 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Space Explorations of Singing Voice Synthesis using DDSP
Paper and Code
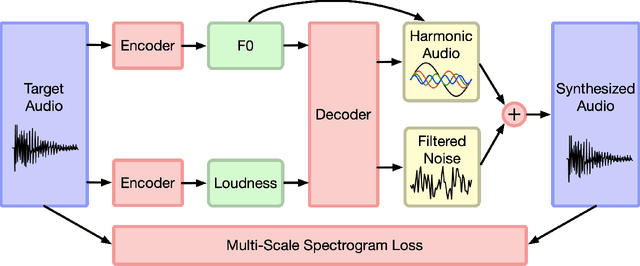

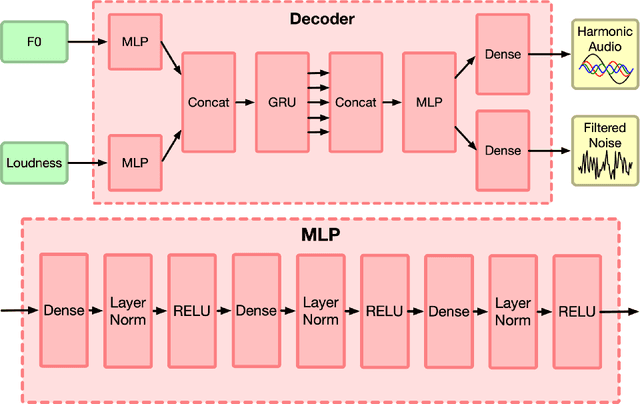

Machine learning based singing voice models require large datasets and lengthy training times. In this work we present a lightweight architecture, based on the Differentiable Digital Signal Processing (DDSP) library, that is able to output song-like utterances conditioned only on pitch and amplitude, after twelve hours of training using small datasets of unprocessed audio. The results are promising, as both the melody and the singer's voice are recognizable. In addition, we present two zero-configuration tools to train new models and experiment with them. Currently we are exploring the latent space representation, which is included in the DDSP library, but not in the original DDSP examples. Our results indicate that the latent space improves both the identification of the singer as well as the comprehension of the lyrics. Our code is available at https://github.com/juanalonso/DDSP-singing-experiments with links to the zero-configuration notebooks, and our sound examples are at https://juanalonso.github.io/DDSP-singing-experiments/ .