 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing the Robustness of Semantic Segmentation Models with Painting-by-Numbers
Oct 12, 2020
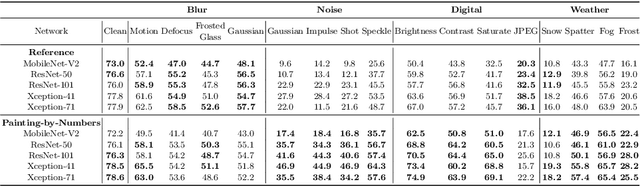

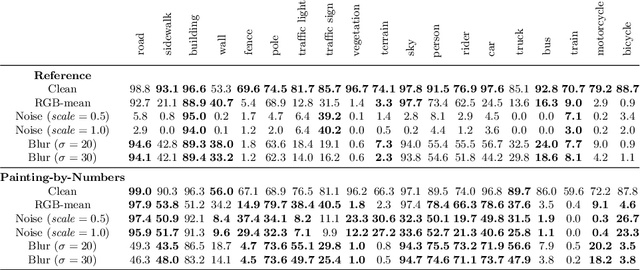
For safety-critical applications such as autonomous driving, CNNs have to be robust with respect to unavoidable image corruptions, such as image noise. While previous works addressed the task of robust prediction in the context of full-image classification, we consider it for dense semantic segmentation. We build upon an insight from image classification that output robustness can be improved by increasing the network-bias towards object shapes. We present a new training schema that increases this shape bias. Our basic idea is to alpha-blend a portion of the RGB training images with faked images, where each class-label is given a fixed, randomly chosen color that is not likely to appear in real imagery. This forces the network to rely more strongly on shape cues. We call this data augmentation technique ``Painting-by-Numbers''. We demonstrate the effectiveness of our training schema for DeepLabv3+ with various network backbones, MobileNet-V2, ResNets, and Xception, and evaluate it on the Cityscapes dataset. With respect to our 16 different types of image corruptions and 5 different network backbones, we are in 74% better than training with clean data. For cases where we are worse than a model trained without our training schema, it is mostly only marginally worse. However, for some image corruptions such as images with noise, we see a considerable performance gain of up to 25%.
Benchmarking the Robustness of Semantic Segmentation Models
Aug 14, 2019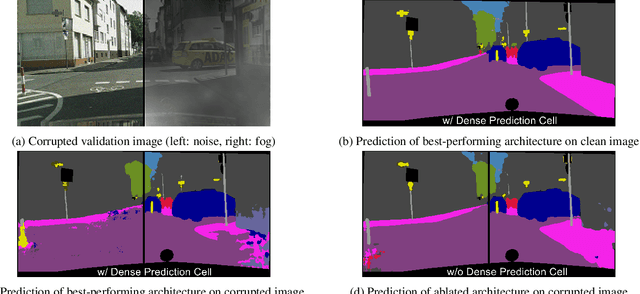


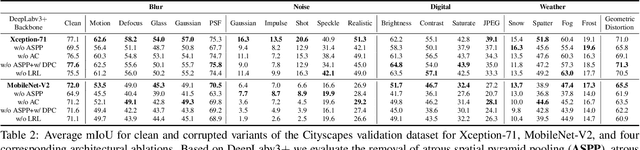
When designing a semantic segmentation module for a practical application, such as autonomous driving, it is crucial to understand the robustness of the module with respect to a wide range of image corruptions. While there are recent robustness studies for full-image classification, we are the first to present an exhaustive study for semantic segmentation, based on the state-of-the-art model DeepLabv3$+$. To increase the realism of our study, we utilize almost 200,000 images generated from Cityscapes and PASCAL VOC 2012, and we furthermore present a realistic noise model, imitating HDR camera noise. Based on the benchmark study we gain several new insights. Firstly, model robustness increases with model performance, in most cases. Secondly, some architecture properties affect robustness significantly, such as a Dense Prediction Cell which was designed to maximize performance on clean data only. Thirdly, to achieve good generalization with respect to various types of image noise, it is recommended to train DeepLabv3+ with our realistic noise model.