 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage, Word and Thought: A More Challenging Language Task for the Iterated Learning Model
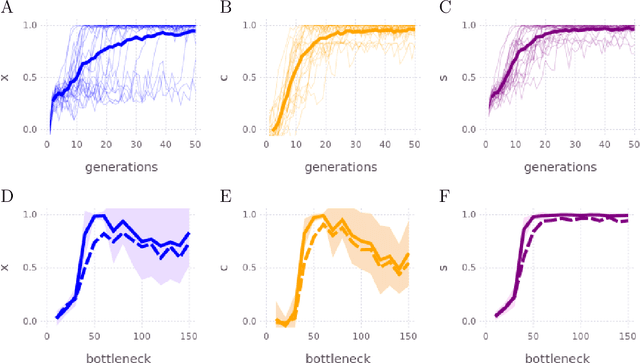
Jan 06, 2026The iterated learning model simulates the transmission of language from generation to generation in order to explore how the constraints imposed by language transmission facilitate the emergence of language structure. Despite each modelled language learner starting from a blank slate, the presence of a bottleneck limiting the number of utterances to which the learner is exposed can lead to the emergence of language that lacks ambiguity, is governed by grammatical rules, and is consistent over successive generations, that is, one that is expressive, compositional and stable. The recent introduction of a more computationally tractable and ecologically valid semi supervised iterated learning model, combining supervised and unsupervised learning within an autoencoder architecture, has enabled exploration of language transmission dynamics for much larger meaning-signal spaces. Here, for the first time, the model has been successfully applied to a language learning task involving the communication of much more complex meanings: seven-segment display images. Agents in this model are able to learn and transmit a language that is expressive: distinct codes are employed for all 128 glyphs; compositional: signal components consistently map to meaning components, and stable: the language does not change from generation to generation.
Jacobian Sparse Autoencoders: Sparsify Computations, Not Just Activations
Feb 25, 2025



Sparse autoencoders (SAEs) have been successfully used to discover sparse and human-interpretable representations of the latent activations of LLMs. However, we would ultimately like to understand the computations performed by LLMs and not just their representations. The extent to which SAEs can help us understand computations is unclear because they are not designed to "sparsify" computations in any sense, only latent activations. To solve this, we propose Jacobian SAEs (JSAEs), which yield not only sparsity in the input and output activations of a given model component but also sparsity in the computation (formally, the Jacobian) connecting them. With a na\"ive implementation, the Jacobians in LLMs would be computationally intractable due to their size. One key technical contribution is thus finding an efficient way of computing Jacobians in this setup. We find that JSAEs extract a relatively large degree of computational sparsity while preserving downstream LLM performance approximately as well as traditional SAEs. We also show that Jacobians are a reasonable proxy for computational sparsity because MLPs are approximately linear when rewritten in the JSAE basis. Lastly, we show that JSAEs achieve a greater degree of computational sparsity on pre-trained LLMs than on the equivalent randomized LLM. This shows that the sparsity of the computational graph appears to be a property that LLMs learn through training, and suggests that JSAEs might be more suitable for understanding learned transformer computations than standard SAEs.
Modeling Nonlinear Oscillator Networks Using Physics-Informed Hybrid Reservoir Computing
Nov 07, 2024



Surrogate modeling of non-linear oscillator networks remains challenging due to discrepancies between simplified analytical models and real-world complexity. To bridge this gap, we investigate hybrid reservoir computing, combining reservoir computing with "expert" analytical models. Simulating the absence of an exact model, we first test the surrogate models with parameter errors in their expert model. Second, we assess their performance when their expert model lacks key non-linear coupling terms present in an extended ground-truth model. We focus on short-term forecasting across diverse dynamical regimes, evaluating the use of these surrogates for control applications. We show that hybrid reservoir computers generally outperform standard reservoir computers and exhibit greater robustness to parameter tuning. Notably, unlike standard reservoir computers, the performance of the hybrid does not degrade when crossing an observed spectral radius threshold. Furthermore, there is good performance for dynamical regimes not accessible to the expert model, demonstrating the contribution of the reservoir.
