 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting or Fine-tuning? A Comparative Study of Large Language Models for Taxonomy Construction
Sep 04, 2023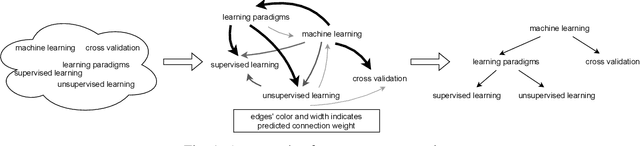
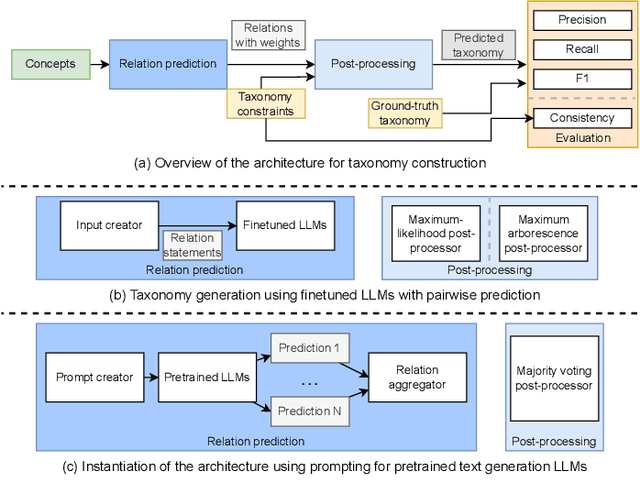


Taxonomies represent hierarchical relations between entities, frequently applied in various software modeling and natural language processing (NLP) activities. They are typically subject to a set of structural constraints restricting their content. However, manual taxonomy construction can be time-consuming, incomplete, and costly to maintain. Recent studies of large language models (LLMs) have demonstrated that appropriate user inputs (called prompting) can effectively guide LLMs, such as GPT-3, in diverse NLP tasks without explicit (re-)training. However, existing approaches for automated taxonomy construction typically involve fine-tuning a language model by adjusting model parameters. In this paper, we present a general framework for taxonomy construction that takes into account structural constraints. We subsequently conduct a systematic comparison between the prompting and fine-tuning approaches performed on a hypernym taxonomy and a novel computer science taxonomy dataset. Our result reveals the following: (1) Even without explicit training on the dataset, the prompting approach outperforms fine-tuning-based approaches. Moreover, the performance gap between prompting and fine-tuning widens when the training dataset is small. However, (2) taxonomies generated by the fine-tuning approach can be easily post-processed to satisfy all the constraints, whereas handling violations of the taxonomies produced by the prompting approach can be challenging. These evaluation findings provide guidance on selecting the appropriate method for taxonomy construction and highlight potential enhancements for both approaches.