 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Crash: Hijacking Your Autonomous Vehicle for Fun and Profit
Feb 06, 2026Autonomous Vehicles (AVs), especially vision-based AVs, are rapidly being deployed without human operators. As AVs operate in safety-critical environments, understanding their robustness in an adversarial environment is an important research problem. Prior physical adversarial attacks on vision-based autonomous vehicles predominantly target immediate safety failures (e.g., a crash, a traffic-rule violation, or a transient lane departure) by inducing a short-lived perception or control error. This paper shows a qualitatively different risk: a long-horizon route integrity compromise, where an attacker gradually steers a victim AV away from its intended route and into an attacker-chosen destination while the victim continues to drive "normally." This will not pose a danger to the victim vehicle itself, but also to potential passengers sitting inside the vehicle. In this paper, we design and implement the first adversarial framework, called JackZebra, that performs route-level hijacking of a vision-based end-to-end driving stack using a physically plausible attacker vehicle with a reconfigurable display mounted on the rear. The central challenge is temporal persistence: adversarial influence must remain effective in changing viewpoints, lighting, weather, traffic, and the victim's continual replanning -- without triggering conspicuous failures. Our key insight is to treat route hijacking as a closed-loop control problem and to convert adversarial patches into steering primitives that can be selected online via an interactive adjustment loop. Our adversarial patches are also carefully designed against worst-case background and sensor variations so that the adversarial impacts on the victim. Our evaluation shows that JackZebra can successfully hijack victim vehicles to deviate from original routes and stop at adversarial destinations with a high success rate.
A Systematic Evaluation of Generative Models on Tabular Transportation Data
Feb 13, 2025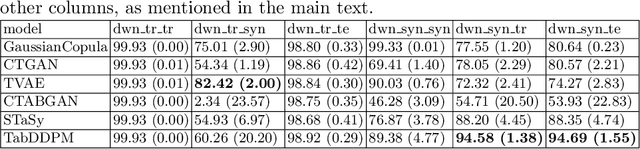



The sharing of large-scale transportation data is beneficial for transportation planning and policymaking. However, it also raises significant security and privacy concerns, as the data may include identifiable personal information, such as individuals' home locations. To address these concerns, synthetic data generation based on real transportation data offers a promising solution that allows privacy protection while potentially preserving data utility. Although there are various synthetic data generation techniques, they are often not tailored to the unique characteristics of transportation data, such as the inherent structure of transportation networks formed by all trips in the datasets. In this paper, we use New York City taxi data as a case study to conduct a systematic evaluation of the performance of widely used tabular data generative models. In addition to traditional metrics such as distribution similarity, coverage, and privacy preservation, we propose a novel graph-based metric tailored specifically for transportation data. This metric evaluates the similarity between real and synthetic transportation networks, providing potentially deeper insights into their structural and functional alignment. We also introduced an improved privacy metric to address the limitations of the commonly-used one. Our experimental results reveal that existing tabular data generative models often fail to perform as consistently as claimed in the literature, particularly when applied to transportation data use cases. Furthermore, our novel graph metric reveals a significant gap between synthetic and real data. This work underscores the potential need to develop generative models specifically tailored to take advantage of the unique characteristics of emerging domains, such as transportation.