Residual Stream Analysis with Multi-Layer SAEs
Sep 06, 2024



Sparse autoencoders (SAEs) are a promising approach to interpreting the internal representations of transformer language models. However, standard SAEs are trained separately on each transformer layer, making it difficult to use them to study how information flows across layers. To solve this problem, we introduce the multi-layer SAE (MLSAE): a single SAE trained on the residual stream activation vectors from every transformer layer simultaneously. The residual stream is usually understood as preserving information across layers, so we expected to, and did, find individual SAE features that are active at multiple layers. Interestingly, while a single SAE feature is active at different layers for different prompts, for a single prompt, we find that a single feature is far more likely to be active at a single layer. For larger underlying models, we find that the cosine similarities between adjacent layers in the residual stream are higher, so we expect more features to be active at multiple layers. These results show that MLSAEs are a promising method to study information flow in transformers. We release our code to train and analyze MLSAEs at https://github.com/tim-lawson/mlsae.
Investigating the Timescales of Language Processing with EEG and Language Models
Jun 28, 2024
This study explores the temporal dynamics of language processing by examining the alignment between word representations from a pre-trained transformer-based language model, and EEG data. Using a Temporal Response Function (TRF) model, we investigate how neural activity corresponds to model representations across different layers, revealing insights into the interaction between artificial language models and brain responses during language comprehension. Our analysis reveals patterns in TRFs from distinct layers, highlighting varying contributions to lexical and compositional processing. Additionally, we used linear discriminant analysis (LDA) to isolate part-of-speech (POS) representations, offering insights into their influence on neural responses and the underlying mechanisms of syntactic processing. These findings underscore EEG's utility for probing language processing dynamics with high temporal resolution. By bridging artificial language models and neural activity, this study advances our understanding of their interaction at fine timescales.
