 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReimagining Speech: A Scoping Review of Deep Learning-Powered Voice Conversion
Nov 14, 2023Research on deep learning-powered voice conversion (VC) in speech-to-speech scenarios is getting increasingly popular. Although many of the works in the field of voice conversion share a common global pipeline, there is a considerable diversity in the underlying structures, methods, and neural sub-blocks used across research efforts. Thus, obtaining a comprehensive understanding of the reasons behind the choice of the different methods in the voice conversion pipeline can be challenging, and the actual hurdles in the proposed solutions are often unclear. To shed light on these aspects, this paper presents a scoping review that explores the use of deep learning in speech analysis, synthesis, and disentangled speech representation learning within modern voice conversion systems. We screened 621 publications from more than 38 different venues between the years 2017 and 2023, followed by an in-depth review of a final database consisting of 123 eligible studies. Based on the review, we summarise the most frequently used approaches to voice conversion based on deep learning and highlight common pitfalls within the community. Lastly, we condense the knowledge gathered, identify main challenges and provide recommendations for future research directions.
Differentiable Allpass Filters for Phase Response Estimation and Automatic Signal Alignment
Jun 02, 2023



Virtual analog (VA) audio effects are increasingly based on neural networks and deep learning frameworks. Due to the underlying black-box methodology, a successful model will learn to approximate the data it is presented, including potential errors such as latency and audio dropouts as well as non-linear characteristics and frequency-dependent phase shifts produced by the hardware. The latter is of particular interest as the learned phase-response might cause unwanted audible artifacts when the effect is used for creative processing techniques such as dry-wet mixing or parallel compression. To overcome these artifacts we propose differentiable signal processing tools and deep optimization structures for automatically tuning all-pass filters to predict the phase response of different VA simulations, and align processed signals that are out of phase. The approaches are assessed using objective metrics while listening tests evaluate their ability to enhance the quality of parallel path processing techniques. Ultimately, an over-parameterized, BiasNet-based, all-pass model is proposed for the optimization problem under consideration, resulting in models that can estimate all-pass filter coefficients to align a dry signal with its affected, wet, equivalent.
Sonic Interactions in Virtual Environments: the Egocentric Audio Perspective of the Digital Twin
Apr 21, 2022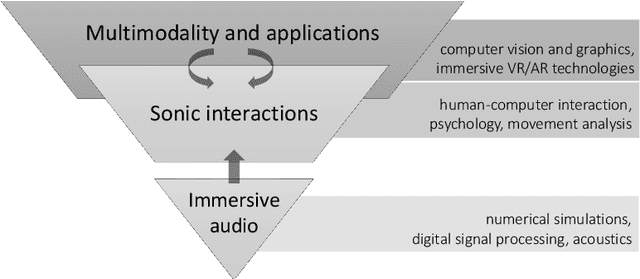

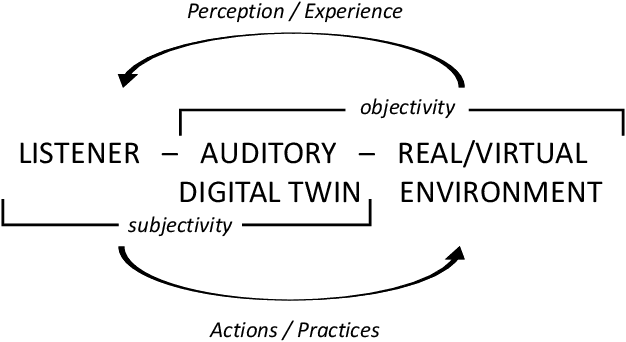
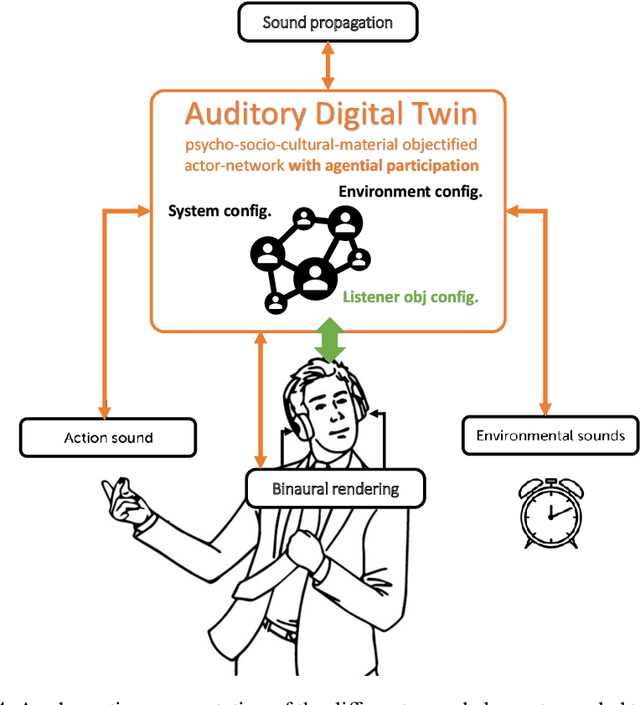
The relationships between the listener, physical world and virtual environment (VE) should not only inspire the design of natural multimodal interfaces but should be discovered to make sense of the mediating action of VR technologies. This chapter aims to transform an archipelago of studies related to sonic interactions in virtual environments (SIVE) into a research field equipped with a first theoretical framework with an inclusive vision of the challenges to come: the egocentric perspective of the auditory digital twin. In a VE with immersive audio technologies implemented, the role of VR simulations must be enacted by a participatory exploration of sense-making in a network of human and non-human agents, called actors. The guardian of such locus of agency is the auditory digital twin that fosters intra-actions between humans and technology, dynamically and fluidly redefining all those configurations that are crucial for an immersive and coherent experience. The idea of entanglement theory is here mainly declined in an egocentric-spatial perspective related to emerging knowledge of the listener's perceptual capabilities. This is an actively transformative relation with the digital twin potentials to create movement, transparency, and provocative activities in VEs. The chapter contains an original theoretical perspective complemented by several bibliographical references and links to the other book chapters that have contributed significantly to the proposal presented here.