Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Azerbaijani Neural Machine Translation
Paper and Code
Jul 29, 2022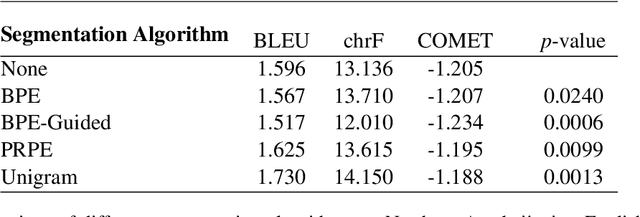


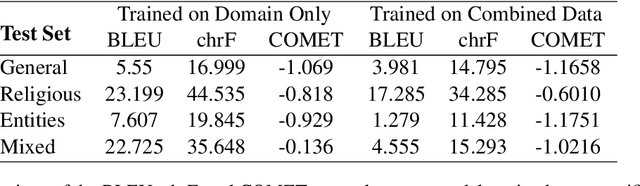
Little research has been done on Neural Machine Translation (NMT) for Azerbaijani. In this paper, we benchmark the performance of Azerbaijani-English NMT systems on a range of techniques and datasets. We evaluate which segmentation techniques work best on Azerbaijani translation and benchmark the performance of Azerbaijani NMT models across several domains of text. Our results show that while Unigram segmentation improves NMT performance and Azerbaijani translation models scale better with dataset quality than quantity, cross-domain generalization remains a challenge
* Published in The International Conference and Workshop on
Agglutinative Language Technologies as a Challenge for NLP (ALTNLP)
https://www.altnlp.org
View paper on