Modeling language contact with the Iterated Learning Model
Jun 11, 2024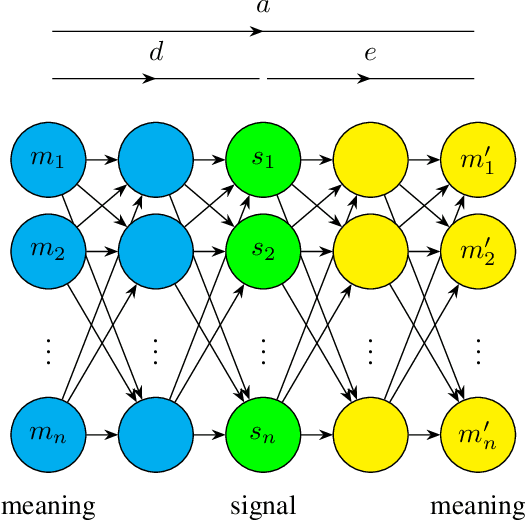
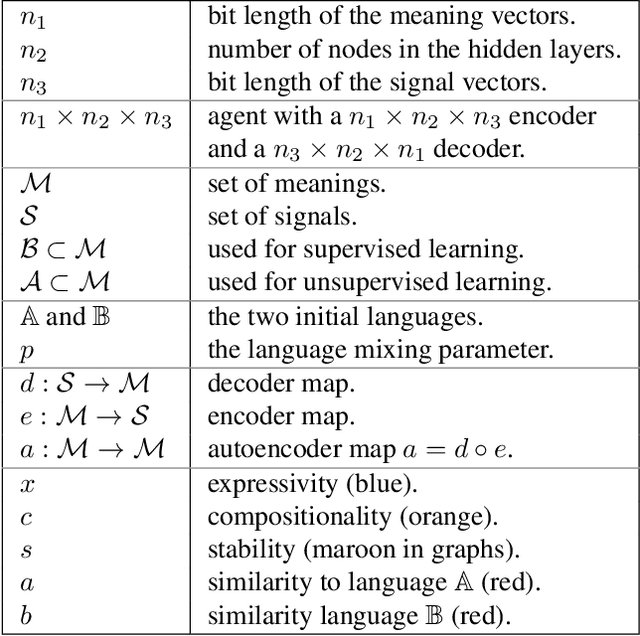
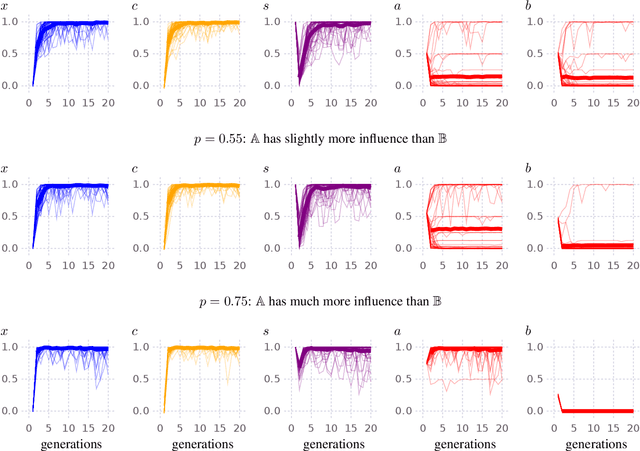
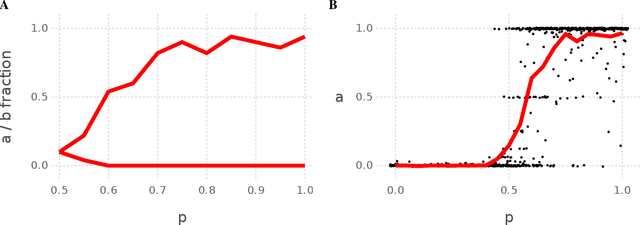
Contact between languages has the potential to transmit vocabulary and other language features; however, this does not always happen. Here, an iterated learning model is used to examine, in a simple way, the resistance of languages to change during language contact. Iterated learning models are agent-based models of language change, they demonstrate that languages that are expressive and compositional arise spontaneously as a consequence of a language transmission bottleneck. A recently introduced type of iterated learning model, the Semi-Supervised ILM is used to simulate language contact. These simulations do not include many of the complex factors involved in language contact and do not model a population of speakers; nonetheless the model demonstrates that the dynamics which lead languages in the model to spontaneously become expressive and compositional, also cause a language to maintain its core traits even after mixing with another language.
An iterated learning model of language change that mixes supervised and unsupervised learning
May 31, 2024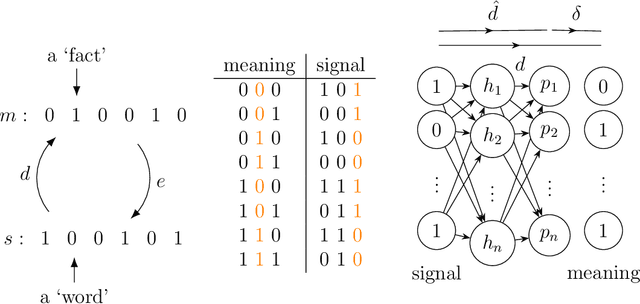
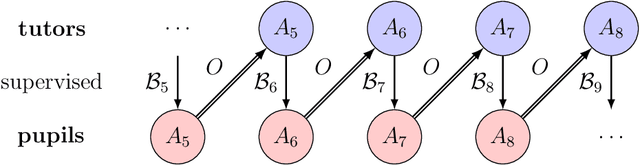
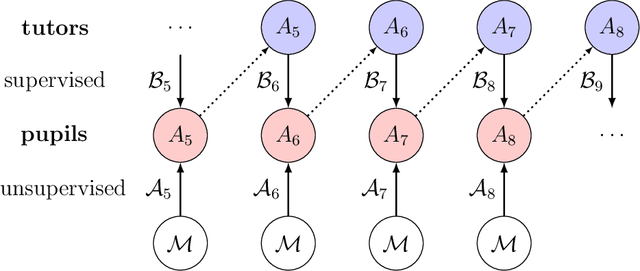
The iterated learning model is an agent-based model of language change in which language is transmitted from a tutor to a pupil which itself becomes a tutor to a new pupil, and so on. Languages that are stable, expressive, and compositional arise spontaneously as a consequence of a language transmission bottleneck. Previous models have implemented an agent's mapping from signals to meanings using an artificial neural network decoder, but have relied on an unrealistic and computationally expensive process of obversion to implement the associated encoder, mapping from meanings to signals. Here, a new model is presented in which both decoder and encoder are neural networks, trained separately through supervised learning, and trained together through unsupervised learning in the form of an autoencoder. This avoids the substantial computational burden entailed in obversion and introduces a mixture of supervised and unsupervised learning as observed during human development.
