 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of Energy Consumption and Completion Time in Federated Learning
Sep 29, 2022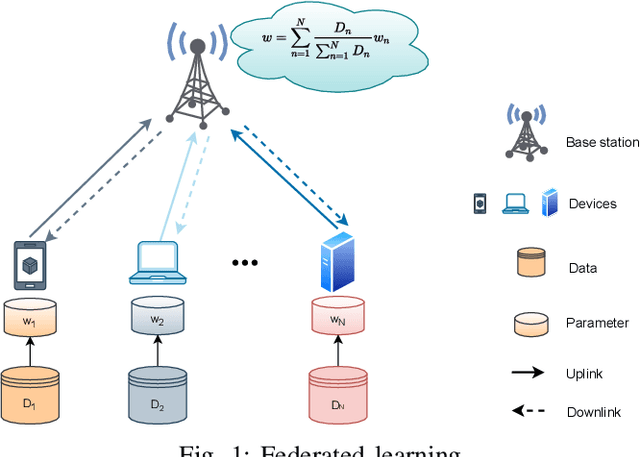
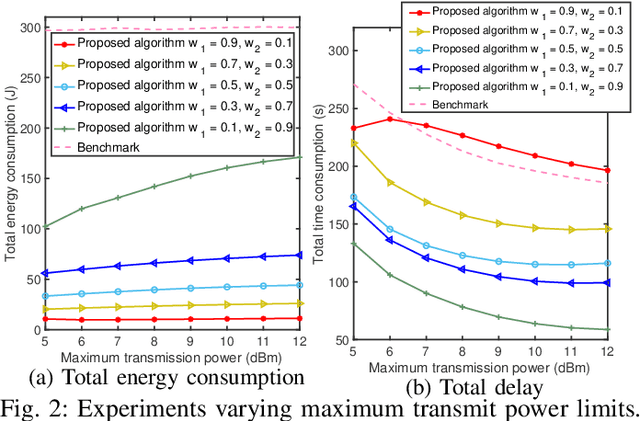
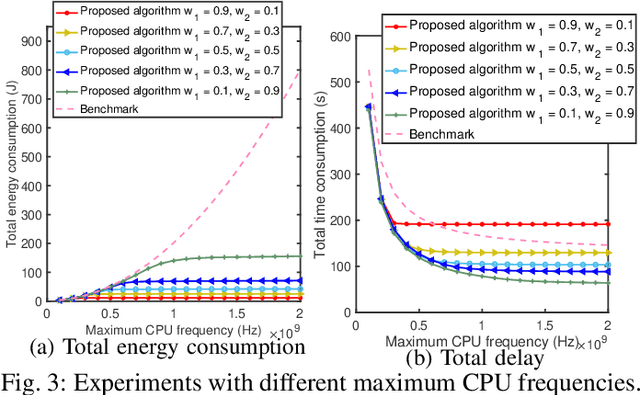
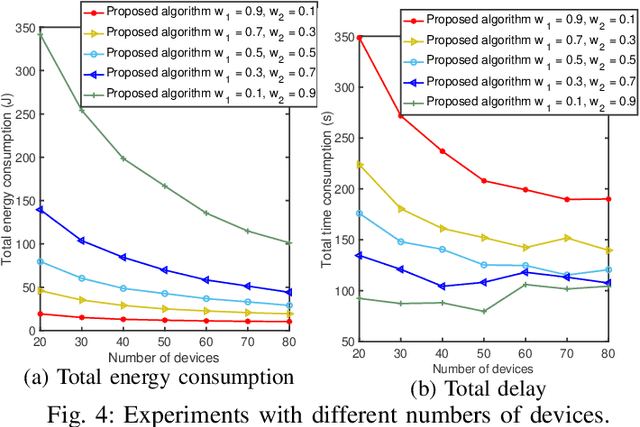
Federated Learning (FL) is an intriguing distributed machine learning approach due to its privacy-preserving characteristics. To balance the trade-off between energy and execution latency, and thus accommodate different demands and application scenarios, we formulate an optimization problem to minimize a weighted sum of total energy consumption and completion time through two weight parameters. The optimization variables include bandwidth, transmission power and CPU frequency of each device in the FL system, where all devices are linked to a base station and train a global model collaboratively. Through decomposing the non-convex optimization problem into two subproblems, we devise a resource allocation algorithm to determine the bandwidth allocation, transmission power, and CPU frequency for each participating device. We further present the convergence analysis and computational complexity of the proposed algorithm. Numerical results show that our proposed algorithm not only has better performance at different weight parameters (i.e., different demands) but also outperforms the state of the art.
Reconstructing a dynamical system and forecasting time series by self-consistent deep learning
Aug 04, 2021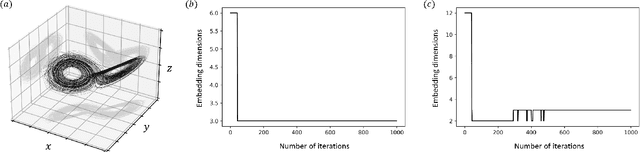


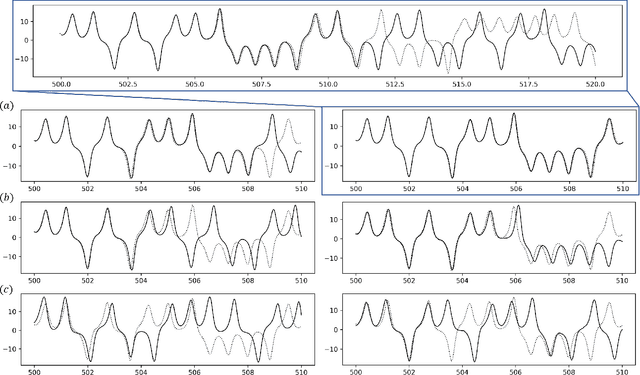
We introduce a self-consistent deep-learning framework which, for a noisy deterministic time series, provides unsupervised filtering, state-space reconstruction, identification of the underlying differential equations and forecasting. Without a priori information on the signal, we embed the time series in a state space, where deterministic structures, i.e. attractors, are revealed. Under the assumption that the evolution of solution trajectories is described by an unknown dynamical system, we filter out stochastic outliers. The embedding function, the solution trajectories and the dynamical systems are constructed using deep neural networks, respectively. By exploiting the differentiability of the neural solution trajectory, the neural dynamical system is defined locally at each time, mitigating the need for propagating gradients through numerical solvers. On a chaotic time series masked by additive Gaussian noise, we demonstrate the filtering ability and the predictive power of the proposed framework.
