 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixels and Predictions: Potential of GPT-4V in Meteorological Imagery Analysis and Forecast Communication
Apr 22, 2024Generative AI, such as OpenAI's GPT-4V large-language model, has rapidly entered mainstream discourse. Novel capabilities in image processing and natural-language communication may augment existing forecasting methods. Large language models further display potential to better communicate weather hazards in a style honed for diverse communities and different languages. This study evaluates GPT-4V's ability to interpret meteorological charts and communicate weather hazards appropriately to the user, despite challenges of hallucinations, where generative AI delivers coherent, confident, but incorrect responses. We assess GPT-4V's competence via its web interface ChatGPT in two tasks: (1) generating a severe-weather outlook from weather-chart analysis and conducting self-evaluation, revealing an outlook that corresponds well with a Storm Prediction Center human-issued forecast; and (2) producing hazard summaries in Spanish and English from weather charts. Responses in Spanish, however, resemble direct (not idiomatic) translations from English to Spanish, yielding poorly translated summaries that lose critical idiomatic precision required for optimal communication. Our findings advocate for cautious integration of tools like GPT-4V in meteorology, underscoring the necessity of human oversight and development of trustworthy, explainable AI.
Using Machine Learning to Calibrate Storm-Scale Probabilistic Guidance of Severe Weather Hazards in the Warn-on-Forecast System
Nov 12, 2020
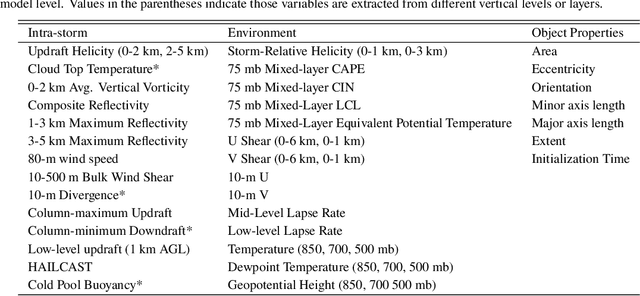
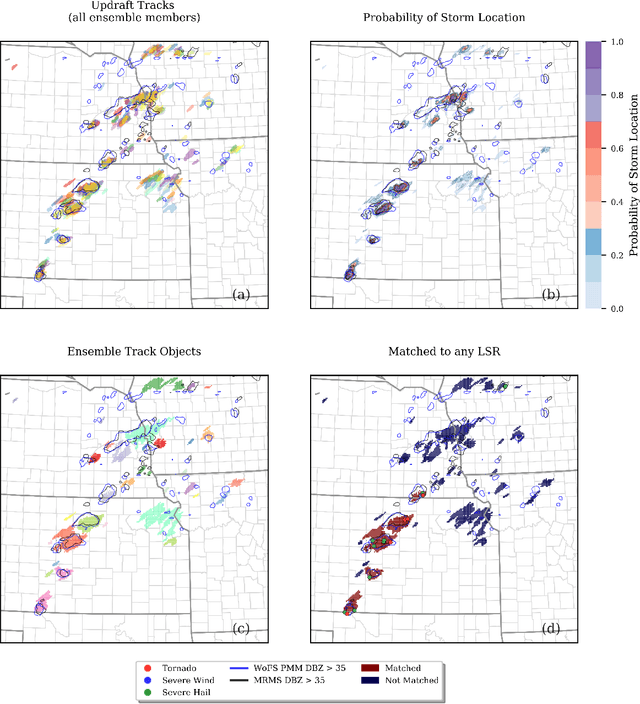
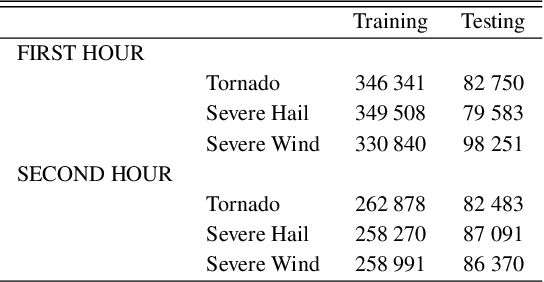
A primary goal of the National Oceanic and Atmospheric Administration (NOAA) Warn-on-Forecast (WoF) project is to provide rapidly updating probabilistic guidance to human forecasters for short-term (e.g., 0-3 h) severe weather forecasts. Maximizing the usefulness of probabilistic severe weather guidance from an ensemble of convection-allowing model forecasts requires calibration. In this study, we compare the skill of a simple method using updraft helicity against a series of machine learning (ML) algorithms for calibrating WoFS severe weather guidance. ML models are often used to calibrate severe weather guidance since they leverage multiple variables and discover useful patterns in complex datasets. \indent Our dataset includes WoF System (WoFS) ensemble forecasts available every 5 minutes out to 150 min of lead time from the 2017-2019 NOAA Hazardous Weather Testbed Spring Forecasting Experiments (81 dates). Using a novel ensemble storm track identification method, we extracted three sets of predictors from the WoFS forecasts: intra-storm state variables, near-storm environment variables, and morphological attributes of the ensemble storm tracks. We then trained random forests, gradient-boosted trees, and logistic regression algorithms to predict which WoFS 30-min ensemble storm tracks will correspond to a tornado, severe hail, and/or severe wind report. For the simple method, we extracted the ensemble probability of 2-5 km updraft helicity (UH) exceeding a threshold (tuned per severe weather hazard) from each ensemble storm track. The three ML algorithms discriminated well for all three hazards and produced more reliable probabilities than the UH-based predictions. Overall, the results suggest that ML-based calibrations of dynamical ensemble output can improve short term, storm-scale severe weather probabilistic guidance