 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Sensitivity of the Lasso to the Number of Predictor Variables
May 27, 2016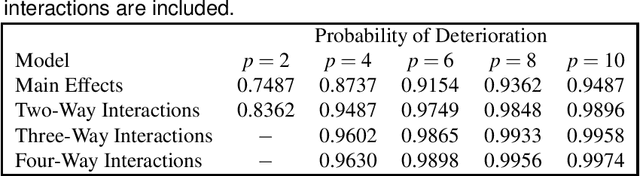
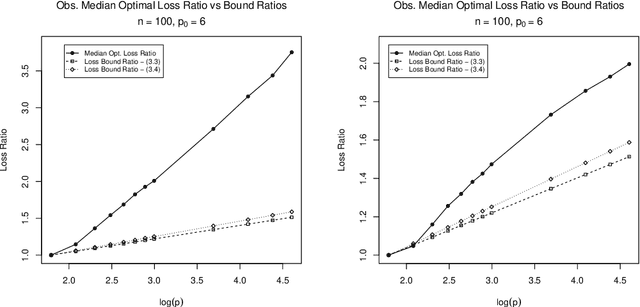
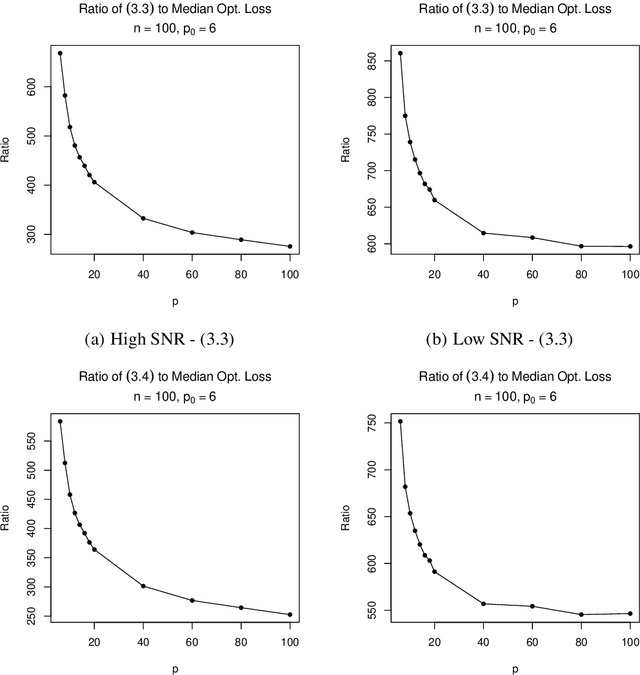

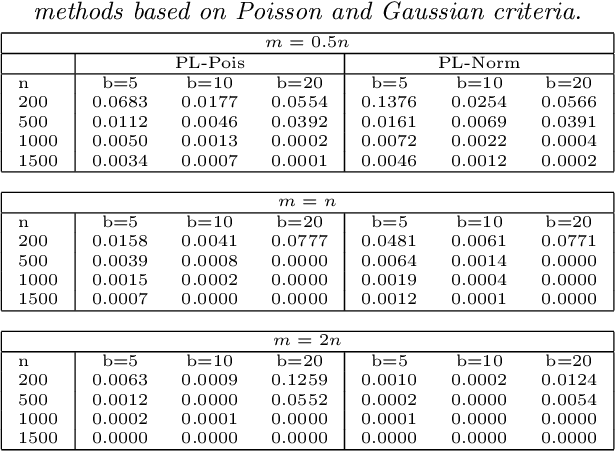
The Lasso is a computationally efficient regression regularization procedure that can produce sparse estimators when the number of predictors (p) is large. Oracle inequalities provide probability loss bounds for the Lasso estimator at a deterministic choice of the regularization parameter. These bounds tend to zero if p is appropriately controlled, and are thus commonly cited as theoretical justification for the Lasso and its ability to handle high-dimensional settings. Unfortunately, in practice the regularization parameter is not selected to be a deterministic quantity, but is instead chosen using a random, data-dependent procedure. To address this shortcoming of previous theoretical work, we study the loss of the Lasso estimator when tuned optimally for prediction. Assuming orthonormal predictors and a sparse true model, we prove that the probability that the best possible predictive performance of the Lasso deteriorates as p increases is positive and can be arbitrarily close to one given a sufficiently high signal to noise ratio and sufficiently large p. We further demonstrate empirically that the amount of deterioration in performance can be far worse than the oracle inequalities suggest and provide a real data example where deterioration is observed.
