 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Practical Models for Isolated Word Visual Speech Recognition
Aug 25, 2025Visual speech recognition (VSR) systems decode spoken words from an input sequence using only the video data. Practical applications of such systems include medical assistance as well as human-machine interactions. A VSR system is typically employed in a complementary role in cases where the audio is corrupt or not available. In order to accurately predict the spoken words, these architectures often rely on deep neural networks in order to extract meaningful representations from the input sequence. While deep architectures achieve impressive recognition performance, relying on such models incurs significant computation costs which translates into increased resource demands in terms of hardware requirements and results in limited applicability in real-world scenarios where resources might be constrained. This factor prevents wider adoption and deployment of speech recognition systems in more practical applications. In this work, we aim to alleviate this issue by developing architectures for VSR that have low hardware costs. Following the standard two-network design paradigm, where one network handles visual feature extraction and another one utilizes the extracted features to classify the entire sequence, we develop lightweight end-to-end architectures by first benchmarking efficient models from the image classification literature, and then adopting lightweight block designs in a temporal convolution network backbone. We create several unified models with low resource requirements but strong recognition performance. Experiments on the largest public database for English words demonstrate the effectiveness and practicality of our developed models. Code and trained models will be made publicly available.
Lightweight Operations for Visual Speech Recognition
Feb 07, 2025Visual speech recognition (VSR), which decodes spoken words from video data, offers significant benefits, particularly when audio is unavailable. However, the high dimensionality of video data leads to prohibitive computational costs that demand powerful hardware, limiting VSR deployment on resource-constrained devices. This work addresses this limitation by developing lightweight VSR architectures. Leveraging efficient operation design paradigms, we create compact yet powerful models with reduced resource requirements and minimal accuracy loss. We train and evaluate our models on a large-scale public dataset for recognition of words from video sequences, demonstrating their effectiveness for practical applications. We also conduct an extensive array of ablative experiments to thoroughly analyze the size and complexity of each model. Code and trained models will be made publicly available.
Best Practices for a Handwritten Text Recognition System
Apr 17, 2024Handwritten text recognition has been developed rapidly in the recent years, following the rise of deep learning and its applications. Though deep learning methods provide notable boost in performance concerning text recognition, non-trivial deviation in performance can be detected even when small pre-processing or architectural/optimization elements are changed. This work follows a ``best practice'' rationale; highlight simple yet effective empirical practices that can further help training and provide well-performing handwritten text recognition systems. Specifically, we considered three basic aspects of a deep HTR system and we proposed simple yet effective solutions: 1) retain the aspect ratio of the images in the preprocessing step, 2) use max-pooling for converting the 3D feature map of CNN output into a sequence of features and 3) assist the training procedure via an additional CTC loss which acts as a shortcut on the max-pooled sequential features. Using these proposed simple modifications, one can attain close to state-of-the-art results, while considering a basic convolutional-recurrent (CNN+LSTM) architecture, for both IAM and RIMES datasets. Code is available at https://github.com/georgeretsi/HTR-best-practices/.
Keyword Spotting Simplified: A Segmentation-Free Approach using Character Counting and CTC re-scoring
Aug 07, 2023



Recent advances in segmentation-free keyword spotting treat this problem w.r.t. an object detection paradigm and borrow from state-of-the-art detection systems to simultaneously propose a word bounding box proposal mechanism and compute a corresponding representation. Contrary to the norm of such methods that rely on complex and large DNN models, we propose a novel segmentation-free system that efficiently scans a document image to find rectangular areas that include the query information. The underlying model is simple and compact, predicting character occurrences over rectangular areas through an implicitly learned scale map, trained on word-level annotated images. The proposed document scanning is then performed using this character counting in a cost-effective manner via integral images and binary search. Finally, the retrieval similarity by character counting is refined by a pyramidal representation and a CTC-based re-scoring algorithm, fully utilizing the trained CNN model. Experimental validation on two widely-used datasets shows that our method achieves state-of-the-art results outperforming the more complex alternatives, despite the simplicity of the underlying model.
