 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLength independent generalization bounds for deep SSM architectures with stability constraints
May 30, 2024
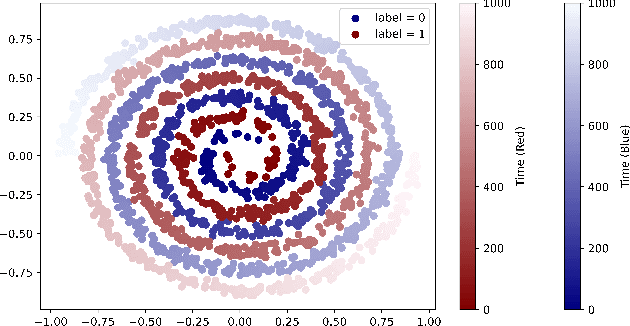
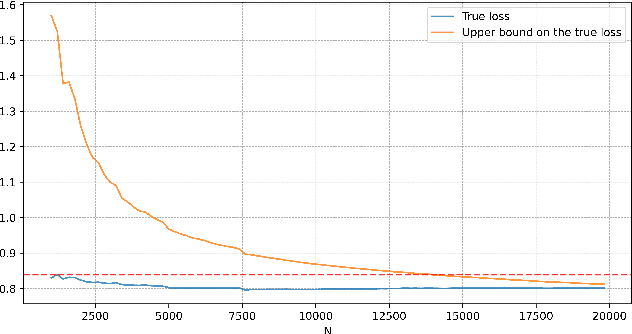
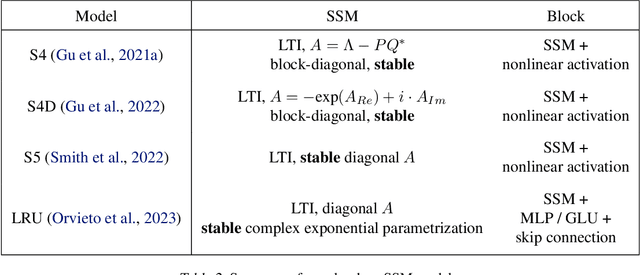
Many state-of-the-art models trained on long-range sequences, for example S4, S5 or LRU, are made of sequential blocks combining State-Space Models (SSMs) with neural networks. In this paper we provide a PAC bound that holds for these kind of architectures with stable SSM blocks and does not depend on the length of the input sequence. Imposing stability of the SSM blocks is a standard practice in the literature, and it is known to help performance. Our results provide a theoretical justification for the use of stable SSM blocks as the proposed PAC bound decreases as the degree of stability of the SSM blocks increases.
Optimization dependent generalization bound for ReLU networks based on sensitivity in the tangent bundle
Oct 26, 2023Recent advances in deep learning have given us some very promising results on the generalization ability of deep neural networks, however literature still lacks a comprehensive theory explaining why heavily over-parametrized models are able to generalize well while fitting the training data. In this paper we propose a PAC type bound on the generalization error of feedforward ReLU networks via estimating the Rademacher complexity of the set of networks available from an initial parameter vector via gradient descent. The key idea is to bound the sensitivity of the network's gradient to perturbation of the input data along the optimization trajectory. The obtained bound does not explicitly depend on the depth of the network. Our results are experimentally verified on the MNIST and CIFAR-10 datasets.
PAC bounds of continuous Linear Parameter-Varying systems related to neural ODEs
Jul 07, 2023We consider the problem of learning Neural Ordinary Differential Equations (neural ODEs) within the context of Linear Parameter-Varying (LPV) systems in continuous-time. LPV systems contain bilinear systems which are known to be universal approximators for non-linear systems. Moreover, a large class of neural ODEs can be embedded into LPV systems. As our main contribution we provide Probably Approximately Correct (PAC) bounds under stability for LPV systems related to neural ODEs. The resulting bounds have the advantage that they do not depend on the integration interval.
Gradient representations in ReLU networks as similarity functions
Oct 26, 2021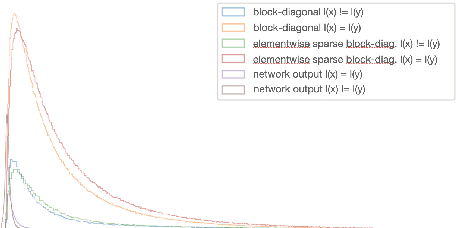
Feed-forward networks can be interpreted as mappings with linear decision surfaces at the level of the last layer. We investigate how the tangent space of the network can be exploited to refine the decision in case of ReLU (Rectified Linear Unit) activations. We show that a simple Riemannian metric parametrized on the parameters of the network forms a similarity function at least as good as the original network and we suggest a sparse metric to increase the similarity gap.