Consistent Biclustering
Jan 08, 2016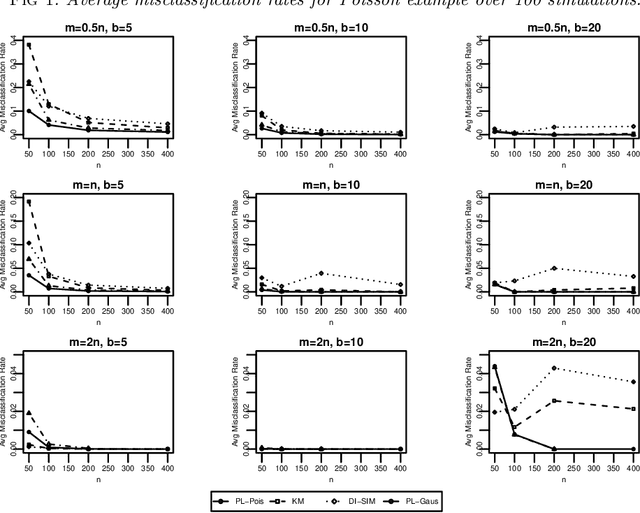
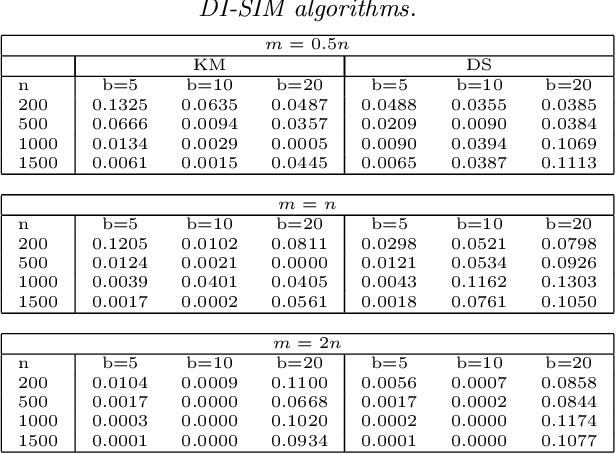
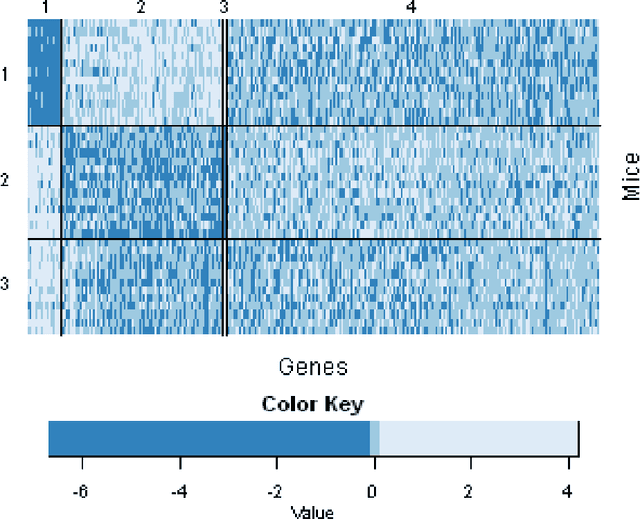
Biclustering, the process of simultaneously clustering the rows and columns of a data matrix, is a popular and effective tool for finding structure in a high-dimensional dataset. Many biclustering procedures appear to work well in practice, but most do not have associated consistency guarantees. To address this shortcoming, we propose a new biclustering procedure based on profile likelihood. The procedure applies to a broad range of data modalities, including binary, count, and continuous observations. We prove that the procedure recovers the true row and column classes when the dimensions of the data matrix tend to infinity, even if the functional form of the data distribution is misspecified. The procedure requires computing a combinatorial search, which can be expensive in practice. Rather than performing this search directly, we propose a new heuristic optimization procedure based on the Kernighan-Lin heuristic, which has nice computational properties and performs well in simulations. We demonstrate our procedure with applications to congressional voting records, and microarray analysis.
