 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Computational Analysis of Global Structure in Canonical, Non-Canonical and Non-Literary Texts
Paper and Code
Aug 25, 2020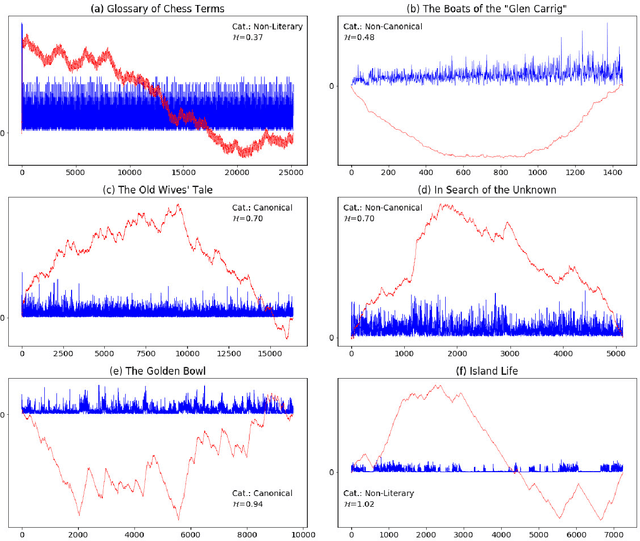
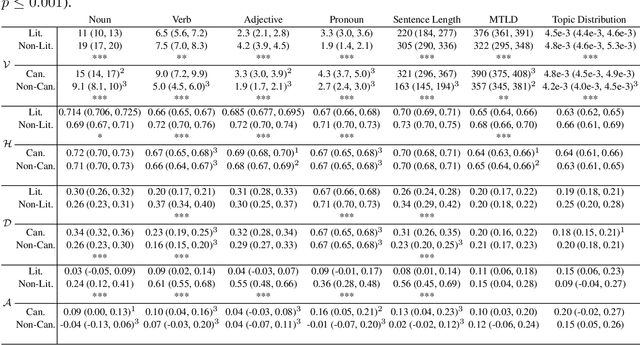

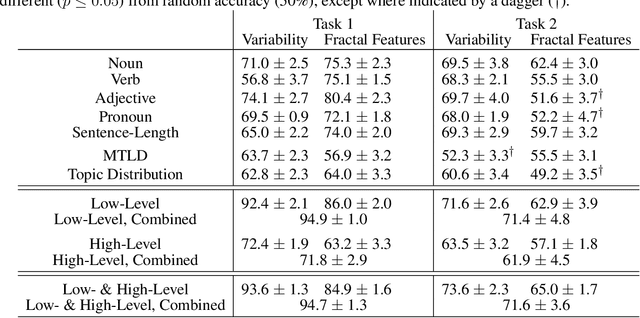
This study investigates global properties of literary and non-literary texts. Within the literary texts, a distinction is made between canonical and non-canonical works. The central hypothesis of the study is that the three text types (non-literary, literary/canonical and literary/non-canonical) exhibit systematic differences with respect to structural design features as correlates of aesthetic responses in readers. To investigate these differences, we compiled a corpus containing texts of the three categories of interest, the Jena Textual Aesthetics Corpus. Two aspects of global structure are investigated, variability and self-similar (fractal) patterns, which reflect long-range correlations along texts. We use four types of basic observations, (i) the frequency of POS-tags per sentence, (ii) sentence length, (iii) lexical diversity in chunks of text, and (iv) the distribution of topic probabilities in chunks of texts. These basic observations are grouped into two more general categories, (a) the low-level properties (i) and (ii), which are observed at the level of the sentence (reflecting linguistic decoding), and (b) the high-level properties (iii) and (iv), which are observed at the textual level (reflecting comprehension). The basic observations are transformed into time series, and these time series are subject to multifractal detrended fluctuation analysis (MFDFA). Our results show that low-level properties of texts are better discriminators than high-level properties, for the three text types under analysis. Canonical literary texts differ from non-canonical ones primarily in terms of variability. Fractality seems to be a universal feature of text, more pronounced in non-literary than in literary texts. Beyond the specific results of the study, we intend to open up new perspectives on the experimental study of textual aesthetics.