 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tree-based Federated Learning Approach for Personalized Treatment Effect Estimation from Heterogeneous Data Sources
Mar 10, 2021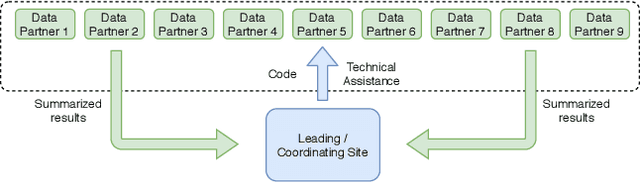

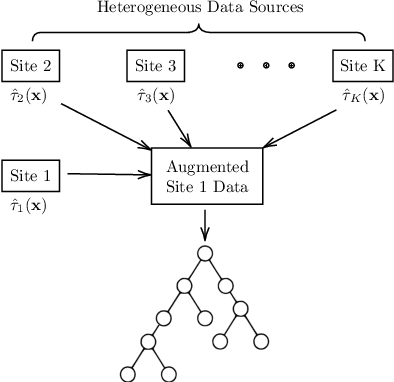

Federated learning is an appealing framework for analyzing sensitive data from distributed health data networks due to its protection of data privacy. Under this framework, data partners at local sites collaboratively build an analytical model under the orchestration of a coordinating site, while keeping the data decentralized. However, existing federated learning methods mainly assume data across sites are homogeneous samples of the global population, hence failing to properly account for the extra variability across sites in estimation and inference. Drawing on a multi-hospital electronic health records network, we develop an efficient and interpretable tree-based ensemble of personalized treatment effect estimators to join results across hospital sites, while actively modeling for the heterogeneity in data sources through site partitioning. The efficiency of our method is demonstrated by a study of causal effects of oxygen saturation on hospital mortality and backed up by comprehensive numerical results.
A Bayesian Finite Mixture Model with Variable Selection for Data with Mixed-type Variables
May 09, 2019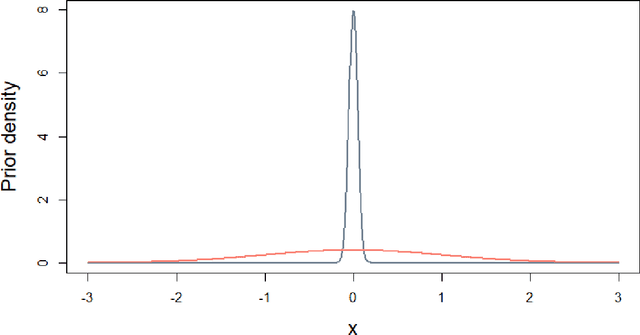
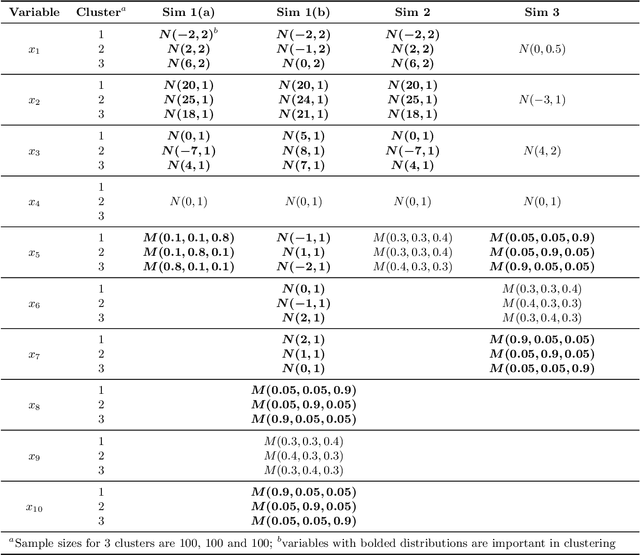