Efficiency for Regularization Parameter Selection in Penalized Likelihood Estimation of Misspecified Models
Feb 08, 2013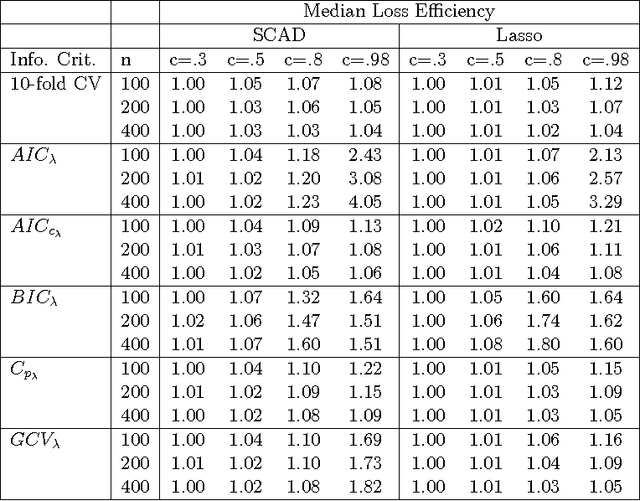
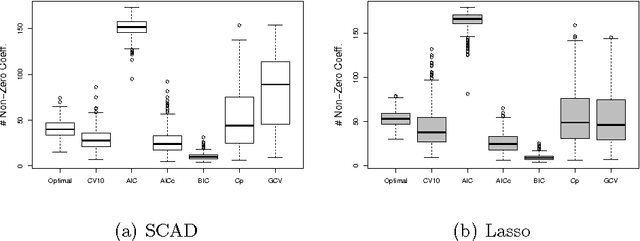
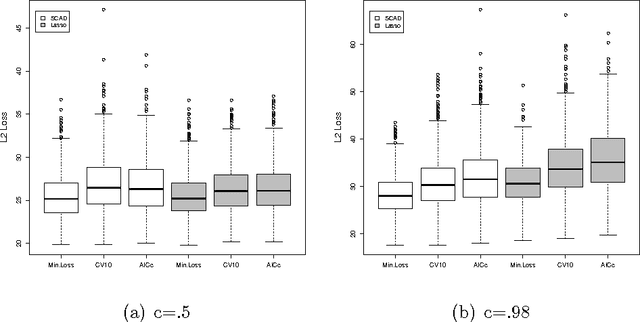
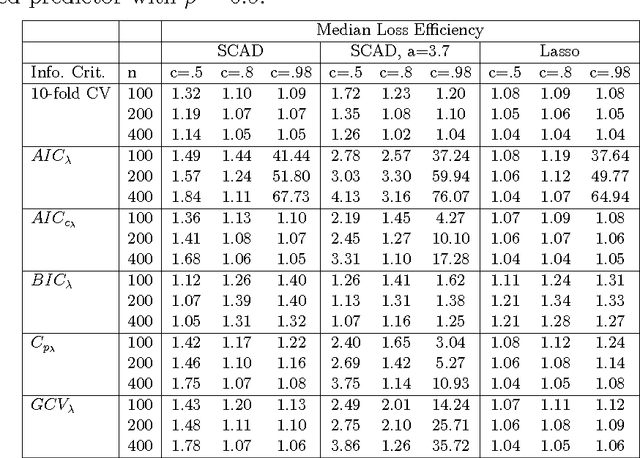
It has been shown that AIC-type criteria are asymptotically efficient selectors of the tuning parameter in non-concave penalized regression methods under the assumption that the population variance is known or that a consistent estimator is available. We relax this assumption to prove that AIC itself is asymptotically efficient and we study its performance in finite samples. In classical regression, it is known that AIC tends to select overly complex models when the dimension of the maximum candidate model is large relative to the sample size. Simulation studies suggest that AIC suffers from the same shortcomings when used in penalized regression. We therefore propose the use of the classical corrected AIC (AICc) as an alternative and prove that it maintains the desired asymptotic properties. To broaden our results, we further prove the efficiency of AIC for penalized likelihood methods in the context of generalized linear models with no dispersion parameter. Similar results exist in the literature but only for a restricted set of candidate models. By employing results from the classical literature on maximum-likelihood estimation in misspecified models, we are able to establish this result for a general set of candidate models. We use simulations to assess the performance of AIC and AICc, as well as that of other selectors, in finite samples for both SCAD-penalized and Lasso regressions and a real data example is considered.