages, a type checker is integrated into the compiler and thus taken into consideration when the neural bug detector is designed for these languages. Problem: However, prior studies overlook this aspect during the training and testing of neural bug detectors for dynamically typed languages. When an optional type checker is used, assessing existing neural bug detectors on bugs easily detectable by type checkers may impact their performance estimation. Moreover, including these bugs in the training set of neural bug detectors can shift their detection focus toward the wrong type of bugs. Contribution: We explore the impact of type checking on various neural bug detectors for variable misuse bugs, a common type targeted by neural bug detectors. Existing synthetic and real-world datasets are type-checked to evaluate the prevalence of type-related bugs. Then, we investigate how type-related bugs influence the training and testing of the neural bug detectors. Findings: Our findings indicate that existing bug detection datasets contain a significant proportion of type-related bugs. Building on this insight, we discover integrating the neural bug detector with a type checker can be beneficial, especially when the code is annotated with types. Further investigation reveals neural bug detectors perform better on type-related bugs than other bugs. Moreover, removing type-related bugs from the training data helps improve neural bug detectors' ability to identify bugs beyond the scope of type checkers.
Certifying Robustness of Graph Convolutional Networks for Node Perturbation with Polyhedra Abstract Interpretation
May 14, 2024



Graph convolutional neural networks (GCNs) are powerful tools for learning graph-based knowledge representations from training data. However, they are vulnerable to small perturbations in the input graph, which makes them susceptible to input faults or adversarial attacks. This poses a significant problem for GCNs intended to be used in critical applications, which need to provide certifiably robust services even in the presence of adversarial perturbations. We propose an improved GCN robustness certification technique for node classification in the presence of node feature perturbations. We introduce a novel polyhedra-based abstract interpretation approach to tackle specific challenges of graph data and provide tight upper and lower bounds for the robustness of the GCN. Experiments show that our approach simultaneously improves the tightness of robustness bounds as well as the runtime performance of certification. Moreover, our method can be used during training to further improve the robustness of GCNs.
Prompting or Fine-tuning? A Comparative Study of Large Language Models for Taxonomy Construction
Sep 04, 2023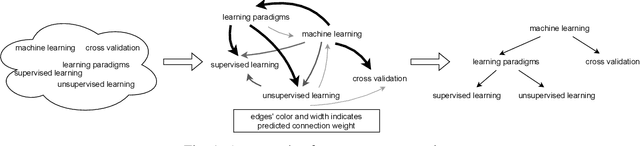
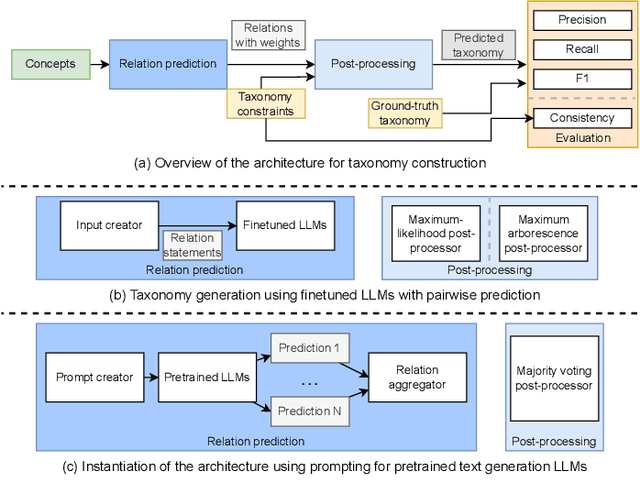


Taxonomies represent hierarchical relations between entities, frequently applied in various software modeling and natural language processing (NLP) activities. They are typically subject to a set of structural constraints restricting their content. However, manual taxonomy construction can be time-consuming, incomplete, and costly to maintain. Recent studies of large language models (LLMs) have demonstrated that appropriate user inputs (called prompting) can effectively guide LLMs, such as GPT-3, in diverse NLP tasks without explicit (re-)training. However, existing approaches for automated taxonomy construction typically involve fine-tuning a language model by adjusting model parameters. In this paper, we present a general framework for taxonomy construction that takes into account structural constraints. We subsequently conduct a systematic comparison between the prompting and fine-tuning approaches performed on a hypernym taxonomy and a novel computer science taxonomy dataset. Our result reveals the following: (1) Even without explicit training on the dataset, the prompting approach outperforms fine-tuning-based approaches. Moreover, the performance gap between prompting and fine-tuning widens when the training dataset is small. However, (2) taxonomies generated by the fine-tuning approach can be easily post-processed to satisfy all the constraints, whereas handling violations of the taxonomies produced by the prompting approach can be challenging. These evaluation findings provide guidance on selecting the appropriate method for taxonomy construction and highlight potential enhancements for both approaches.
Towards Improving the Explainability of Text-based Information Retrieval with Knowledge Graphs
Jan 17, 2023



Thanks to recent advancements in machine learning, vector-based methods have been adopted in many modern information retrieval (IR) systems. While showing promising retrieval performance, these approaches typically fail to explain why a particular document is retrieved as a query result to address explainable information retrieval(XIR). Knowledge graphs record structured information about entities and inherently explainable relationships. Most of existing XIR approaches focus exclusively on the retrieval model with little consideration on using existing knowledge graphs for providing an explanation. In this paper, we propose a general architecture to incorporate knowledge graphs for XIR in various steps of the retrieval process. Furthermore, we create two instances of the architecture for different types of explanation. We evaluate our approaches on well-known IR benchmarks using standard metrics and compare them with vector-based methods as baselines.