 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFS-Depth: Focal-and-Scale Depth Estimation from a Single Image in Unseen Indoor Scene
Jul 27, 2023


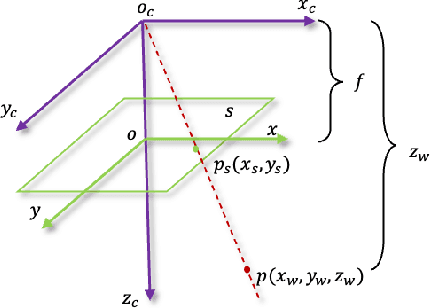
It has long been an ill-posed problem to predict absolute depth maps from single images in real (unseen) indoor scenes. We observe that it is essentially due to not only the scale-ambiguous problem but also the focal-ambiguous problem that decreases the generalization ability of monocular depth estimation. That is, images may be captured by cameras of different focal lengths in scenes of different scales. In this paper, we develop a focal-and-scale depth estimation model to well learn absolute depth maps from single images in unseen indoor scenes. First, a relative depth estimation network is adopted to learn relative depths from single images with diverse scales/semantics. Second, multi-scale features are generated by mapping a single focal length value to focal length features and concatenating them with intermediate features of different scales in relative depth estimation. Finally, relative depths and multi-scale features are jointly fed into an absolute depth estimation network. In addition, a new pipeline is developed to augment the diversity of focal lengths of public datasets, which are often captured with cameras of the same or similar focal lengths. Our model is trained on augmented NYUDv2 and tested on three unseen datasets. Our model considerably improves the generalization ability of depth estimation by 41%/13% (RMSE) with/without data augmentation compared with five recent SOTAs and well alleviates the deformation problem in 3D reconstruction. Notably, our model well maintains the accuracy of depth estimation on original NYUDv2.