 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search for Inversion
Jan 05, 2022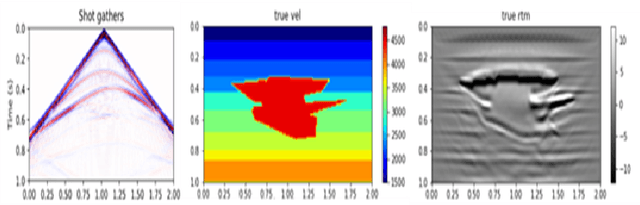

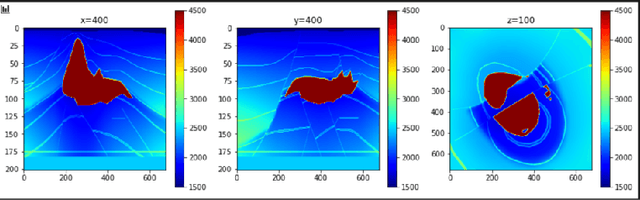

Over the year, people have been using deep learning to tackle inversion problems, and we see the framework has been applied to build relationship between recording wavefield and velocity (Yang et al., 2016). Here we will extend the work from 2 perspectives, one is deriving a more appropriate loss function, as we now, pixel-2-pixel comparison might not be the best choice to characterize image structure, and we will elaborate on how to construct cost function to capture high level feature to enhance the model performance. Another dimension is searching for the more appropriate neural architecture, which is a subset of an even bigger picture, the automatic machine learning, or AutoML. There are several famous networks, U-net, ResNet (He et al., 2016) and DenseNet (Huang et al., 2017), and they achieve phenomenal results for certain problems, yet it's hard to argue they are the best for inversion problems without thoroughly searching within certain space. Here we will be showing our architecture search results for inversion.
Deep Learning Approach in Automatic Iceberg - Ship Detection with SAR Remote Sensing Data
Dec 09, 2018
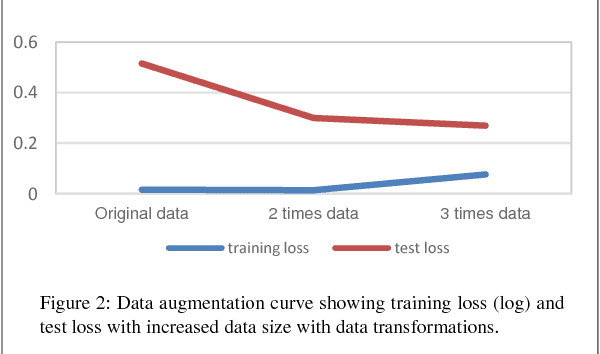


Deep Learning is gaining traction with geophysics community to understand subsurface structures, such as fault detection or salt body in seismic data. This study describes using deep learning method for iceberg or ship recognition with synthetic aperture radar (SAR) data. Drifting icebergs pose a potential threat to activities offshore around the Arctic, including for both ship navigation and oil rigs. Advancement of satellite imagery using weather-independent cross-polarized radar has enabled us to monitor and delineate icebergs and ships, however a human component is needed to classify the images. Here we present Transfer Learning, a convolutional neural network (CNN) designed to work with a limited training data and features, while demonstrating its effectiveness in this problem. Key aspect of the approach is data augmentation and stacking of multiple outputs, resulted in a significant boost in accuracy (logarithmic score of 0.1463). This algorithm has been tested through participation at the Statoil/C-Core Kaggle competition.
An Effective Way to Improve YouTube-8M Classification Accuracy in Google Cloud Platform
Jun 26, 2017
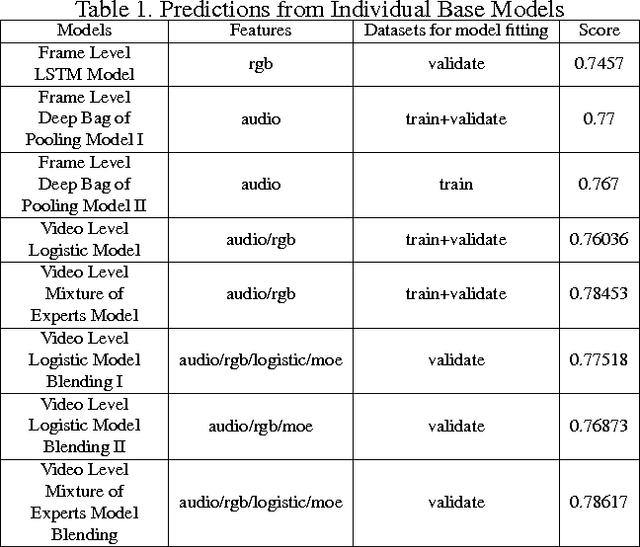
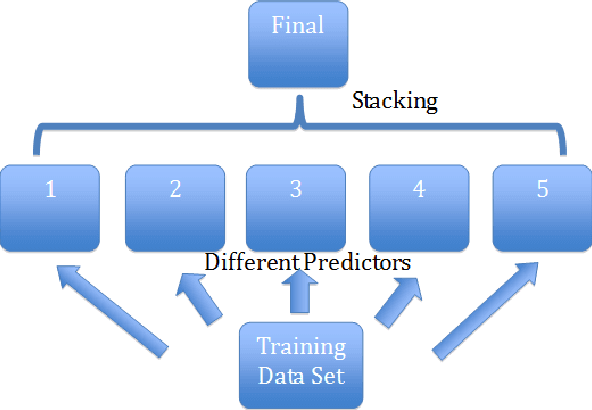
Large-scale datasets have played a significant role in progress of neural network and deep learning areas. YouTube-8M is such a benchmark dataset for general multi-label video classification. It was created from over 7 million YouTube videos (450,000 hours of video) and includes video labels from a vocabulary of 4716 classes (3.4 labels/video on average). It also comes with pre-extracted audio & visual features from every second of video (3.2 billion feature vectors in total). Google cloud recently released the datasets and organized 'Google Cloud & YouTube-8M Video Understanding Challenge' on Kaggle. Competitors are challenged to develop classification algorithms that assign video-level labels using the new and improved Youtube-8M V2 dataset. Inspired by the competition, we started exploration of audio understanding and classification using deep learning algorithms and ensemble methods. We built several baseline predictions according to the benchmark paper and public github tensorflow code. Furthermore, we improved global prediction accuracy (GAP) from base level 77% to 80.7% through approaches of ensemble.