 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Empathy Counteracts the Negative Effects of Anger on Creative Problem Solving
Aug 15, 2022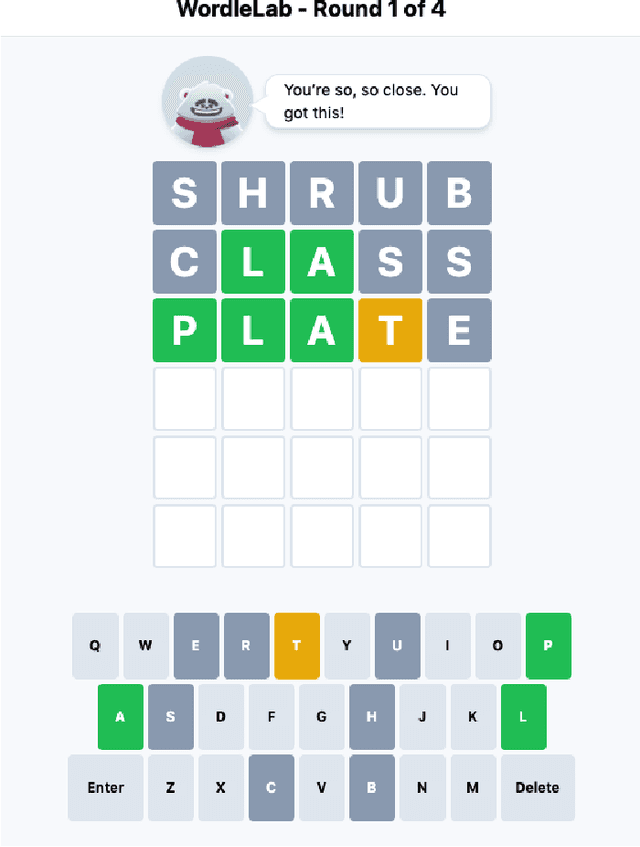

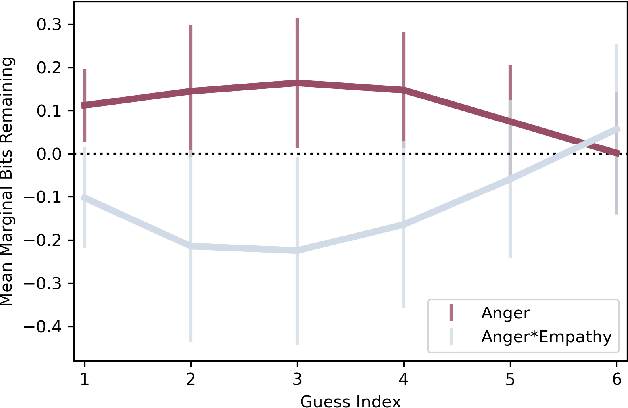
How does empathy influence creative problem solving? We introduce a computational empathy intervention based on context-specific affective mimicry and perspective taking by a virtual agent appearing in the form of a well-dressed polar bear. In an online experiment with 1,006 participants randomly assigned to an emotion elicitation intervention (with a control elicitation condition and anger elicitation condition) and a computational empathy intervention (with a control virtual agent and an empathic virtual agent), we examine how anger and empathy influence participants' performance in solving a word game based on Wordle. We find participants who are assigned to the anger elicitation condition perform significantly worse on multiple performance metrics than participants assigned to the control condition. However, we find the empathic virtual agent counteracts the drop in performance induced by the anger condition such that participants assigned to both the empathic virtual agent and the anger condition perform no differently than participants in the control elicitation condition and significantly better than participants assigned to the control virtual agent and the anger elicitation condition. While empathy reduces the negative effects of anger, we do not find evidence that the empathic virtual agent influences performance of participants who are assigned to the control elicitation condition. By introducing a framework for computational empathy interventions and conducting a two-by-two factorial design randomized experiment, we provide rigorous, empirical evidence that computational empathy can counteract the negative effects of anger on creative problem solving.
