 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of SDRE to Achieve Gait Control in a Bipedal Robot for Knee-Type Exoskeleton Testing
Jun 05, 2025Exoskeletons are widely used in rehabilitation and industrial applications to assist human motion. However, direct human testing poses risks due to possible exoskeleton malfunctions and inconsistent movement replication. To provide a safer and more repeatable testing environment, this study employs a bipedal robot platform to reproduce human gait, allowing for controlled exoskeleton evaluations. A control strategy based on the State-Dependent Riccati Equation (SDRE) is formulated to achieve optimal torque control for accurate gait replication. The bipedal robot dynamics are represented using double pendulum model, where SDRE-optimized control inputs minimize deviations from human motion trajectories. To align with motor behavior constraints, a parameterized control method is introduced to simplify the control process while effectively replicating human gait. The proposed approach initially adopts a ramping trapezoidal velocity model, which is then adapted into a piecewise linear velocity-time representation through motor command overwriting. This modification enables finer control over gait phase transitions while ensuring compatibility with motor dynamics. The corresponding cost function optimizes the control parameters to minimize errors in joint angles, velocities, and torques relative to SDRE control result. By structuring velocity transitions in accordance with motor limitations, the method reduce the computational load associated with real-time control. Experimental results verify the feasibility of the proposed parameterized control method in reproducing human gait. The bipedal robot platform provides a reliable and repeatable testing mechanism for knee-type exoskeletons, offering insights into exoskeleton performance under controlled conditions.
ReynoldsFlow: Exquisite Flow Estimation via Reynolds Transport Theorem
Mar 06, 2025



Optical flow is a fundamental technique for motion estimation, widely applied in video stabilization, interpolation, and object tracking. Recent advancements in artificial intelligence (AI) have enabled deep learning models to leverage optical flow as an important feature for motion analysis. However, traditional optical flow methods rely on restrictive assumptions, such as brightness constancy and slow motion constraints, limiting their effectiveness in complex scenes. Deep learning-based approaches require extensive training on large domain-specific datasets, making them computationally demanding. Furthermore, optical flow is typically visualized in the HSV color space, which introduces nonlinear distortions when converted to RGB and is highly sensitive to noise, degrading motion representation accuracy. These limitations inherently constrain the performance of downstream models, potentially hindering object tracking and motion analysis tasks. To address these challenges, we propose Reynolds flow, a novel training-free flow estimation inspired by the Reynolds transport theorem, offering a principled approach to modeling complex motion dynamics. Beyond the conventional HSV-based visualization, denoted ReynoldsFlow, we introduce an alternative representation, ReynoldsFlow+, designed to improve flow visualization. We evaluate ReynoldsFlow and ReynoldsFlow+ across three video-based benchmarks: tiny object detection on UAVDB, infrared object detection on Anti-UAV, and pose estimation on GolfDB. Experimental results demonstrate that networks trained with ReynoldsFlow+ achieve state-of-the-art (SOTA) performance, exhibiting improved robustness and efficiency across all tasks.
Spectral Analysis for Semantic Segmentation with Applications on Feature Truncation and Weak Annotation
Dec 28, 2020


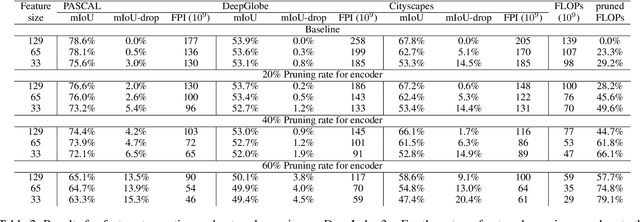
The current neural networks for semantic segmentation usually predict the pixel-wise semantics on the down-sampled grid of images to alleviate the computational cost for dense maps. However, the accuracy of resultant segmentation maps may also be down graded particularly in the regions near object boundaries. In this paper, we advance to have a deeper investigation on the sampling efficiency of the down-sampled grid. By applying the spectral analysis that analyze on the network back propagation process in frequency domain, we discover that cross-entropy is mainly contributed by the low-frequency components of segmentation maps, as well as that of the feature in CNNs. The network performance maintains as long as the resolution of the down sampled grid meets the cut-off frequency. Such finding leads us to propose a simple yet effective feature truncation method that limits the feature size in CNNs and removes the associated high-frequency components. This method can not only reduce the computational cost but also maintain the performance of semantic segmentation networks. Moreover, one can seamlessly integrate this method with the typical network pruning approaches for further model reduction. On the other hand, we propose to employee a block-wise weak annotation for semantic segmentation that captures the low-frequency information of the segmentation map and is easy to collect. Using the proposed analysis scheme, one can easily estimate the efficacy of the block-wise annotation and the feature truncation method.