 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Weak Supervision for Cell Localization in Digital Pathology Using Multitask Learning and Consistency Loss
Dec 19, 2024Cell detection and segmentation are integral parts of automated systems in digital pathology. Encoder-decoder networks have emerged as a promising solution for these tasks. However, training of these networks has typically required full boundary annotations of cells, which are labor-intensive and difficult to obtain on a large scale. However, in many applications, such as cell counting, weaker forms of annotations--such as point annotations or approximate cell counts--can provide sufficient supervision for training. This study proposes a new mixed-supervision approach for training multitask networks in digital pathology by incorporating cell counts derived from the eyeballing process--a quick visual estimation method commonly used by pathologists. This study has two main contributions: (1) It proposes a mixed-supervision strategy for digital pathology that utilizes cell counts obtained by eyeballing as an auxiliary supervisory signal to train a multitask network for the first time. (2) This multitask network is designed to concurrently learn the tasks of cell counting and cell localization, and this study introduces a consistency loss that regularizes training by penalizing inconsistencies between the predictions of these two tasks. Our experiments on two datasets of hematoxylin-eosin stained tissue images demonstrate that the proposed approach effectively utilizes the weakest form of annotation, improving performance when stronger annotations are limited. These results highlight the potential of integrating eyeballing-derived ground truths into the network training, reducing the need for resource-intensive annotations.
PI-Att: Topology Attention for Segmentation Networks through Adaptive Persistence Image Representation
Aug 15, 2024Segmenting multiple objects (e.g., organs) in medical images often requires an understanding of their topology, which simultaneously quantifies the shape of the objects and their positions relative to each other. This understanding is important for segmentation networks to generalize better with limited training data, which is common in medical image analysis. However, many popular networks were trained to optimize only pixel-wise performance, ignoring the topological correctness of the segmentation. In this paper, we introduce a new topology-aware loss function, which we call PI-Att, that explicitly forces the network to minimize the topological dissimilarity between the ground truth and prediction maps. We quantify the topology of each map by the persistence image representation, for the first time in the context of a segmentation network loss. Besides, we propose a new mechanism to adaptively calculate the persistence image at the end of each epoch based on the network's performance. This adaptive calculation enables the network to learn topology outline in the first epochs, and then topology details towards the end of training. The effectiveness of the proposed PI-Att loss is demonstrated on two different datasets for aorta and great vessel segmentation in computed tomography images.
FourierLoss: Shape-Aware Loss Function with Fourier Descriptors
Sep 21, 2023Encoder-decoder networks become a popular choice for various medical image segmentation tasks. When they are trained with a standard loss function, these networks are not explicitly enforced to preserve the shape integrity of an object in an image. However, this ability of the network is important to obtain more accurate results, especially when there is a low-contrast difference between the object and its surroundings. In response to this issue, this work introduces a new shape-aware loss function, which we name FourierLoss. This loss function relies on quantifying the shape dissimilarity between the ground truth and the predicted segmentation maps through the Fourier descriptors calculated on their objects, and penalizing this dissimilarity in network training. Different than the previous studies, FourierLoss offers an adaptive loss function with trainable hyperparameters that control the importance of the level of the shape details that the network is enforced to learn in the training process. This control is achieved by the proposed adaptive loss update mechanism, which end-to-end learns the hyperparameters simultaneously with the network weights by backpropagation. As a result of using this mechanism, the network can dynamically change its attention from learning the general outline of an object to learning the details of its contour points, or vice versa, in different training epochs. Working on 2879 computed tomography images of 93 subjects, our experiments revealed that the proposed adaptive shape-aware loss function led to statistically significantly better results for liver segmentation, compared to its counterparts.
