 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the Robustness of Semantic Segmentation Models
Paper and Code
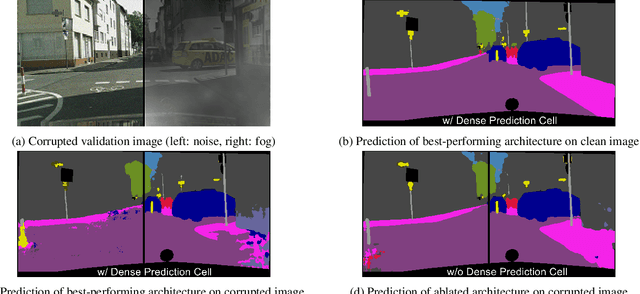


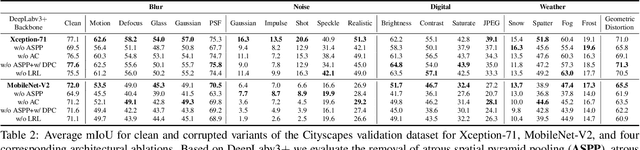
When designing a semantic segmentation module for a practical application, such as autonomous driving, it is crucial to understand the robustness of the module with respect to a wide range of image corruptions. While there are recent robustness studies for full-image classification, we are the first to present an exhaustive study for semantic segmentation, based on the state-of-the-art model DeepLabv3$+$. To increase the realism of our study, we utilize almost 200,000 images generated from Cityscapes and PASCAL VOC 2012, and we furthermore present a realistic noise model, imitating HDR camera noise. Based on the benchmark study we gain several new insights. Firstly, model robustness increases with model performance, in most cases. Secondly, some architecture properties affect robustness significantly, such as a Dense Prediction Cell which was designed to maximize performance on clean data only. Thirdly, to achieve good generalization with respect to various types of image noise, it is recommended to train DeepLabv3+ with our realistic noise model.