 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepDistance: A Multi-task Deep Regression Model for Cell Detection in Inverted Microscopy Images
Aug 29, 2019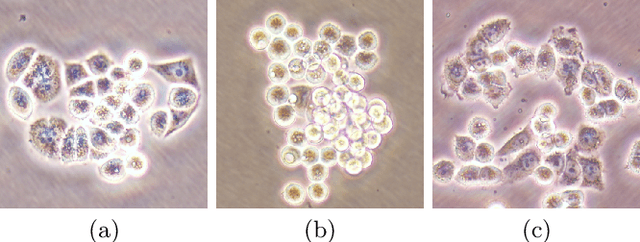
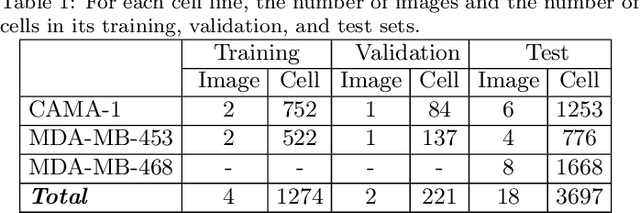

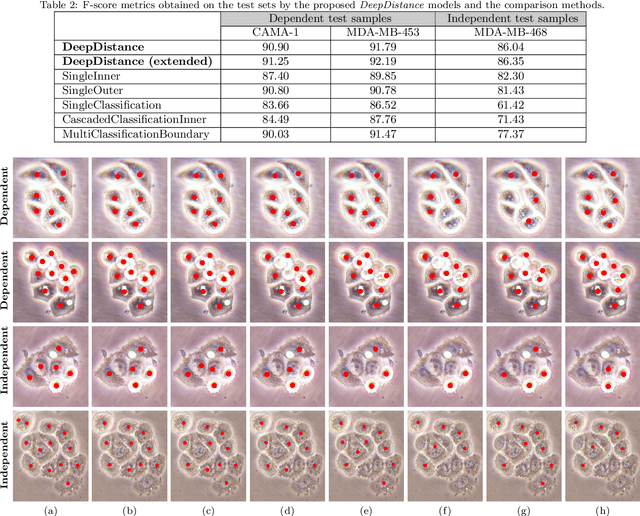
This paper presents a new deep regression model, which we call DeepDistance, for cell detection in images acquired with inverted microscopy. This model considers cell detection as a task of finding most probable locations that suggest cell centers in an image. It represents this main task with a regression task of learning an inner distance metric. However, different than the previously reported regression based methods, the DeepDistance model proposes to approach its learning as a multi-task regression problem where multiple tasks are learned by using shared feature representations. To this end, it defines a secondary metric, normalized outer distance, to represent a different aspect of the problem and proposes to define its learning as complementary to the main cell detection task. In order to learn these two complementary tasks more effectively, the DeepDistance model designs a fully convolutional network (FCN) with a shared encoder path and end-to-end trains this FCN to concurrently learn the tasks in parallel. DeepDistance uses the inner distances estimated by this FCN in a detection algorithm to locate individual cells in a given image. For further performance improvement on the main task, this paper also presents an extended version of the DeepDistance model. This extended model includes an auxiliary classification task and learns it in parallel to the two regression tasks by sharing feature representations with them. Our experiments on three different human cell lines reveal that the proposed multi-task learning models, the DeepDistance model and its extended version, successfully identify cell locations, even for the cell line that was not used in training, and improve the results of the previous deep learning methods.
AttentionBoost: Learning What to Attend by Boosting Fully Convolutional Networks
Aug 06, 2019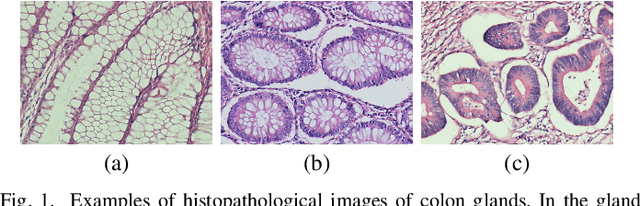
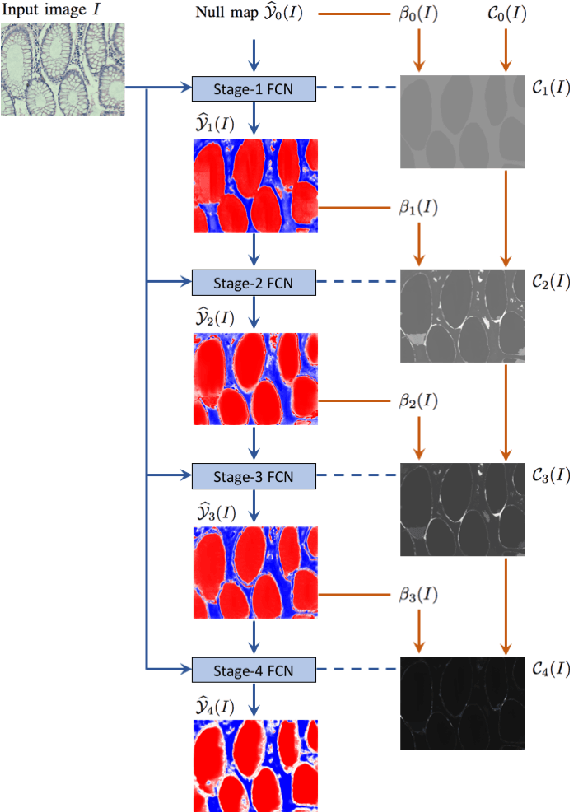
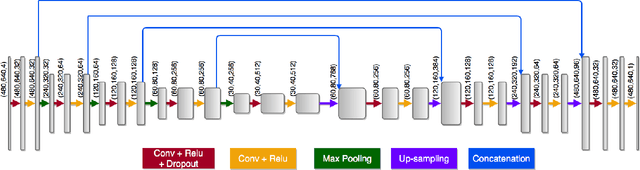

Dense prediction models are widely used for image segmentation. One important challenge is to sufficiently train these models to yield good generalizations for hard-to-learn pixels. A typical group of such hard-to-learn pixels are boundaries between instances. Many studies have proposed to give specific attention to learning the boundary pixels. They include designing multi-task networks with an additional task of boundary prediction and increasing the weights of boundary pixels' predictions in the loss function. Such strategies require defining what to attend beforehand and incorporating this defined attention to the learning model. However, there may exist other groups of hard-to-learn pixels and manually defining and incorporating the appropriate attention for each group may not be feasible. In order to provide a more attainable and scalable solution, this paper proposes AttentionBoost, which is a new multi-attention learning model based on adaptive boosting. AttentionBoost designs a multi-stage network and introduces a new loss adjustment mechanism for a dense prediction model to adaptively learn what to attend at each stage directly on image data without necessitating any prior definition about what to attend. This mechanism modulates the attention of each stage to correct the mistakes of previous stages, by adjusting the loss weight of each pixel prediction separately with respect to how accurate the previous stages are on this pixel. This mechanism enables AttentionBoost to learn different attentions for different pixels at the same stage, according to difficulty of learning these pixels, as well as multiple attentions for the same pixel at different stages, according to confidence of these stages on their predictions for this pixel. Using gland segmentation as a showcase application, our experiments demonstrate that AttentionBoost improves the results of its counterparts.