Topology-Aware Loss for Aorta and Great Vessel Segmentation in Computed Tomography Images
Jul 06, 2023



Segmentation networks are not explicitly imposed to learn global invariants of an image, such as the shape of an object and the geometry between multiple objects, when they are trained with a standard loss function. On the other hand, incorporating such invariants into network training may help improve performance for various segmentation tasks when they are the intrinsic characteristics of the objects to be segmented. One example is segmentation of aorta and great vessels in computed tomography (CT) images where vessels are found in a particular geometry in the body due to the human anatomy and they mostly seem as round objects on a 2D CT image. This paper addresses this issue by introducing a new topology-aware loss function that penalizes topology dissimilarities between the ground truth and prediction through persistent homology. Different from the previously suggested segmentation network designs, which apply the threshold filtration on a likelihood function of the prediction map and the Betti numbers of the ground truth, this paper proposes to apply the Vietoris-Rips filtration to obtain persistence diagrams of both ground truth and prediction maps and calculate the dissimilarity with the Wasserstein distance between the corresponding persistence diagrams. The use of this filtration has advantage of modeling shape and geometry at the same time, which may not happen when the threshold filtration is applied. Our experiments on 4327 CT images of 24 subjects reveal that the proposed topology-aware loss function leads to better results than its counterparts, indicating the effectiveness of this use.
FourierNet: Shape-Preserving Network for Henle's Fiber Layer Segmentation in Optical Coherence Tomography Images
Jan 17, 2022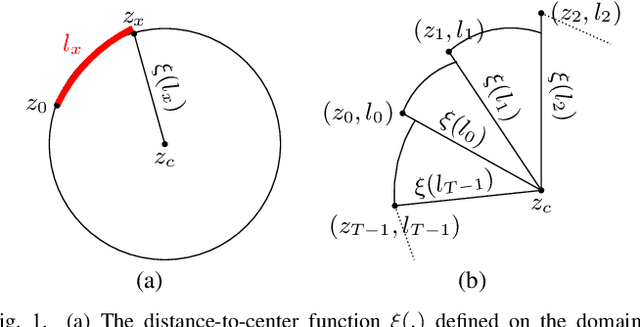
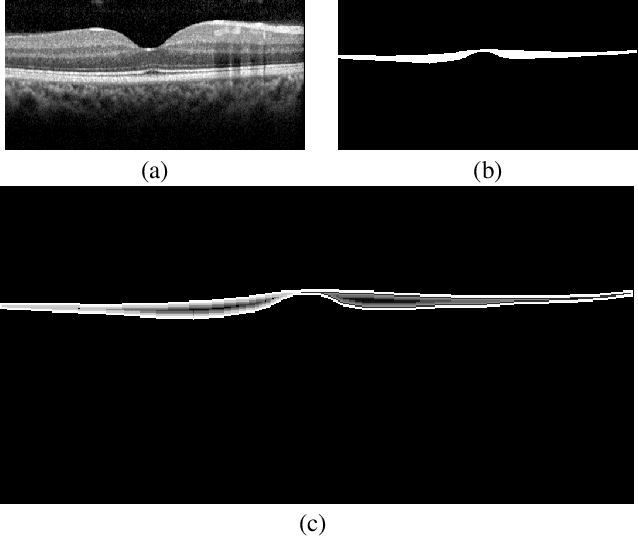
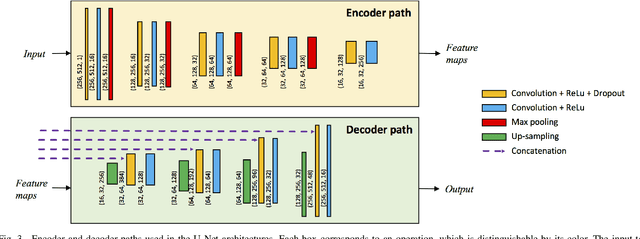
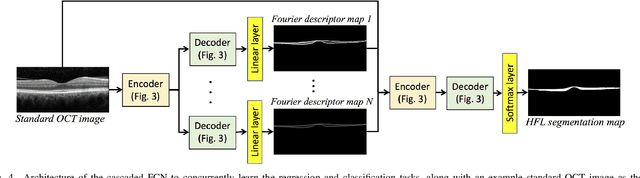
The Henle's fiber layer (HFL) in the retina carries valuable information on the macular condition of an eye. However, in the common practice, this layer is not separately segmented but rather included in the outer nuclear layer since it is difficult to perceive HFL contours on standard optical coherence tomography (OCT) imaging. Due to its variable reflectivity under an imaging beam, delineating the HFL contours necessitates directional OCT, which requires additional imaging. This paper addresses this issue by introducing a shape-preserving network, FourierNet, that achieves HFL segmentation in standard OCT scans with the target performance obtained when directional OCT scans are used. FourierNet is a new cascaded network design that puts forward the idea of benefiting the shape prior of HFL in the network training. This design proposes to represent the shape prior by extracting Fourier descriptors on the HFL contours and defining an additional regression task of learning these descriptors. It then formulates HFL segmentation as concurrent learning of regression and classification tasks, in which Fourier descriptors are estimated from an input image to encode the shape prior and used together with the input image to construct the HFL segmentation map. Our experiments on 1470 images of 30 OCT scans reveal that quantifying the HFL shape with Fourier descriptors and concurrently learning them with the main task of HFL segmentation lead to better results. This indicates the effectiveness of designing a shape-preserving network to improve HFL segmentation by reducing the need to perform directional OCT imaging.