Automatic Video Colorization using 3D Conditional Generative Adversarial Networks
May 08, 2019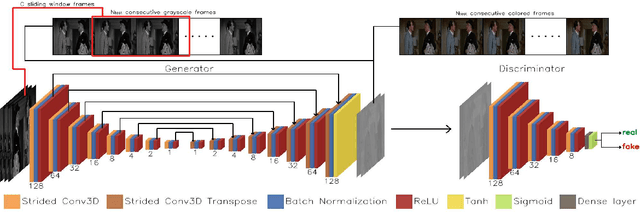
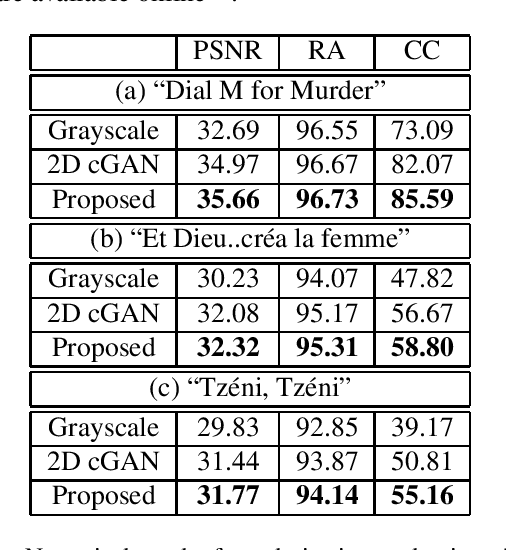


In this work, we present a method for automatic colorization of grayscale videos. The core of the method is a Generative Adversarial Network that is trained and tested on sequences of frames in a sliding window manner. Network convolutional and deconvolutional layers are three-dimensional, with frame height, width and time as the dimensions taken into account. Multiple chrominance estimates per frame are aggregated and combined with available luminance information to recreate a colored sequence. Colorization trials are run succesfully on a dataset of old black-and-white films. The usefulness of our method is also validated with numerical results, computed with a newly proposed metric that measures colorization consistency over a frame sequence.
Curriculum Learning of Visual Attribute Clusters for Multi-Task Classification
Jul 10, 2018
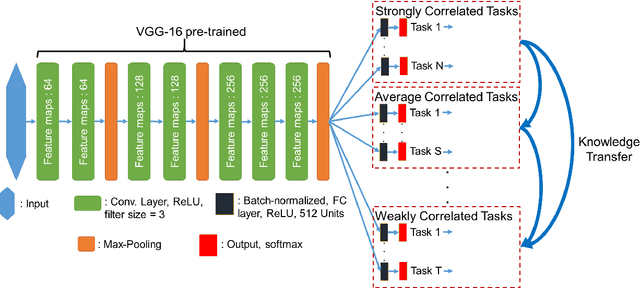
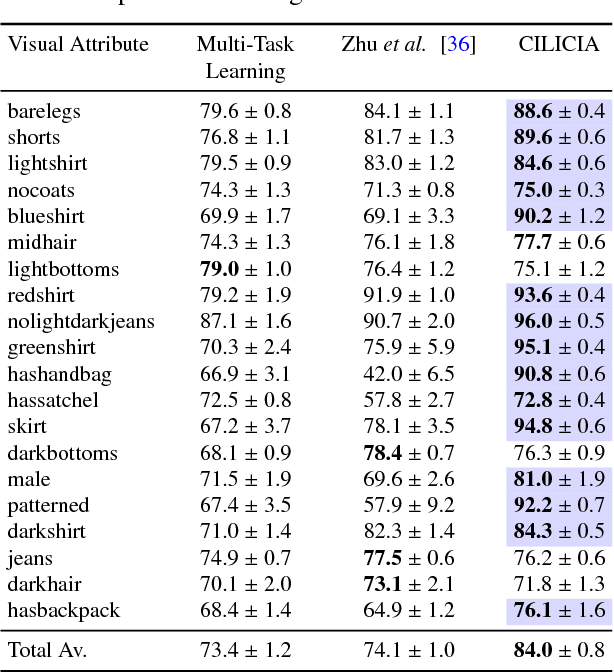
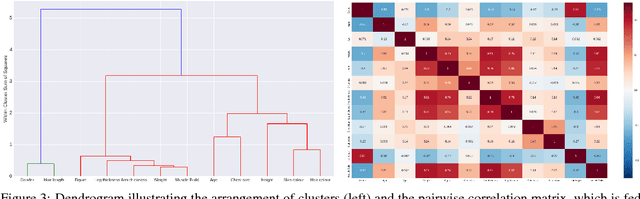
Visual attributes, from simple objects (e.g., backpacks, hats) to soft-biometrics (e.g., gender, height, clothing) have proven to be a powerful representational approach for many applications such as image description and human identification. In this paper, we introduce a novel method to combine the advantages of both multi-task and curriculum learning in a visual attribute classification framework. Individual tasks are grouped after performing hierarchical clustering based on their correlation. The