 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
Evaluating Self-Supervised Speech Representations for Indigenous American Languages
Oct 08, 2023

The application of self-supervision to speech representation learning has garnered significant interest in recent years, due to its scalability to large amounts of unlabeled data. However, much progress, both in terms of pre-training and downstream evaluation, has remained concentrated in monolingual models that only consider English. Few models consider other languages, and even fewer consider indigenous ones. In our submission to the New Language Track of the ASRU 2023 ML-SUPERB Challenge, we present an ASR corpus for Quechua, an indigenous South American Language. We benchmark the efficacy of large SSL models on Quechua, along with 6 other indigenous languages such as Guarani and Bribri, on low-resource ASR. Our results show surprisingly strong performance by state-of-the-art SSL models, showing the potential generalizability of large-scale models to real-world data.
Benchmarking Azerbaijani Neural Machine Translation
Jul 29, 2022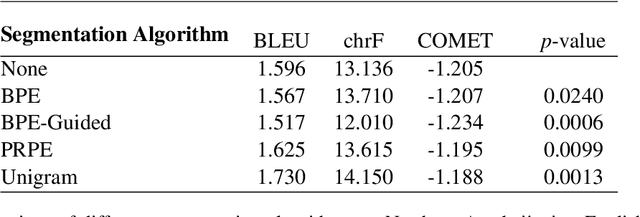


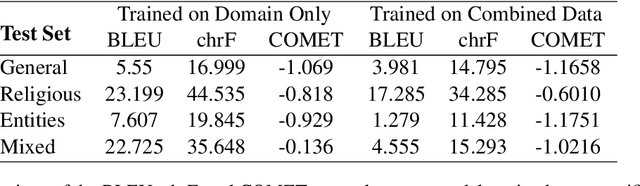
Little research has been done on Neural Machine Translation (NMT) for Azerbaijani. In this paper, we benchmark the performance of Azerbaijani-English NMT systems on a range of techniques and datasets. We evaluate which segmentation techniques work best on Azerbaijani translation and benchmark the performance of Azerbaijani NMT models across several domains of text. Our results show that while Unigram segmentation improves NMT performance and Azerbaijani translation models scale better with dataset quality than quantity, cross-domain generalization remains a challenge