 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAVE for Speech: Efficient Voice Conversion at High Sampling Rates
Aug 29, 2024



Voice conversion has gained increasing popularity within the field of audio manipulation and speech synthesis. Often, the main objective is to transfer the input identity to that of a target speaker without changing its linguistic content. While current work provides high-fidelity solutions they rarely focus on model simplicity, high-sampling rate environments or stream-ability. By incorporating speech representation learning into a generative timbre transfer model, traditionally created for musical purposes, we investigate the realm of voice conversion generated directly in the time domain at high sampling rates. More specifically, we guide the latent space of a baseline model towards linguistically relevant representations and condition it on external speaker information. Through objective and subjective assessments, we demonstrate that the proposed solution can attain levels of naturalness, quality, and intelligibility comparable to those of a state-of-the-art solution for seen speakers, while significantly decreasing inference time. However, despite the presence of target speaker characteristics in the converted output, the actual similarity to unseen speakers remains a challenge.
Reimagining Speech: A Scoping Review of Deep Learning-Powered Voice Conversion
Nov 14, 2023Research on deep learning-powered voice conversion (VC) in speech-to-speech scenarios is getting increasingly popular. Although many of the works in the field of voice conversion share a common global pipeline, there is a considerable diversity in the underlying structures, methods, and neural sub-blocks used across research efforts. Thus, obtaining a comprehensive understanding of the reasons behind the choice of the different methods in the voice conversion pipeline can be challenging, and the actual hurdles in the proposed solutions are often unclear. To shed light on these aspects, this paper presents a scoping review that explores the use of deep learning in speech analysis, synthesis, and disentangled speech representation learning within modern voice conversion systems. We screened 621 publications from more than 38 different venues between the years 2017 and 2023, followed by an in-depth review of a final database consisting of 123 eligible studies. Based on the review, we summarise the most frequently used approaches to voice conversion based on deep learning and highlight common pitfalls within the community. Lastly, we condense the knowledge gathered, identify main challenges and provide recommendations for future research directions.
Vocal Timbre Effects with Differentiable Digital Signal Processing
Jun 19, 2023We explore two approaches to creatively altering vocal timbre using Differentiable Digital Signal Processing (DDSP). The first approach is inspired by classic cross-synthesis techniques. A pretrained DDSP decoder predicts a filter for a noise source and a harmonic distribution, based on pitch and loudness information extracted from the vocal input. Before synthesis, the harmonic distribution is modified by interpolating between the predicted distribution and the harmonics of the input. We provide a real-time implementation of this approach in the form of a Neutone model. In the second approach, autoencoder models are trained on datasets consisting of both vocal and instrument training data. To apply the effect, the trained autoencoder attempts to reconstruct the vocal input. We find that there is a desirable "sweet spot" during training, where the model has learned to reconstruct the phonetic content of the input vocals, but is still affected by the timbre of the instrument mixed into the training data. After further training, that effect disappears. A perceptual evaluation compares the two approaches. We find that the autoencoder in the second approach is able to reconstruct intelligible lyrical content without any explicit phonetic information provided during training.
Differentiable Allpass Filters for Phase Response Estimation and Automatic Signal Alignment
Jun 02, 2023