clusters of tasks are learned in a curriculum learning setup by transferring knowledge between clusters. The learning process within each cluster is performed in a multi-task classification setup. By leveraging the acquired knowledge, we speed-up the process and improve performance. We demonstrate the effectiveness of our method via ablation studies and a detailed analysis of the covariates, on a variety of publicly available datasets of humans standing with their full-body visible. Extensive experimentation has proven that the proposed approach boosts the performance by 4% to 10%.
Human Activity Recognition Using Robust Adaptive Privileged Probabilistic Learning
Sep 19, 2017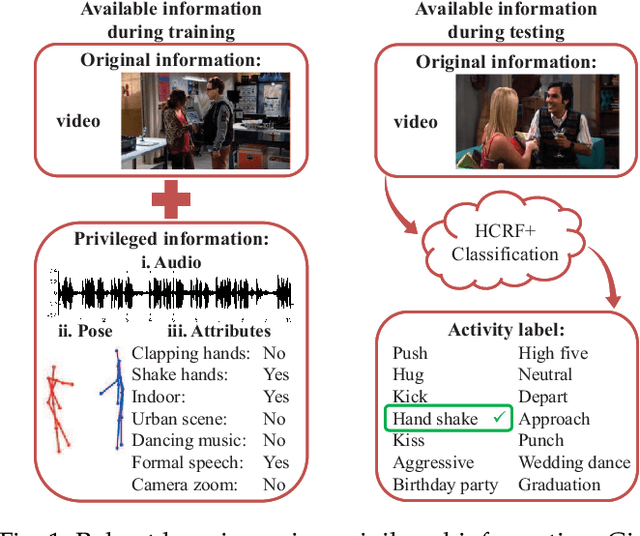
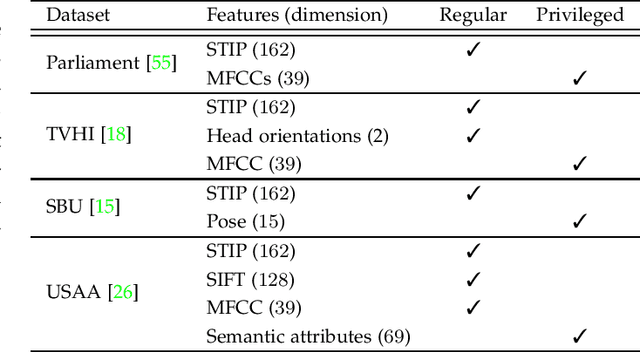
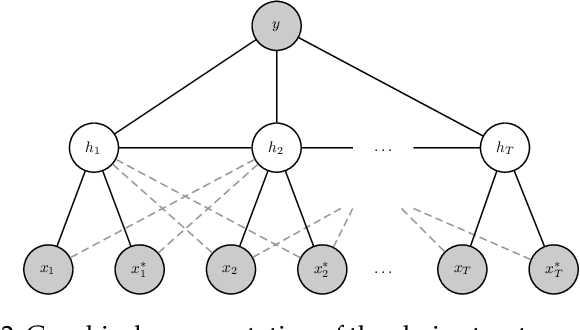
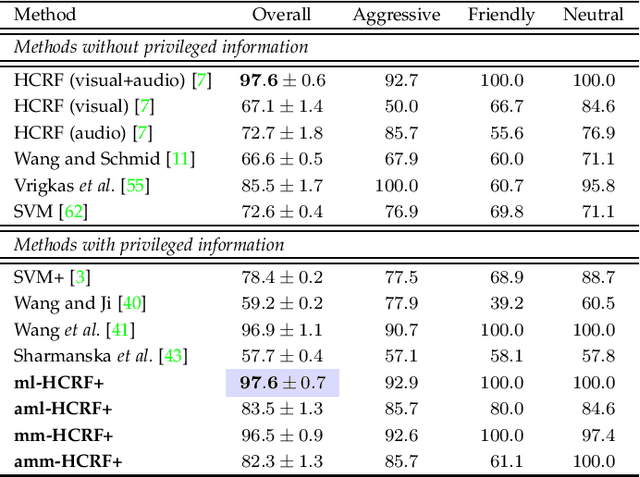
In this work, a novel method based on the learning using privileged information (LUPI) paradigm for recognizing complex human activities is proposed that handles missing information during testing. We present a supervised probabilistic approach that integrates LUPI into a hidden conditional random field (HCRF) model. The proposed model is called HCRF+ and may be trained using both maximum likelihood and maximum margin approaches. It employs a self-training technique for automatic estimation of the regularization parameters of the objective functions. Moreover, the method provides robustness to outliers (such as noise or missing data) by modeling the conditional distribution of the privileged information by a Student's \textit{t}-density function, which is naturally integrated into the