Finite mixture model is an important branch of clustering methods and can be applied on data sets with mixed types of variables. However, challenges exist in its applications. First, it typically relies on the EM algorithm which could be sensitive to the choice of initial values. Second, biomarkers subject to limits of detection (LOD) are common to encounter in clinical data, which brings censored variables into finite mixture model. Additionally, researchers are recently getting more interest in variable importance due to the increasing number of variables that become available for clustering. To address these challenges, we propose a Bayesian finite mixture model to simultaneously conduct variable selection, account for biomarker LOD and obtain clustering results. We took a Bayesian approach to obtain parameter estimates and the cluster membership to bypass the limitation of the EM algorithm. To account for LOD, we added one more step in Gibbs sampling to iteratively fill in biomarker values below or above LODs. In addition, we put a spike-and-slab type of prior on each variable to obtain variable importance. Simulations across various scenarios were conducted to examine the performance of this method. Real data application on electronic health records was also conducted.
Hybrid Density- and Partition-based Clustering Algorithm for Data with Mixed-type Variables
May 06, 2019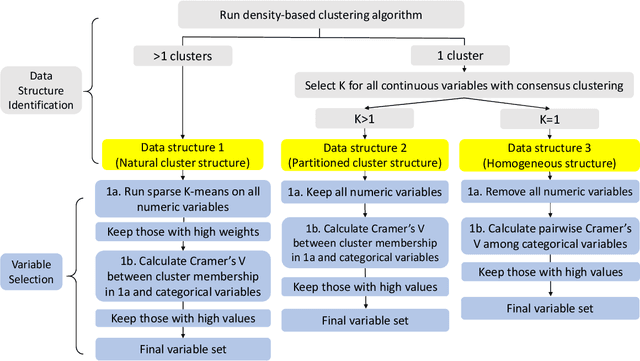

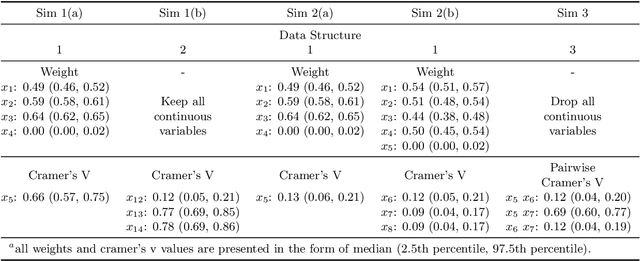
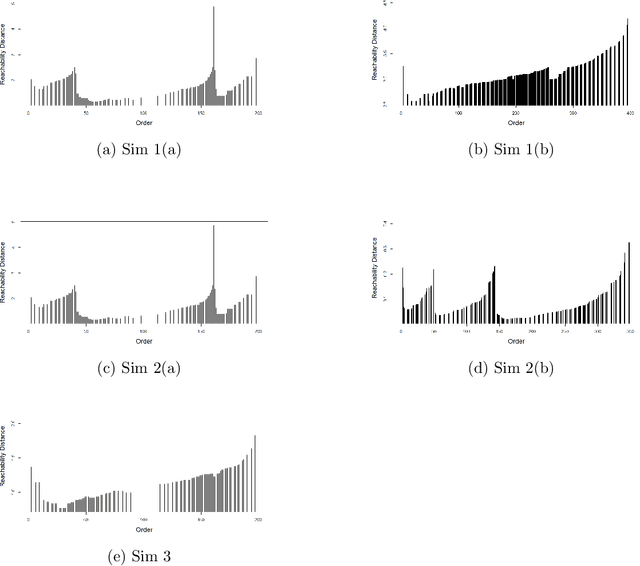
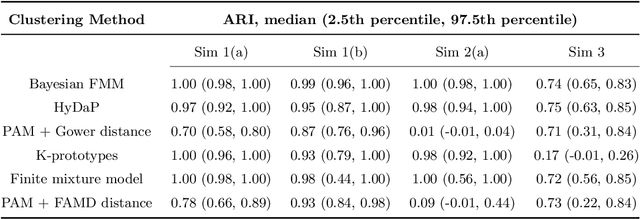
Clustering is an essential technique for discovering patterns in data. The steady increase in amount and complexity of data over the years led to improvements and development of new clustering algorithms. However, algorithms that can cluster data with mixed variable types (continuous and categorical) remain limited, despite the abundance of data with mixed types particularly in the medical field. Among existing methods for mixed data, some posit unverifiable distributional assumptions or that the contributions of different variable types are not well balanced. We propose a two-step hybrid density- and partition-based algorithm (HyDaP) that can detect clusters after variables selection. The first step involves both density-based and partition-based algorithms to identify the data structure formed by continuous variables and recognize the important variables for clustering; the second step involves partition-based algorithm together with a novel dissimilarity measure we designed for mixed data to obtain clustering results. Simulations across various scenarios and data structures were conducted to examine the performance of the HyDaP algorithm compared to commonly used methods. We also applied the HyDaP algorithm on electronic health records to identify sepsis phenotypes.