 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Explanation Methods for Traditional Machine Learning Models Part 2: Quantifying Model Explainability Faithfulness and Improvements with Dimensionality Reduction
Nov 18, 2022Machine learning (ML) models are becoming increasingly common in the atmospheric science community with a wide range of applications. To enable users to understand what an ML model has learned, ML explainability has become a field of active research. In Part I of this two-part study, we described several explainability methods and demonstrated that feature rankings from different methods can substantially disagree with each other. It is unclear, though, whether the disagreement is overinflated due to some methods being less faithful in assigning importance. Herein, "faithfulness" or "fidelity" refer to the correspondence between the assigned feature importance and the contribution of the feature to model performance. In the present study, we evaluate the faithfulness of feature ranking methods using multiple methods. Given the sensitivity of explanation methods to feature correlations, we also quantify how much explainability faithfulness improves after correlated features are limited. Before dimensionality reduction, the feature relevance methods [e.g., SHAP, LIME, ALE variance, and logistic regression (LR) coefficients] were generally more faithful than the permutation importance methods due to the negative impact of correlated features. Once correlated features were reduced, traditional permutation importance became the most faithful method. In addition, the ranking uncertainty (i.e., the spread in rank assigned to a feature by the different ranking methods) was reduced by a factor of 2-10, and excluding less faithful feature ranking methods reduces it further. This study is one of the first to quantify the improvement in explainability from limiting correlated features and knowing the relative fidelity of different explainability methods.
Comparing Explanation Methods for Traditional Machine Learning Models Part 1: An Overview of Current Methods and Quantifying Their Disagreement
Nov 16, 2022With increasing interest in explaining machine learning (ML) models, the first part of this two-part study synthesizes recent research on methods for explaining global and local aspects of ML models. This study distinguishes explainability from interpretability, local from global explainability, and feature importance versus feature relevance. We demonstrate and visualize different explanation methods, how to interpret them, and provide a complete Python package (scikit-explain) to allow future researchers to explore these products. We also highlight the frequent disagreement between explanation methods for feature rankings and feature effects and provide practical advice for dealing with these disagreements. We used ML models developed for severe weather prediction and sub-freezing road surface temperature prediction to generalize the behavior of the different explanation methods. For feature rankings, there is substantially more agreement on the set of top features (e.g., on average, two methods agree on 6 of the top 10 features) than on specific rankings (on average, two methods only agree on the ranks of 2-3 features in the set of top 10 features). On the other hand, two feature effect curves from different methods are in high agreement as long as the phase space is well sampled. Finally, a lesser-known method, tree interpreter, was found comparable to SHAP for feature effects, and with the widespread use of random forests in geosciences and computational ease of tree interpreter, we recommend it be explored in future research.
Using Machine Learning to Calibrate Storm-Scale Probabilistic Guidance of Severe Weather Hazards in the Warn-on-Forecast System
Nov 12, 2020
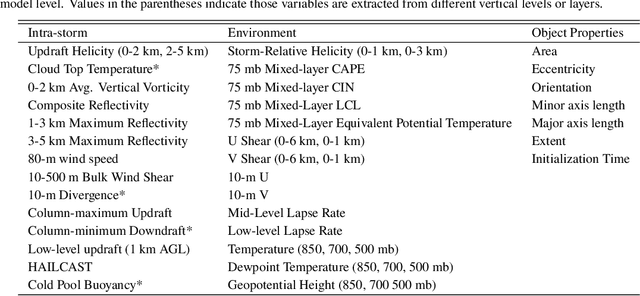
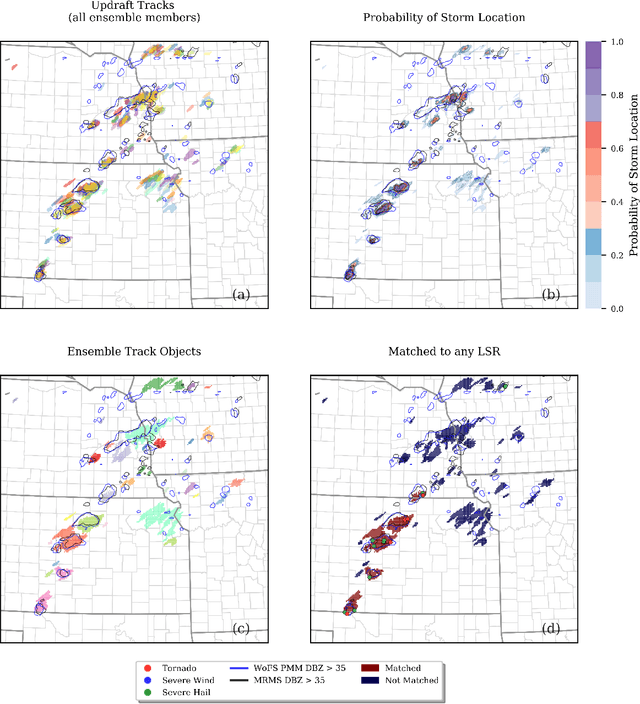
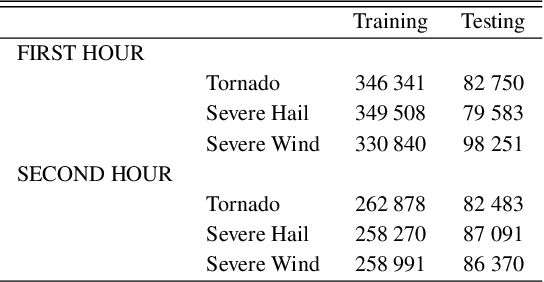
A primary goal of the National Oceanic and Atmospheric Administration (NOAA) Warn-on-Forecast (WoF) project is to provide rapidly updating probabilistic guidance to human forecasters for short-term (e.g., 0-3 h) severe weather forecasts. Maximizing the usefulness of probabilistic severe weather guidance from an ensemble of convection-allowing model forecasts requires calibration. In this study, we compare the skill of a simple method using updraft helicity against a series of machine learning (ML) algorithms for calibrating WoFS severe weather guidance. ML models are often used to calibrate severe weather guidance since they leverage multiple variables and discover useful patterns in complex datasets. \indent Our dataset includes WoF System (WoFS) ensemble forecasts available every 5 minutes out to 150 min of lead time from the 2017-2019 NOAA Hazardous Weather Testbed Spring Forecasting Experiments (81 dates). Using a novel ensemble storm track identification method, we extracted three sets of predictors from the WoFS forecasts: intra-storm state variables, near-storm environment variables, and morphological attributes of the ensemble storm tracks. We then trained random forests, gradient-boosted trees, and logistic regression algorithms to predict which WoFS 30-min ensemble storm tracks will correspond to a tornado, severe hail, and/or severe wind report. For the simple method, we extracted the ensemble probability of 2-5 km updraft helicity (UH) exceeding a threshold (tuned per severe weather hazard) from each ensemble storm track. The three ML algorithms discriminated well for all three hazards and produced more reliable probabilities than the UH-based predictions. Overall, the results suggest that ML-based calibrations of dynamical ensemble output can improve short term, storm-scale severe weather probabilistic guidance