HCRF+ framework. Different forms of privileged information were investigated. The proposed method was evaluated using four challenging publicly available datasets and the experimental results demonstrate its effectiveness with respect to the-state-of-the-art in the LUPI framework using both hand-crafted features and features extracted from a convolutional neural network.
Curriculum Learning for Multi-Task Classification of Visual Attributes
Aug 29, 2017
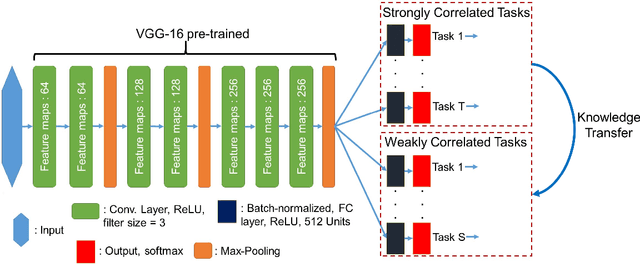
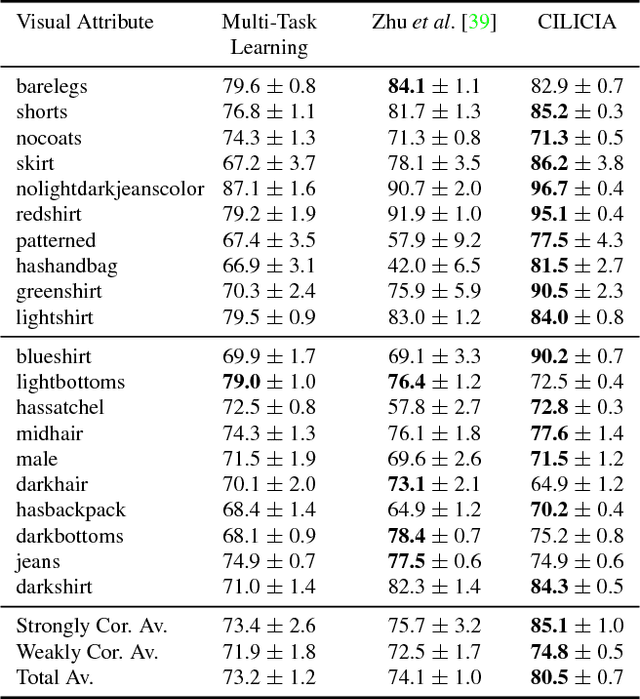
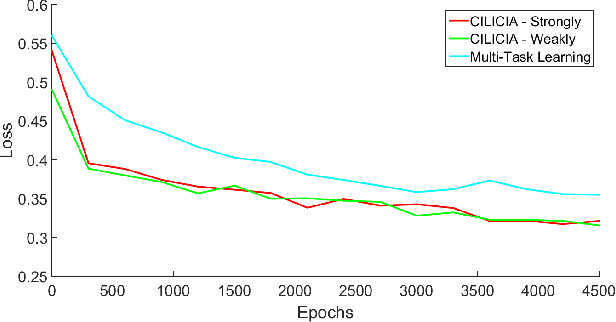
Visual attributes, from simple objects (e.g., backpacks, hats) to soft-biometrics (e.g., gender, height, clothing) have proven to be a powerful representational approach for many applications such as image description and human identification. In this paper, we introduce a novel method to combine the advantages of both multi-task and curriculum learning in a visual attribute classification framework. Individual tasks are grouped based on their correlation so that two groups of strongly and weakly correlated tasks are formed. The two groups of tasks are learned in a curriculum learning setup by transferring the acquired knowledge from the strongly to the weakly correlated. The learning process within each group though, is performed in a multi-task classification setup. The proposed method learns better and converges faster than learning all the tasks in a typical multi-task learning paradigm. We demonstrate the effectiveness of our approach on the publicly available, SoBiR, VIPeR and PETA datasets and report state-of-the-art results across the board.
