 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHave it your way: Individualized Privacy Assignment for DP-SGD
Mar 29, 2023When training a machine learning model with differential privacy, one sets a privacy budget. This budget represents a maximal privacy violation that any user is willing to face by contributing their data to the training set. We argue that this approach is limited because different users may have different privacy expectations. Thus, setting a uniform privacy budget across all points may be overly conservative for some users or, conversely, not sufficiently protective for others. In this paper, we capture these preferences through individualized privacy budgets. To demonstrate their practicality, we introduce a variant of Differentially Private Stochastic Gradient Descent (DP-SGD) which supports such individualized budgets. DP-SGD is the canonical approach to training models with differential privacy. We modify its data sampling and gradient noising mechanisms to arrive at our approach, which we call Individualized DP-SGD (IDP-SGD). Because IDP-SGD provides privacy guarantees tailored to the preferences of individual users and their data points, we find it empirically improves privacy-utility trade-offs.
Personalized PATE: Differential Privacy for Machine Learning with Individual Privacy Guarantees
Feb 23, 2022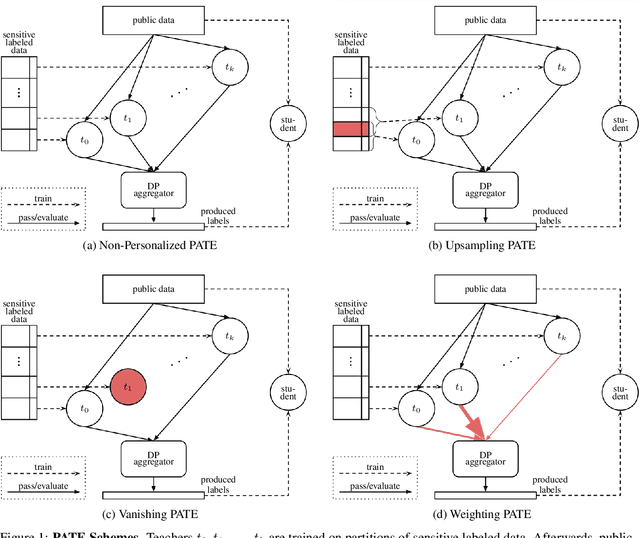
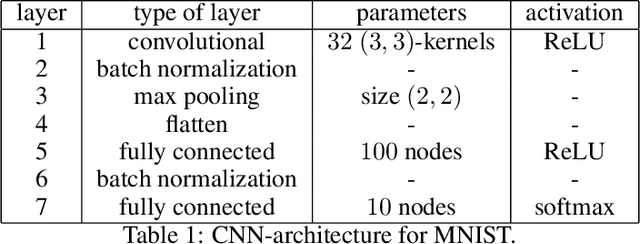

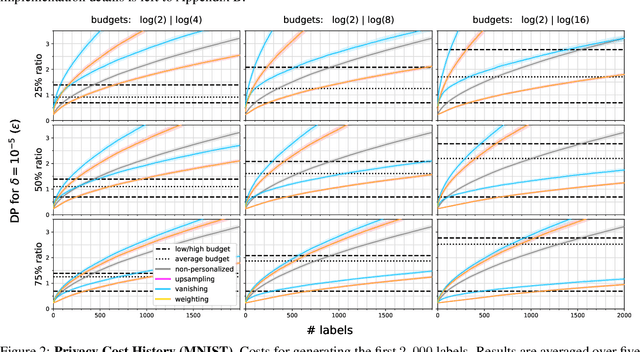
Applying machine learning (ML) to sensitive domains requires privacy protection of the underlying training data through formal privacy frameworks, such as differential privacy (DP). Yet, usually, the privacy of the training data comes at the costs of the resulting ML models' utility. One reason for this is that DP uses one homogeneous privacy budget epsilon for all training data points, which has to align with the strictest privacy requirement encountered among all data holders. In practice, different data holders might have different privacy requirements and data points of data holders with lower requirements could potentially contribute more information to the training process of the ML models. To account for this possibility, we propose three novel methods that extend the DP framework Private Aggregation of Teacher Ensembles (PATE) to support training an ML model with different personalized privacy guarantees within the training data. We formally describe the methods, provide theoretical analyses of their privacy bounds, and experimentally evaluate their effect on the final model's utility at the example of the MNIST and Adult income datasets. Our experiments show that our personalized privacy methods yield higher accuracy models than the non-personalized baseline. Thereby, our methods can improve the privacy-utility trade-off in scenarios in which different data holders consent to contribute their sensitive data at different privacy levels.