 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA toolbox for calculating objective image properties in aesthetics research
Aug 20, 2024Over the past two decades, researchers in the field of visual aesthetics have studied numerous quantitative (objective) image properties and how they relate to visual aesthetic appreciation. However, results are difficult to compare between research groups. One reason is that researchers use different sets of image properties in their studies. But even if the same properties are used, the image pre-processing techniques may differ and often researchers use their own customized scripts to calculate the image properties. To provide greater accessibility and comparability of research results in visual experimental aesthetics, we developed an open-access and easy-to-use toolbox (called the 'Aesthetics Toolbox'). The Toolbox allows users to calculate a well-defined set of quantitative image properties popular in contemporary research. The properties include lightness and color statistics, Fourier spectral properties, fractality, self-similarity, symmetry, as well as different entropy measures and CNN-based variances. Compatible with most devices, the Toolbox provides an intuitive click-and-drop web interface. In the Toolbox, we integrated the original scripts of four different research groups and translated them into Python 3. To ensure that results were consistent across analyses, we took care that results from the Python versions of the scripts were the same as those from the original scripts. The toolbox, detailed documentation, and a link to the cloud version are available via Github: https://github.com/RBartho/Aesthetics-Toolbox. In summary, we developed a toolbox that helps to standardize and simplify the calculation of quantitative image properties for visual aesthetics research.
Predicting beauty, liking, and aesthetic quality: A comparative analysis of image databases for visual aesthetics research
Jul 03, 2023



In the fields of Experimental and Computational Aesthetics, numerous image datasets have been created over the last two decades. In the present work, we provide a comparative overview of twelve image datasets that include aesthetic ratings (beauty, liking or aesthetic quality) and investigate the reproducibility of results across different datasets. Specifically, we examine how consistently the ratings can be predicted by using either (A) a set of 20 previously studied statistical image properties, or (B) the layers of a convolutional neural network developed for object recognition. Our findings reveal substantial variation in the predictability of aesthetic ratings across the different datasets. However, consistent similarities were found for datasets containing either photographs or paintings, suggesting different relevant features in the aesthetic evaluation of these two image genres. To our surprise, statistical image properties and the convolutional neural network predict aesthetic ratings with similar accuracy, highlighting a significant overlap in the image information captured by the two methods. Nevertheless, the discrepancies between the datasets call into question the generalizability of previous research findings on single datasets. Our study underscores the importance of considering multiple datasets to improve the validity and generalizability of research results in the fields of experimental and computational aesthetics.
Comparative Computational Analysis of Global Structure in Canonical, Non-Canonical and Non-Literary Texts
Aug 25, 2020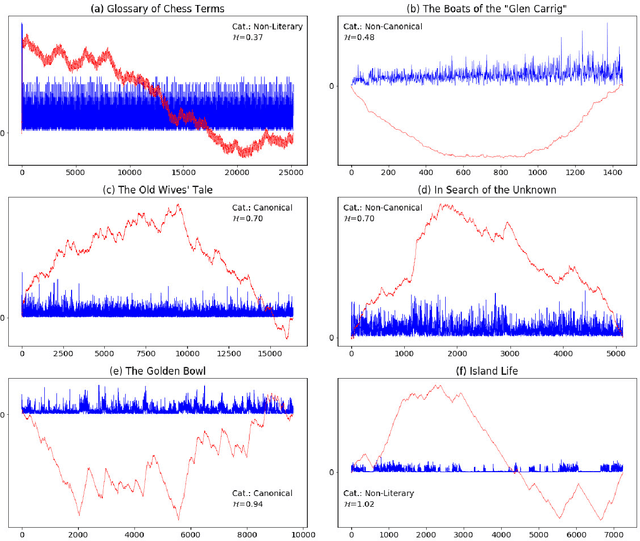
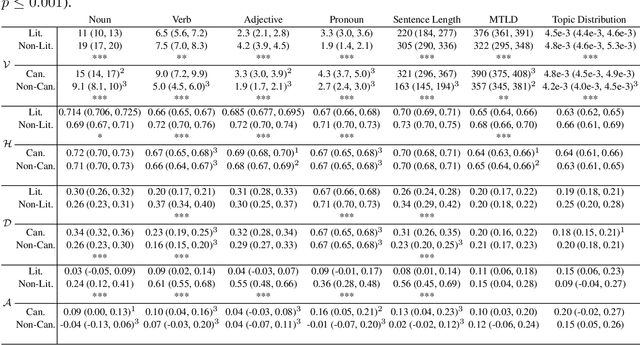

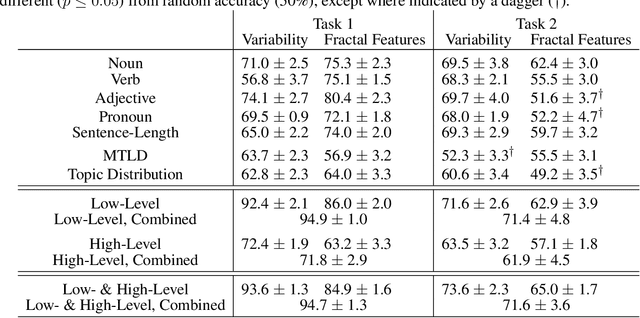
This study investigates global properties of literary and non-literary texts. Within the literary texts, a distinction is made between canonical and non-canonical works. The central hypothesis of the study is that the three text types (non-literary, literary/canonical and literary/non-canonical) exhibit systematic differences with respect to structural design features as correlates of aesthetic responses in readers. To investigate these differences, we compiled a corpus containing texts of the three categories of interest, the Jena Textual Aesthetics Corpus. Two aspects of global structure are investigated, variability and self-similar (fractal) patterns, which reflect long-range correlations along texts. We use four types of basic observations, (i) the frequency of POS-tags per sentence, (ii) sentence length, (iii) lexical diversity in chunks of text, and (iv) the distribution of topic probabilities in chunks of texts. These basic observations are grouped into two more general categories, (a) the low-level properties (i) and (ii), which are observed at the level of the sentence (reflecting linguistic decoding), and (b) the high-level properties (iii) and (iv), which are observed at the textual level (reflecting comprehension). The basic observations are transformed into time series, and these time series are subject to multifractal detrended fluctuation analysis (MFDFA). Our results show that low-level properties of texts are better discriminators than high-level properties, for the three text types under analysis. Canonical literary texts differ from non-canonical ones primarily in terms of variability. Fractality seems to be a universal feature of text, more pronounced in non-literary than in literary texts. Beyond the specific results of the study, we intend to open up new perspectives on the experimental study of textual aesthetics.
Color: A Crucial Factor for Aesthetic Quality Assessment in a Subjective Dataset of Paintings
Sep 19, 2016
Computational aesthetics is an emerging field of research which has attracted different research groups in the last few years. In this field, one of the main approaches to evaluate the aesthetic quality of paintings and photographs is a feature-based approach. Among the different features proposed to reach this goal, color plays an import role. In this paper, we introduce a novel dataset that consists of paintings of Western provenance from 36 well-known painters from the 15th to the 20th century. As a first step and to assess this dataset, using a classifier, we investigate the correlation between the subjective scores and two widely used features that are related to color perception and in different aesthetic quality assessment approaches. Results show a classification rate of up to 73% between the color features and the subjective scores.