Predicting Privileged Information for Height Estimation
Feb 09, 2017
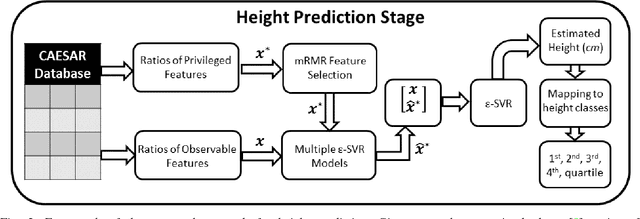
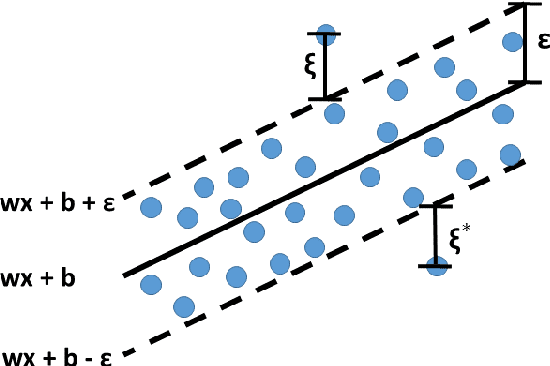
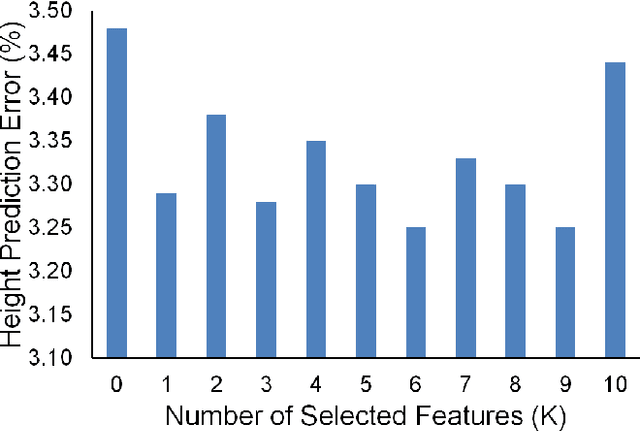
In this paper, we propose a novel regression-based method for employing privileged information to estimate the height using human metrology. The actual values of the anthropometric measurements are difficult to estimate accurately using state-of-the-art computer vision algorithms. Hence, we use ratios of anthropometric measurements as features. Since many anthropometric measurements are not available at test time in real-life scenarios, we employ a learning using privileged information (LUPI) framework in a regression setup. Instead of using the LUPI paradigm for regression in its original form (i.e., \epsilon-SVR+), we train regression models that predict the privileged information at test time. The predictions are then used, along with observable features, to perform height estimation. Once the height is estimated, a mapping to classes is performed. We demonstrate that the proposed approach can estimate the height better and faster than the \epsilon-SVR+ algorithm and report results for different genders and quartiles of humans.