 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Bias in Inverting Random Sampling Matrices with Application to Sub-sampled Newton
Feb 19, 2025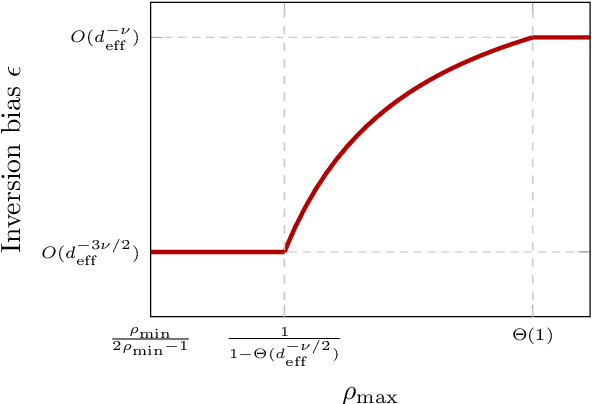
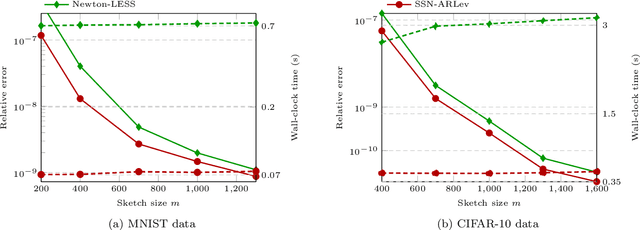
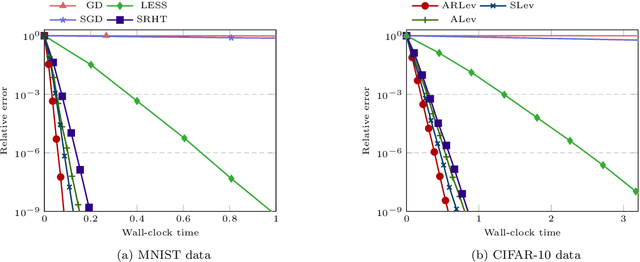
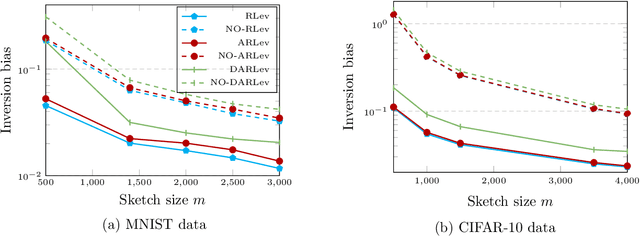
A substantial body of work in machine learning (ML) and randomized numerical linear algebra (RandNLA) has exploited various sorts of random sketching methodologies, including random sampling and random projection, with much of the analysis using Johnson--Lindenstrauss and subspace embedding techniques. Recent studies have identified the issue of inversion bias -- the phenomenon that inverses of random sketches are not unbiased, despite the unbiasedness of the sketches themselves. This bias presents challenges for the use of random sketches in various ML pipelines, such as fast stochastic optimization, scalable statistical estimators, and distributed optimization. In the context of random projection, the inversion bias can be easily corrected for dense Gaussian projections (which are, however, too expensive for many applications). Recent work has shown how the inversion bias can be corrected for sparse sub-gaussian projections. In this paper, we show how the inversion bias can be corrected for random sampling methods, both uniform and non-uniform leverage-based, as well as for structured random projections, including those based on the Hadamard transform. Using these results, we establish problem-independent local convergence rates for sub-sampled Newton methods.
Analysis and Approximate Inference of Large and Dense Random Kronecker Graphs
Jun 14, 2023Random graph models are playing an increasingly important role in science and industry, and finds their applications in a variety of fields ranging from social and traffic networks, to recommendation systems and molecular genetics. In this paper, we perform an in-depth analysis of the random Kronecker graph model proposed in \cite{leskovec2010kronecker}, when the number of graph vertices $N$ is large. Built upon recent advances in random matrix theory, we show, in the dense regime, that the random Kronecker graph adjacency matrix follows approximately a signal-plus-noise model, with a small-rank (of order at most $\log N$) signal matrix that is linear in the graph parameters and a random noise matrix having a quarter-circle-form singular value distribution. This observation allows us to propose a ``denoise-and-solve'' meta algorithm to approximately infer the graph parameters, with reduced computational complexity and (asymptotic) performance guarantee. Numerical experiments of graph inference and graph classification on both synthetic and realistic graphs are provided to support the advantageous performance of the proposed approach.