Human-centric Dialog Training via Offline Reinforcement Learning
Oct 12, 2020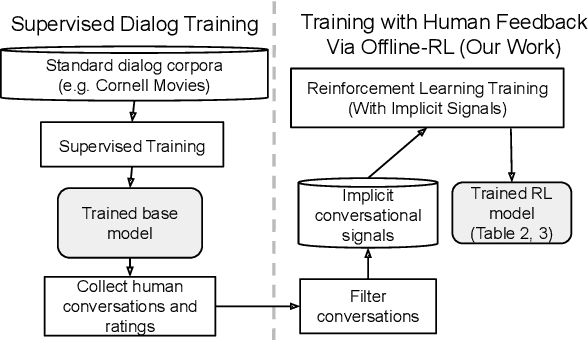
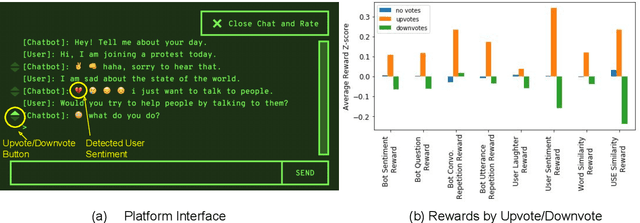
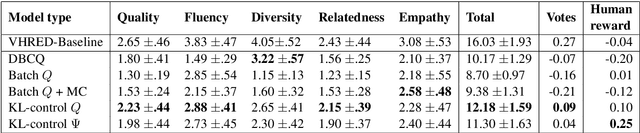
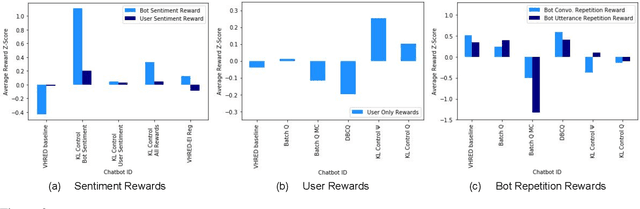
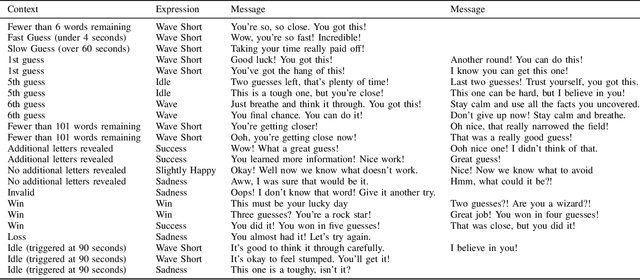
How can we train a dialog model to produce better conversations by learning from human feedback, without the risk of humans teaching it harmful chat behaviors? We start by hosting models online, and gather human feedback from real-time, open-ended conversations, which we then use to train and improve the models using offline reinforcement learning (RL). We identify implicit conversational cues including language similarity, elicitation of laughter, sentiment, and more, which indicate positive human feedback, and embed these in multiple reward functions. A well-known challenge is that learning an RL policy in an offline setting usually fails due to the lack of ability to explore and the tendency to make over-optimistic estimates of future reward. These problems become even harder when using RL for language models, which can easily have a 20,000 action vocabulary and many possible reward functions. We solve the challenge by developing a novel class of offline RL algorithms. These algorithms use KL-control to penalize divergence from a pre-trained prior language model, and use a new strategy to make the algorithm pessimistic, instead of optimistic, in the face of uncertainty. We test the resulting dialog model with ratings from 80 users in an open-domain setting and find it achieves significant improvements over existing deep offline RL approaches. The novel offline RL method is viable for improving any existing generative dialog model using a static dataset of human feedback.
