 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesostructures: Beyond Spectrogram Loss in Differentiable Time-Frequency Analysis
Jan 24, 2023



Computer musicians refer to mesostructures as the intermediate levels of articulation between the microstructure of waveshapes and the macrostructure of musical forms. Examples of mesostructures include melody, arpeggios, syncopation, polyphonic grouping, and textural contrast. Despite their central role in musical expression, they have received limited attention in deep learning. Currently, autoencoders and neural audio synthesizers are only trained and evaluated at the scale of microstructure: i.e., local amplitude variations up to 100 milliseconds or so. In this paper, we formulate and address the problem of mesostructural audio modeling via a composition of a differentiable arpeggiator and time-frequency scattering. We empirically demonstrate that time--frequency scattering serves as a differentiable model of similarity between synthesis parameters that govern mesostructure. By exposing the sensitivity of short-time spectral distances to time alignment, we motivate the need for a time-invariant and multiscale differentiable time--frequency model of similarity at the level of both local spectra and spectrotemporal modulations.
Differentiable Time-Frequency Scattering in Kymatio
Apr 19, 2022



Joint time-frequency scattering (JTFS) is a convolutional operator in the time-frequency domain which extracts spectrotemporal modulations at various rates and scales. It offers an idealized model of spectrotemporal receptive fields (STRF) in the primary auditory cortex, and thus may serve as a biological plausible surrogate for human perceptual judgments at the scale of isolated audio events. Yet, prior implementations of JTFS and STRF have remained outside of the standard toolkit of perceptual similarity measures and evaluation methods for audio generation. We trace this issue down to three limitations: differentiability, speed, and flexibility. In this paper, we present an implementation of time-frequency scattering in Kymatio, an open-source Python package for scattering transforms. Unlike prior implementations, Kymatio accommodates NumPy and PyTorch as backends and is thus portable on both CPU and GPU. We demonstrate the usefulness of JTFS in Kymatio via three applications: unsupervised manifold learning of spectrotemporal modulations, supervised classification of musical instruments, and texture resynthesis of bioacoustic sounds.
A Modulation Front-End for Music Audio Tagging
May 25, 2021
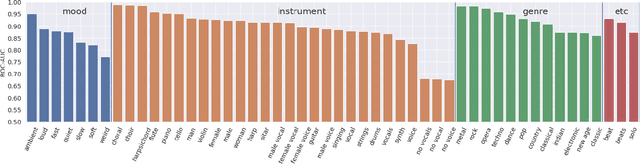
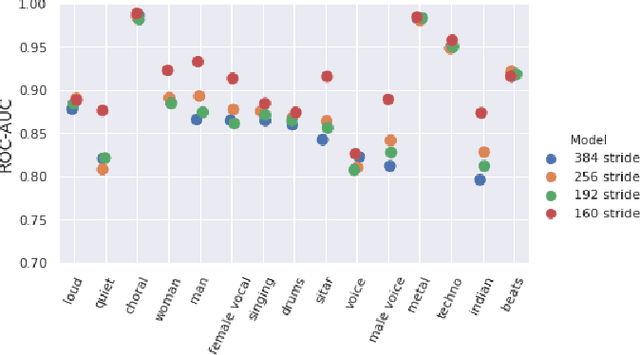
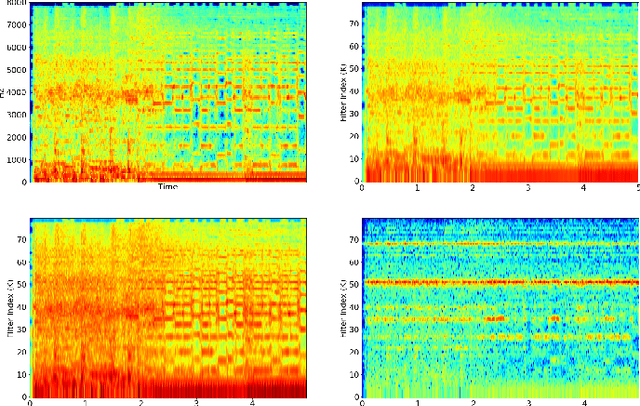
Convolutional Neural Networks have been extensively explored in the task of automatic music tagging. The problem can be approached by using either engineered time-frequency features or raw audio as input. Modulation filter bank representations that have been actively researched as a basis for timbre perception have the potential to facilitate the extraction of perceptually salient features. We explore end-to-end learned front-ends for audio representation learning, ModNet and SincModNet, that incorporate a temporal modulation processing block. The structure is effectively analogous to a modulation filter bank, where the FIR filter center frequencies are learned in a data-driven manner. The expectation is that a perceptually motivated filter bank can provide a useful representation for identifying music features. Our experimental results provide a fully visualisable and interpretable front-end temporal modulation decomposition of raw audio. We evaluate the performance of our model against the state-of-the-art of music tagging on the MagnaTagATune dataset. We analyse the impact on performance for particular tags when time-frequency bands are subsampled by the modulation filters at a progressively reduced rate. We demonstrate that modulation filtering provides promising results for music tagging and feature representation, without using extensive musical domain knowledge in the design of this front-end.