DeepDistance: A Multi-task Deep Regression Model for Cell Detection in Inverted Microscopy Images
Aug 29, 2019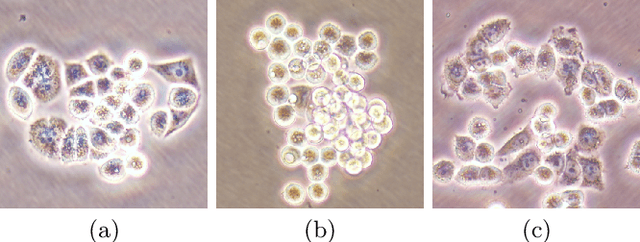
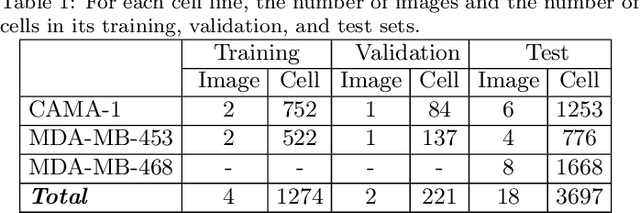

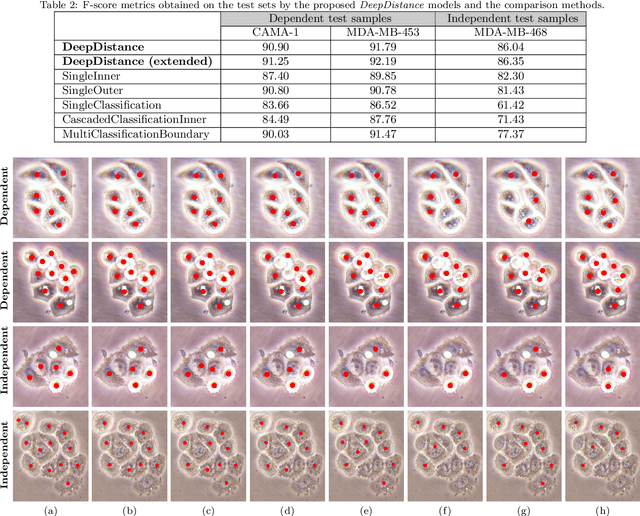
This paper presents a new deep regression model, which we call DeepDistance, for cell detection in images acquired with inverted microscopy. This model considers cell detection as a task of finding most probable locations that suggest cell centers in an image. It represents this main task with a regression task of learning an inner distance metric. However, different than the previously reported regression based methods, the DeepDistance model proposes to approach its learning as a multi-task regression problem where multiple tasks are learned by using shared feature representations. To this end, it defines a secondary metric, normalized outer distance, to represent a different aspect of the problem and proposes to define its learning as complementary to the main cell detection task. In order to learn these two complementary tasks more effectively, the DeepDistance model designs a fully convolutional network (FCN) with a shared encoder path and end-to-end trains this FCN to concurrently learn the tasks in parallel. DeepDistance uses the inner distances estimated by this FCN in a detection algorithm to locate individual cells in a given image. For further performance improvement on the main task, this paper also presents an extended version of the DeepDistance model. This extended model includes an auxiliary classification task and learns it in parallel to the two regression tasks by sharing feature representations with them. Our experiments on three different human cell lines reveal that the proposed multi-task learning models, the DeepDistance model and its extended version, successfully identify cell locations, even for the cell line that was not used in training, and improve the results of the previous deep learning methods.
