 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Generative Models Evaluation with Masked Autoencoder
Mar 17, 2025
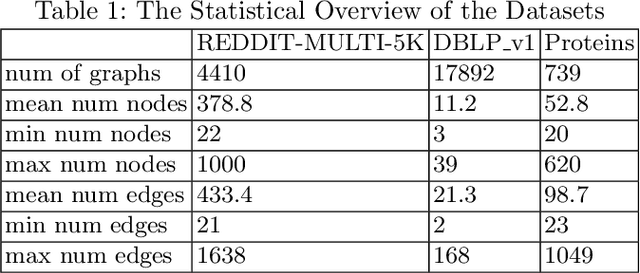
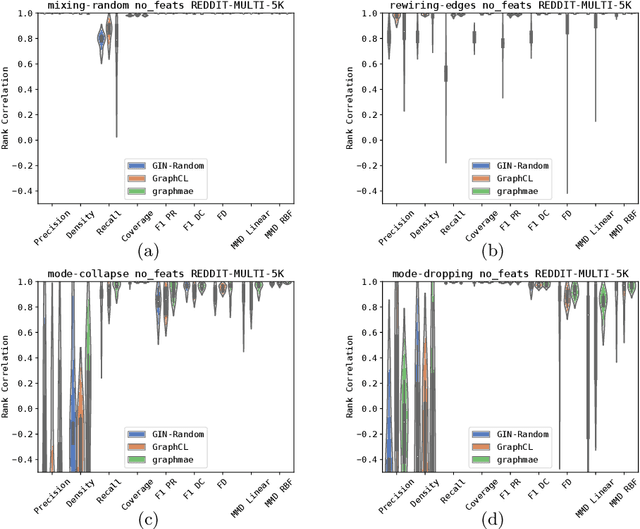
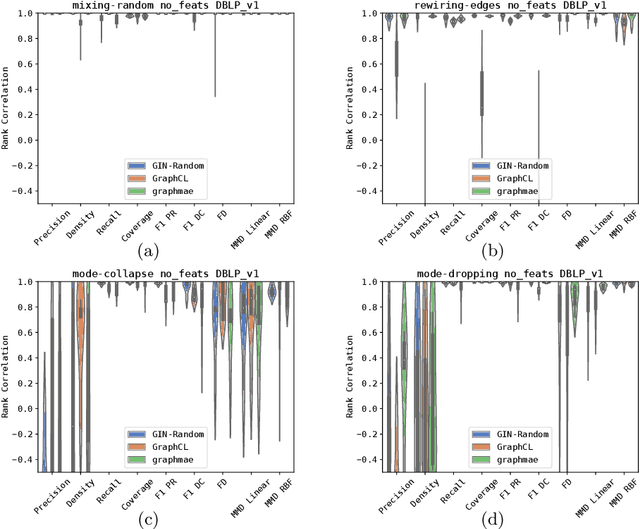
In recent years, numerous graph generative models (GGMs) have been proposed. However, evaluating these models remains a considerable challenge, primarily due to the difficulty in extracting meaningful graph features that accurately represent real-world graphs. The traditional evaluation techniques, which rely on graph statistical properties like node degree distribution, clustering coefficients, or Laplacian spectrum, overlook node features and lack scalability. There are newly proposed deep learning-based methods employing graph random neural networks or contrastive learning to extract graph features, demonstrating superior performance compared to traditional statistical methods, but their experimental results also demonstrate that these methods do not always working well across different metrics. Although there are overlaps among these metrics, they are generally not interchangeable, each evaluating generative models from a different perspective. In this paper, we propose a novel method that leverages graph masked autoencoders to effectively extract graph features for GGM evaluations. We conduct extensive experiments on graphs and empirically demonstrate that our method can be more reliable and effective than previously proposed methods across a number of GGM evaluation metrics, such as "Fr\'echet Distance (FD)" and "MMD Linear". However, no single method stands out consistently across all metrics and datasets. Therefore, this study also aims to raise awareness of the significance and challenges associated with GGM evaluation techniques, especially in light of recent advances in generative models.
A Review of DeepSeek Models' Key Innovative Techniques
Mar 14, 2025DeepSeek-V3 and DeepSeek-R1 are leading open-source Large Language Models (LLMs) for general-purpose tasks and reasoning, achieving performance comparable to state-of-the-art closed-source models from companies like OpenAI and Anthropic -- while requiring only a fraction of their training costs. Understanding the key innovative techniques behind DeepSeek's success is crucial for advancing LLM research. In this paper, we review the core techniques driving the remarkable effectiveness and efficiency of these models, including refinements to the transformer architecture, innovations such as Multi-Head Latent Attention and Mixture of Experts, Multi-Token Prediction, the co-design of algorithms, frameworks, and hardware, the Group Relative Policy Optimization algorithm, post-training with pure reinforcement learning and iterative training alternating between supervised fine-tuning and reinforcement learning. Additionally, we identify several open questions and highlight potential research opportunities in this rapidly advancing field.
A Systematic Evaluation of Generative Models on Tabular Transportation Data
Feb 13, 2025The sharing of large-scale transportation data is beneficial for transportation planning and policymaking. However, it also raises significant security and privacy concerns, as the data may include identifiable personal information, such as individuals' home locations. To address these concerns, synthetic data generation based on real transportation data offers a promising solution that allows privacy protection while potentially preserving data utility. Although there are various synthetic data generation techniques, they are often not tailored to the unique characteristics of transportation data, such as the inherent structure of transportation networks formed by all trips in the datasets. In this paper, we use New York City taxi data as a case study to conduct a systematic evaluation of the performance of widely used tabular data generative models. In addition to traditional metrics such as distribution similarity, coverage, and privacy preservation, we propose a novel graph-based metric tailored specifically for transportation data. This metric evaluates the similarity between real and synthetic transportation networks, providing potentially deeper insights into their structural and functional alignment. We also introduced an improved privacy metric to address the limitations of the commonly-used one. Our experimental results reveal that existing tabular data generative models often fail to perform as consistently as claimed in the literature, particularly when applied to transportation data use cases. Furthermore, our novel graph metric reveals a significant gap between synthetic and real data. This work underscores the potential need to develop generative models specifically tailored to take advantage of the unique characteristics of emerging domains, such as transportation.