Virtual analog (VA) audio effects are increasingly based on neural networks and deep learning frameworks. Due to the underlying black-box methodology, a successful model will learn to approximate the data it is presented, including potential errors such as latency and audio dropouts as well as non-linear characteristics and frequency-dependent phase shifts produced by the hardware. The latter is of particular interest as the learned phase-response might cause unwanted audible artifacts when the effect is used for creative processing techniques such as dry-wet mixing or parallel compression. To overcome these artifacts we propose differentiable signal processing tools and deep optimization structures for automatically tuning all-pass filters to predict the phase response of different VA simulations, and align processed signals that are out of phase. The approaches are assessed using objective metrics while listening tests evaluate their ability to enhance the quality of parallel path processing techniques. Ultimately, an over-parameterized, BiasNet-based, all-pass model is proposed for the optimization problem under consideration, resulting in models that can estimate all-pass filter coefficients to align a dry signal with its affected, wet, equivalent.
Real-time Timbre Transfer and Sound Synthesis using DDSP
Mar 12, 2021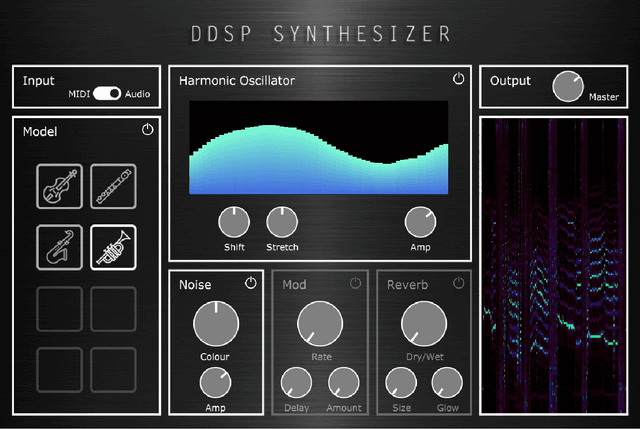
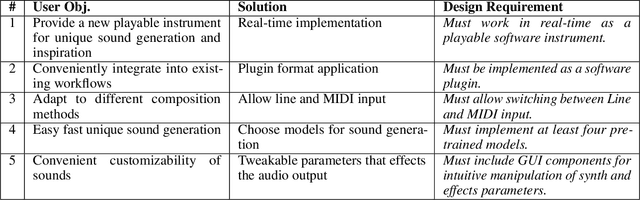
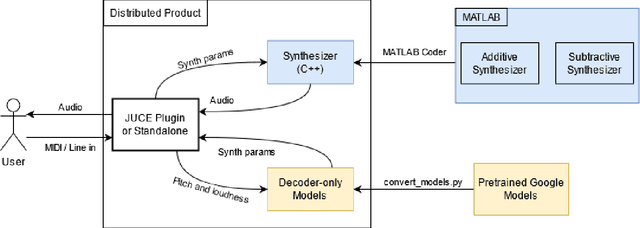
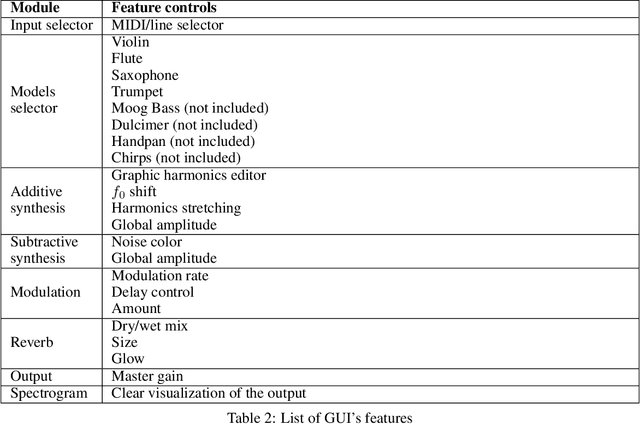
Neural audio synthesis is an actively researched topic, having yielded a wide range of techniques that leverages machine learning architectures. Google Magenta elaborated a novel approach called Differential Digital Signal Processing (DDSP) that incorporates deep neural networks with preconditioned digital signal processing techniques, reaching state-of-the-art results especially in timbre transfer applications. However, most of these techniques, including the DDSP, are generally not applicable in real-time constraints, making them ineligible in a musical workflow. In this paper, we present a real-time implementation of the DDSP library embedded in a virtual synthesizer as a plug-in that can be used in a Digital Audio Workstation. We focused on timbre transfer from learned representations of real instruments to arbitrary sound inputs as well as controlling these models by MIDI. Furthermore, we developed a GUI for intuitive high-level controls which can be used for post-processing and manipulating the parameters estimated by the neural network. We have conducted a user experience test with seven participants online. The results indicated that our users found the interface appealing, easy to understand, and worth exploring further. At the same time, we have identified issues in the timbre transfer quality, in some components we did not implement, and in installation and distribution of our plugin. The next iteration of our design will address these issues. Our real-time MATLAB and JUCE implementations are available at https://github.com/SMC704/juce-ddsp and https://github.com/SMC704/matlab-ddsp , respectively.
Latent Space Explorations of Singing Voice Synthesis using DDSP
Mar 12, 2021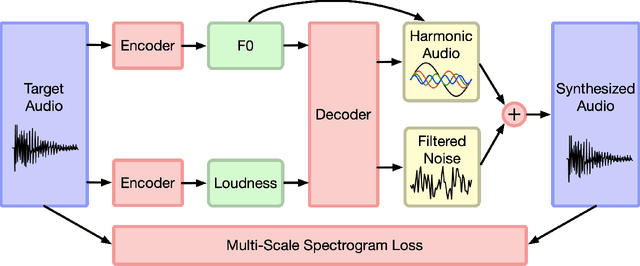

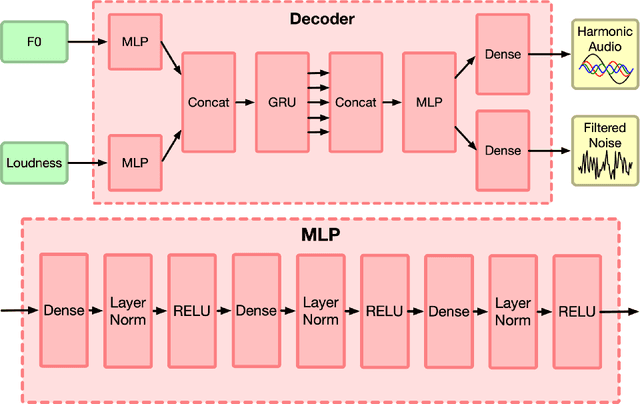

Machine learning based singing voice models require large datasets and lengthy training times. In this work we present a lightweight architecture, based on the Differentiable Digital Signal Processing (DDSP) library, that is able to output song-like utterances conditioned only on pitch and amplitude, after twelve hours of training using small datasets of unprocessed audio. The results are promising, as both the melody and the singer's voice are recognizable. In addition, we present two zero-configuration tools to train new models and experiment with them. Currently we are exploring the latent space representation, which is included in the DDSP library, but not in the original DDSP examples. Our results indicate that the latent space improves both the identification of the singer as well as the comprehension of the lyrics. Our code is available at https://github.com/juanalonso/DDSP-singing-experiments with links to the zero-configuration notebooks, and our sound examples are at https://juanalonso.github.io/DDSP-singing-experiments/ .