Deep learning in physics: a study of dielectric quasi-cubic particles in a uniform electric field
May 11, 2021
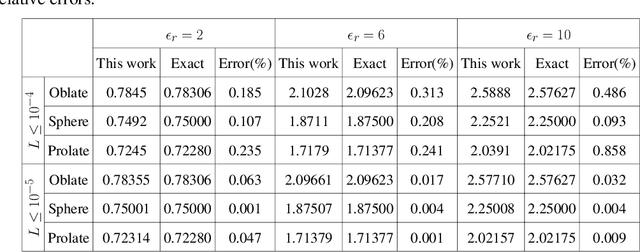
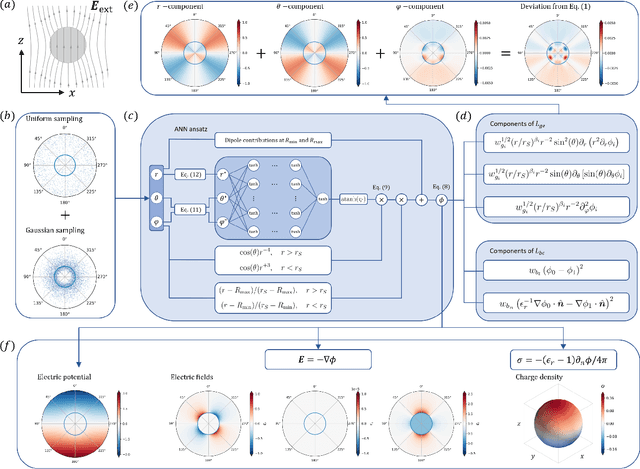
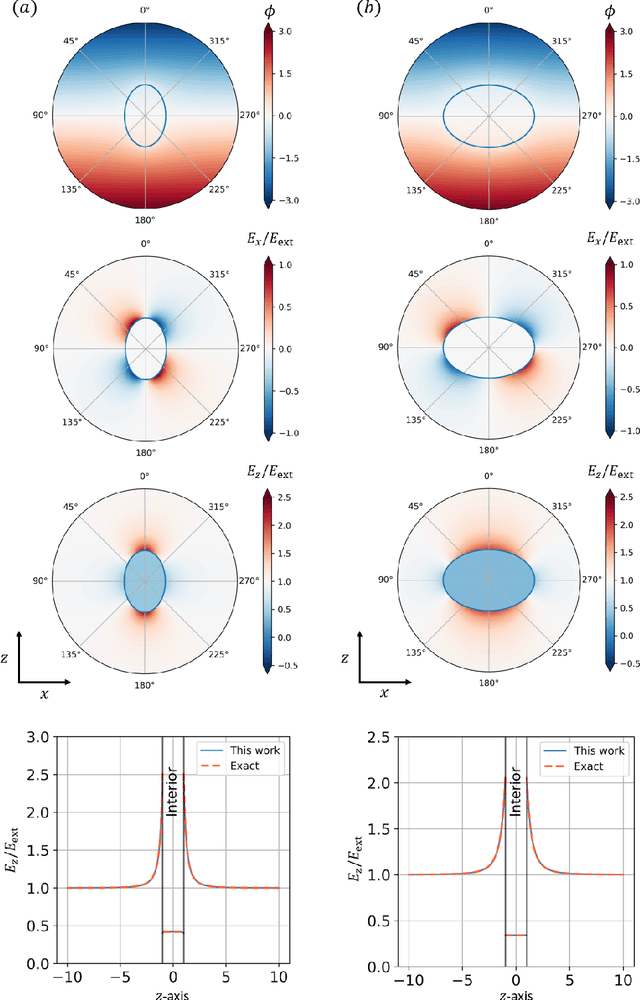
Solving physics problems for which we know the equations, boundary conditions and symmetries can be done by deep learning. The constraints can be either imposed as terms in a loss function or used to formulate a neural ansatz. In the present case study, we calculate the induced field inside and outside a dielectric cube placed in a uniform electric field, wherein the dielectric mismatch at edges and corners of the cube makes accurate calculations numerically challenging. The electric potential is expressed as an ansatz incorporating neural networks with known leading order behaviors and symmetries and the Laplace's equation is then solved with boundary conditions at the dielectric interface by minimizing a loss function. The loss function ensures that both Laplace's equation and boundary conditions are satisfied everywhere inside a large solution domain. We study how the electric potential inside and outside a quasi-cubic particle evolves through a sequence of shapes from a sphere to a cube. The neural network being differentiable, it is straightforward to calculate the electric field over the whole domain, the induced surface charge distribution and the polarizability. The neural network being retentive, one can efficiently follow how the field changes upon particle's shape or dielectric constant by iterating from any previously converged solution. The present work's objective is two-fold, first to show how an a priori knowledge can be incorporated into neural networks to achieve efficient learning and second to apply the method and study how the induced field and polarizability change when a dielectric particle progressively changes its shape from a sphere to a cube.