 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Density- and Partition-based Clustering Algorithm for Data with Mixed-type Variables
Paper and Code
May 06, 2019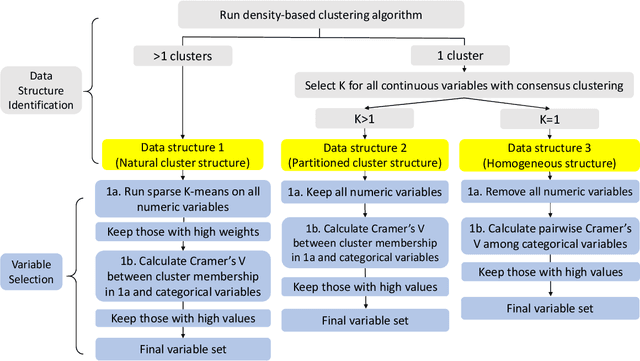

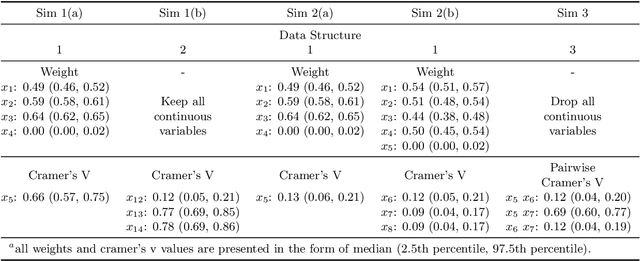
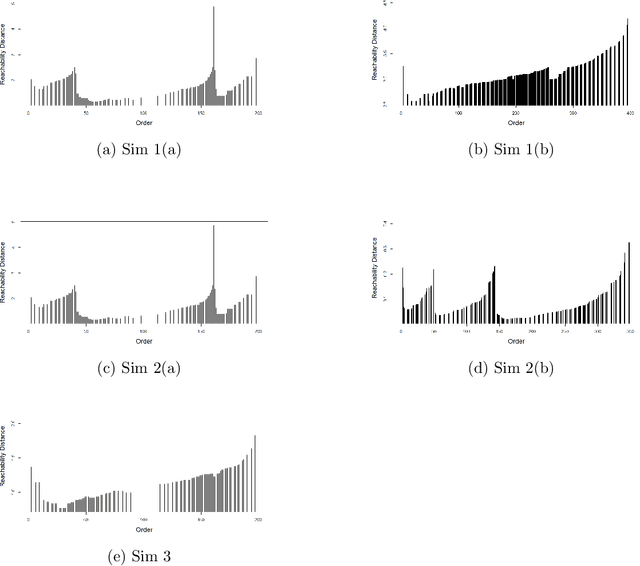
Clustering is an essential technique for discovering patterns in data. The steady increase in amount and complexity of data over the years led to improvements and development of new clustering algorithms. However, algorithms that can cluster data with mixed variable types (continuous and categorical) remain limited, despite the abundance of data with mixed types particularly in the medical field. Among existing methods for mixed data, some posit unverifiable distributional assumptions or that the contributions of different variable types are not well balanced. We propose a two-step hybrid density- and partition-based algorithm (HyDaP) that can detect clusters after variables selection. The first step involves both density-based and partition-based algorithms to identify the data structure formed by continuous variables and recognize the important variables for clustering; the second step involves partition-based algorithm together with a novel dissimilarity measure we designed for mixed data to obtain clustering results. Simulations across various scenarios and data structures were conducted to examine the performance of the HyDaP algorithm compared to commonly used methods. We also applied the HyDaP algorithm on electronic health records to identify sepsis phenotypes.