 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetry-preserving graph attention network to solve routing problems at multiple resolutions
Oct 24, 2023


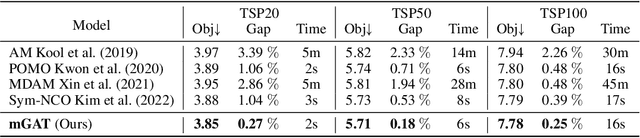
Travelling Salesperson Problems (TSPs) and Vehicle Routing Problems (VRPs) have achieved reasonable improvement in accuracy and computation time with the adaptation of Machine Learning (ML) methods. However, none of the previous works completely respects the symmetries arising from TSPs and VRPs including rotation, translation, permutation, and scaling. In this work, we introduce the first-ever completely equivariant model and training to solve combinatorial problems. Furthermore, it is essential to capture the multiscale structure (i.e. from local to global information) of the input graph, especially for the cases of large and long-range graphs, while previous methods are limited to extracting only local information that can lead to a local or sub-optimal solution. To tackle the above limitation, we propose a Multiresolution scheme in combination with Equivariant Graph Attention network (mEGAT) architecture, which can learn the optimal route based on low-level and high-level graph resolutions in an efficient way. In particular, our approach constructs a hierarchy of coarse-graining graphs from the input graph, in which we try to solve the routing problems on simple low-level graphs first, then utilize that knowledge for the more complex high-level graphs. Experimentally, we have shown that our model outperforms existing baselines and proved that symmetry preservation and multiresolution are important recipes for solving combinatorial problems in a data-driven manner. Our source code is publicly available at https://github.com/HySonLab/Multires-NP-hard
Graph Attention-based Deep Reinforcement Learning for solving the Chinese Postman Problem with Load-dependent costs
Oct 24, 2023



Recently, Deep reinforcement learning (DRL) models have shown promising results in solving routing problems. However, most DRL solvers are commonly proposed to solve node routing problems, such as the Traveling Salesman Problem (TSP). Meanwhile, there has been limited research on applying neural methods to arc routing problems, such as the Chinese Postman Problem (CPP), since they often feature irregular and complex solution spaces compared to TSP. To fill these gaps, this paper proposes a novel DRL framework to address the CPP with load-dependent costs (CPP-LC) (Corberan et al., 2018), which is a complex arc routing problem with load constraints. The novelty of our method is two-fold. First, we formulate the CPP-LC as a Markov Decision Process (MDP) sequential model. Subsequently, we introduce an autoregressive model based on DRL, namely Arc-DRL, consisting of an encoder and decoder to address the CPP-LC challenge effectively. Such a framework allows the DRL model to work efficiently and scalably to arc routing problems. Furthermore, we propose a new bio-inspired meta-heuristic solution based on Evolutionary Algorithm (EA) for CPP-LC. Extensive experiments show that Arc-DRL outperforms existing meta-heuristic methods such as Iterative Local Search (ILS) and Variable Neighborhood Search (VNS) proposed by (Corberan et al., 2018) on large benchmark datasets for CPP-LC regarding both solution quality and running time; while the EA gives the best solution quality with much more running time. We release our C++ implementations for metaheuristics such as EA, ILS and VNS along with the code for data generation and our generated data at https://github.com/HySonLab/Chinese_Postman_Problem
ViDeBERTa: A powerful pre-trained language model for Vietnamese
Jan 25, 2023This paper presents ViDeBERTa, a new pre-trained monolingual language model for Vietnamese, with three versions - ViDeBERTa_xsmall, ViDeBERTa_base, and ViDeBERTa_large, which are pre-trained on a large-scale corpus of high-quality and diverse Vietnamese texts using DeBERTa architecture. Although many successful pre-trained language models based on Transformer have been widely proposed for the English language, there are still few pre-trained models for Vietnamese, a low-resource language, that perform good results on downstream tasks, especially Question answering. We fine-tune and evaluate our model on three important natural language downstream tasks, Part-of-speech tagging, Named-entity recognition, and Question answering. The empirical results demonstrate that ViDeBERTa with far fewer parameters surpasses the previous state-of-the-art models on multiple Vietnamese-specific natural language understanding tasks. Notably, ViDeBERTa_base with 86M parameters, which is only about 23% of PhoBERT_large with 370M parameters, still performs the same or better results than the previous state-of-the-art model. Our ViDeBERTa models are available at: https://github.com/HySonLab/ViDeBERTa.