 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAXAL: A Large-Scale Multilingual African Language Speech Corpus
Feb 02, 2026The advancement of speech technology has predominantly favored high-resource languages, creating a significant digital divide for speakers of most Sub-Saharan African languages. To address this gap, we introduce WAXAL, a large-scale, openly accessible speech dataset for 21 languages representing over 100 million speakers. The collection consists of two main components: an Automated Speech Recognition (ASR) dataset containing approximately 1,250 hours of transcribed, natural speech from a diverse range of speakers, and a Text-to-Speech (TTS) dataset with over 180 hours of high-quality, single-speaker recordings reading phonetically balanced scripts. This paper details our methodology for data collection, annotation, and quality control, which involved partnerships with four African academic and community organizations. We provide a detailed statistical overview of the dataset and discuss its potential limitations and ethical considerations. The WAXAL datasets are released at https://huggingface.co/datasets/google/WaxalNLP under the permissive CC-BY-4.0 license to catalyze research, enable the development of inclusive technologies, and serve as a vital resource for the digital preservation of these languages.
Misinformation detection in Luganda-English code-mixed social media text
Apr 03, 2021
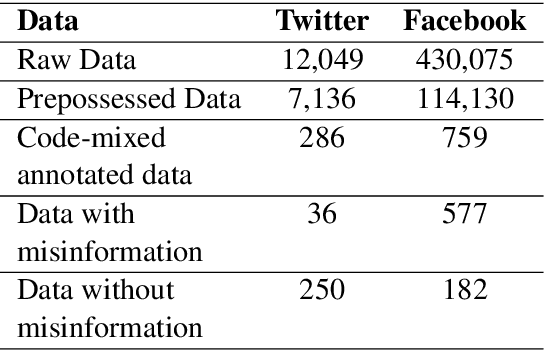


The increasing occurrence, forms, and negative effects of misinformation on social media platforms has necessitated more misinformation detection tools. Currently, work is being done addressing COVID-19 misinformation however, there are no misinformation detection tools for any of the 40 distinct indigenous Ugandan languages. This paper addresses this gap by presenting basic language resources and a misinformation detection data set based on code-mixed Luganda-English messages sourced from the Facebook and Twitter social media platforms. Several machine learning methods are applied on the misinformation detection data set to develop classification models for detecting whether a code-mixed Luganda-English message contains misinformation or not. A 10-fold cross validation evaluation of the classification methods in an experimental misinformation detection task shows that a Discriminative Multinomial Naive Bayes (DMNB) method achieves the highest accuracy and F-measure of 78.19% and 77.90% respectively. Also, Support Vector Machine and Bagging ensemble classification models achieve comparable results. These results are promising since the machine learning models are based on n-gram features from only the misinformation detection dataset.