Investigating grammatical abstraction in language models using few-shot learning of novel noun gender
Mar 15, 2024



Humans can learn a new word and infer its grammatical properties from very few examples. They have an abstract notion of linguistic properties like grammatical gender and agreement rules that can be applied to novel syntactic contexts and words. Drawing inspiration from psycholinguistics, we conduct a noun learning experiment to assess whether an LSTM and a decoder-only transformer can achieve human-like abstraction of grammatical gender in French. Language models were tasked with learning the gender of a novel noun embedding from a few examples in one grammatical agreement context and predicting agreement in another, unseen context. We find that both language models effectively generalise novel noun gender from one to two learning examples and apply the learnt gender across agreement contexts, albeit with a bias for the masculine gender category. Importantly, the few-shot updates were only applied to the embedding layers, demonstrating that models encode sufficient gender information within the word embedding space. While the generalisation behaviour of models suggests that they represent grammatical gender as an abstract category, like humans, further work is needed to explore the details of how exactly this is implemented. For a comparative perspective with human behaviour, we conducted an analogous one-shot novel noun gender learning experiment, which revealed that native French speakers, like language models, also exhibited a masculine gender bias and are not excellent one-shot learners either.
Social Value Orientation and Integral Emotions in Multi-Agent Systems
May 09, 2023


Human social behavior is influenced by individual differences in social preferences. Social value orientation (SVO) is a measurable personality trait which indicates the relative importance an individual places on their own and on others' welfare when making decisions. SVO and other individual difference variables are strong predictors of human behavior and social outcomes. However, there are transient changes human behavior associated with emotions that are not captured by individual differences alone. Integral emotions, the emotions which arise in direct response to a decision-making scenario, have been linked to temporary shifts in decision-making preferences. In this work, we investigated the effects of moderating social preferences with integral emotions in multi-agent societies. We developed Svoie, a method for designing agents which make decisions based on established SVO policies, as well as alternative integral emotion policies in response to task outcomes. We conducted simulation experiments in a resource-sharing task environment, and compared societies of Svoie agents with societies of agents with fixed SVO policies. We find that societies of agents which adapt their behavior through integral emotions achieved similar collective welfare to societies of agents with fixed SVO policies, but with significantly reduced inequality between the welfare of agents with different SVO traits. We observed that by allowing agents to change their policy in response to task outcomes, agents can moderate their behavior to achieve greater social equality. \end{abstract}
Beyond the limitations of any imaginable mechanism: large language models and psycholinguistics
Feb 28, 2023Large language models are not detailed models of human linguistic processing. They are, however, extremely successful at their primary task: providing a model for language. For this reason and because there are no animal models for language, large language models are important in psycholinguistics: they are useful as a practical tool, as an illustrative comparative, and philosophically, as a basis for recasting the relationship between language and thought.