 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEqCollide: Equivariant and Collision-Aware Deformable Objects Neural Simulator
Jun 06, 2025Simulating collisions of deformable objects is a fundamental yet challenging task due to the complexity of modeling solid mechanics and multi-body interactions. Existing data-driven methods often suffer from lack of equivariance to physical symmetries, inadequate handling of collisions, and limited scalability. Here we introduce EqCollide, the first end-to-end equivariant neural fields simulator for deformable objects and their collisions. We propose an equivariant encoder to map object geometry and velocity into latent control points. A subsequent equivariant Graph Neural Network-based Neural Ordinary Differential Equation models the interactions among control points via collision-aware message passing. To reconstruct velocity fields, we query a neural field conditioned on control point features, enabling continuous and resolution-independent motion predictions. Experimental results show that EqCollide achieves accurate, stable, and scalable simulations across diverse object configurations, and our model achieves 24.34% to 35.82% lower rollout MSE even compared with the best-performing baseline model. Furthermore, our model could generalize to more colliding objects and extended temporal horizons, and stay robust to input transformed with group action.
When Sparsity Meets Dynamic Convolution
Apr 05, 2022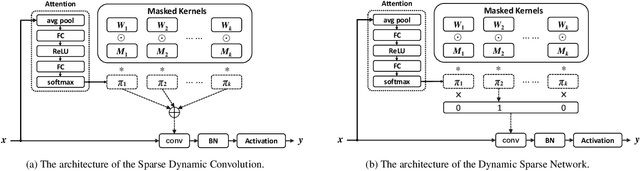
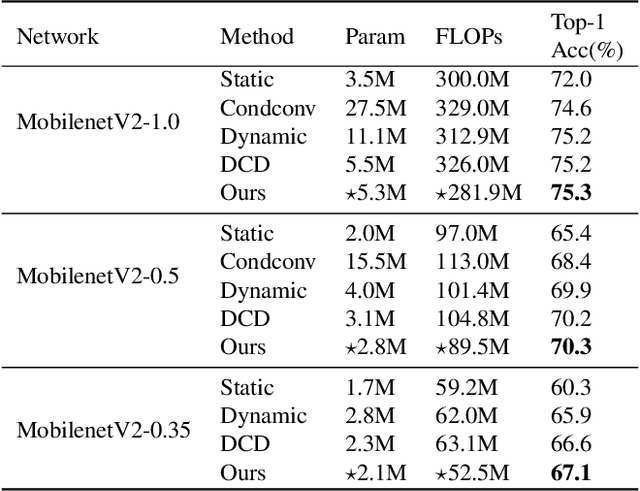
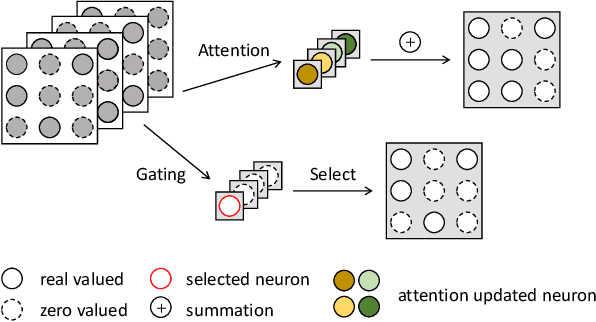

Dynamic convolution achieves a substantial performance boost for efficient CNNs at a cost of increased convolutional weights. Contrastively, mask-based unstructured pruning obtains a lightweight network by removing redundancy in the heavy network at risk of performance drop. In this paper, we propose a new framework to coherently integrate these two paths so that they can complement each other compensate for the disadvantages. We first design a binary mask derived from a learnable threshold to prune static kernels, significantly reducing the parameters and computational cost but achieving higher performance in Imagenet-1K(0.6\% increase in top-1 accuracy with 0.67G fewer FLOPs). Based on this learnable mask, we further propose a novel dynamic sparse network incorporating the dynamic routine mechanism, which exerts much higher accuracy than baselines ($2.63\%$ increase in top-1 accuracy for MobileNetV1 with $90\%$ sparsity). As a result, our method demonstrates a more efficient dynamic convolution with sparsity.