AttentionBoost: Learning What to Attend by Boosting Fully Convolutional Networks
Aug 06, 2019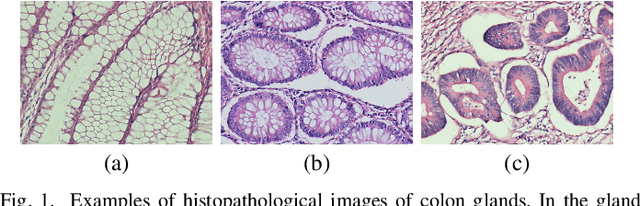
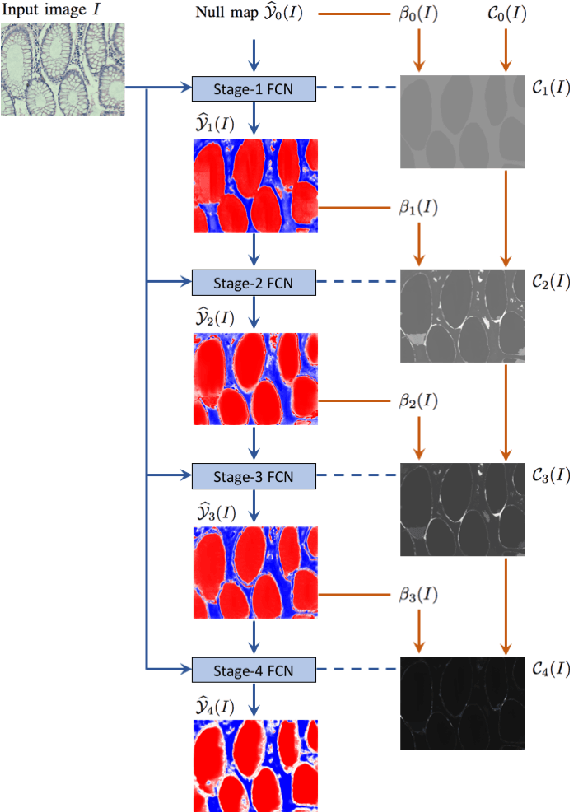
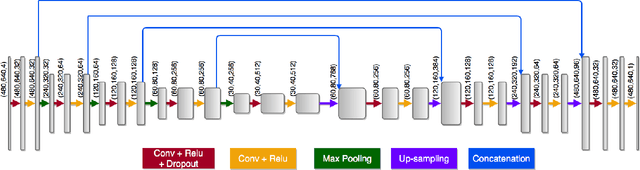

Dense prediction models are widely used for image segmentation. One important challenge is to sufficiently train these models to yield good generalizations for hard-to-learn pixels. A typical group of such hard-to-learn pixels are boundaries between instances. Many studies have proposed to give specific attention to learning the boundary pixels. They include designing multi-task networks with an additional task of boundary prediction and increasing the weights of boundary pixels' predictions in the loss function. Such strategies require defining what to attend beforehand and incorporating this defined attention to the learning model. However, there may exist other groups of hard-to-learn pixels and manually defining and incorporating the appropriate attention for each group may not be feasible. In order to provide a more attainable and scalable solution, this paper proposes AttentionBoost, which is a new multi-attention learning model based on adaptive boosting. AttentionBoost designs a multi-stage network and introduces a new loss adjustment mechanism for a dense prediction model to adaptively learn what to attend at each stage directly on image data without necessitating any prior definition about what to attend. This mechanism modulates the attention of each stage to correct the mistakes of previous stages, by adjusting the loss weight of each pixel prediction separately with respect to how accurate the previous stages are on this pixel. This mechanism enables AttentionBoost to learn different attentions for different pixels at the same stage, according to difficulty of learning these pixels, as well as multiple attentions for the same pixel at different stages, according to confidence of these stages on their predictions for this pixel. Using gland segmentation as a showcase application, our experiments demonstrate that AttentionBoost improves the results of its counterparts.