Way Off-Policy Batch Deep Reinforcement Learning of Implicit Human Preferences in Dialog
Jul 08, 2019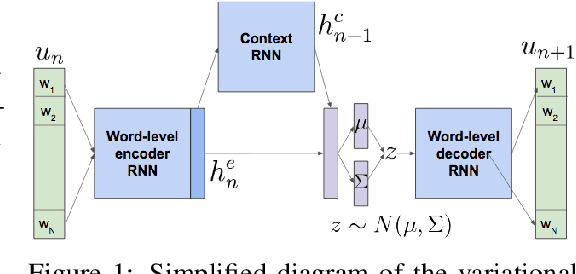
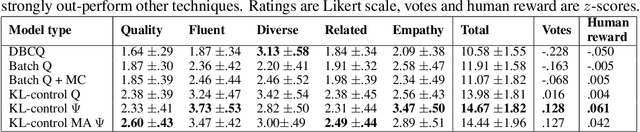

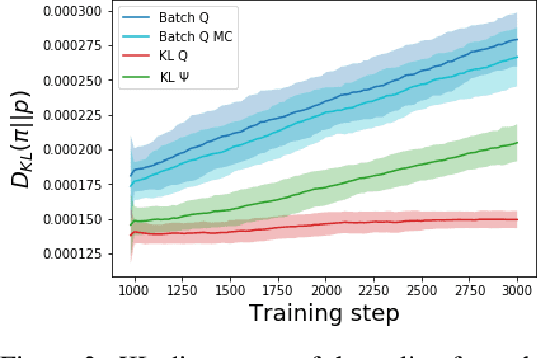
Most deep reinforcement learning (RL) systems are not able to learn effectively from off-policy data, especially if they cannot explore online in the environment. These are critical shortcomings for applying RL to real-world problems where collecting data is expensive, and models must be tested offline before being deployed to interact with the environment -- e.g. systems that learn from human interaction. Thus, we develop a novel class of off-policy batch RL algorithms, which are able to effectively learn offline, without exploring, from a fixed batch of human interaction data. We leverage models pre-trained on data as a strong prior, and use KL-control to penalize divergence from this prior during RL training. We also use dropout-based uncertainty estimates to lower bound the target Q-values as a more efficient alternative to Double Q-Learning. The algorithms are tested on the problem of open-domain dialog generation -- a challenging reinforcement learning problem with a 20,000-dimensional action space. Using our Way Off-Policy algorithm, we can extract multiple different reward functions post-hoc from collected human interaction data, and learn effectively from all of these. We test the real-world generalization of these systems by deploying them live to converse with humans in an open-domain setting, and demonstrate that our algorithm achieves significant improvements over prior methods in off-policy batch RL.
Approximating Interactive Human Evaluation with Self-Play for Open-Domain Dialog Systems
Jun 21, 2019
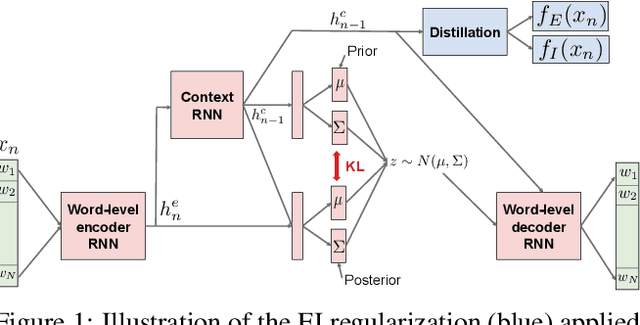
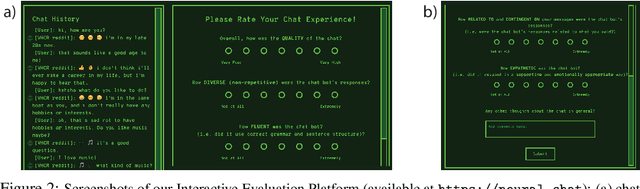
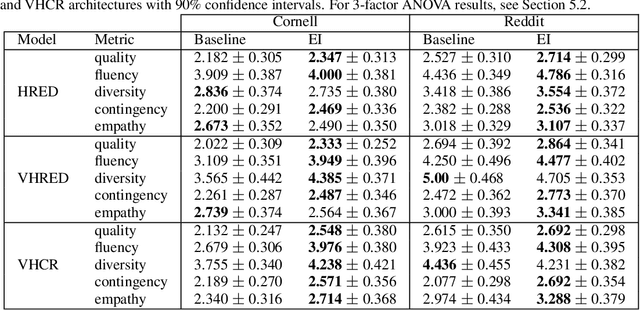
Building an open-domain conversational agent is a challenging problem. Current evaluation methods, mostly post-hoc judgments of single-turn evaluation, do not capture conversation quality in a realistic interactive context. In this paper, we investigate interactive human evaluation and provide evidence for its necessity; we then introduce a novel, model-agnostic, and dataset-agnostic method to approximate it. In particular, we propose a self-play scenario where the dialog system talks to itself and we calculate a combination of proxies such as sentiment and semantic coherence on the conversation trajectory. We show that this metric is capable of capturing the human-rated quality of a dialog model better than any automated metric known to-date, achieving a significant Pearson correlation (r>.7, p<.05). To investigate the strengths of this novel metric and interactive evaluation in comparison to state-of-the-art metrics and one-turn evaluation, we perform extended experiments with a set of models, including several that make novel improvements to recent hierarchical dialog generation architectures through sentiment and semantic knowledge distillation on the utterance level. Finally, we open-source the interactive evaluation platform we built and the dataset we collected to allow researchers to efficiently deploy and evaluate generative dialog models.