 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly-tight VC-dimension and pseudodimension bounds for piecewise linear neural networks
Oct 16, 2017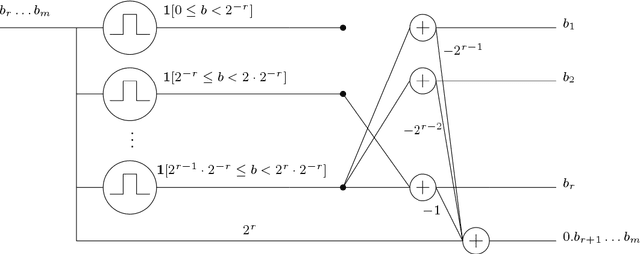
We prove new upper and lower bounds on the VC-dimension of deep neural networks with the ReLU activation function. These bounds are tight for almost the entire range of parameters. Letting $W$ be the number of weights and $L$ be the number of layers, we prove that the VC-dimension is $O(W L \log(W))$, and provide examples with VC-dimension $\Omega( W L \log(W/L) )$. This improves both the previously known upper bounds and lower bounds. In terms of the number $U$ of non-linear units, we prove a tight bound $\Theta(W U)$ on the VC-dimension. All of these bounds generalize to arbitrary piecewise linear activation functions, and also hold for the pseudodimensions of these function classes. Combined with previous results, this gives an intriguing range of dependencies of the VC-dimension on depth for networks with different non-linearities: there is no dependence for piecewise-constant, linear dependence for piecewise-linear, and no more than quadratic dependence for general piecewise-polynomial.