 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed Machine Learning of Parameterized Fundamental Diagrams
Aug 01, 2022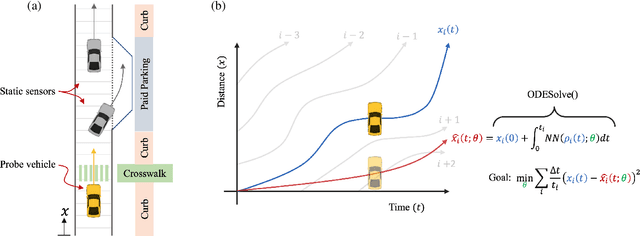
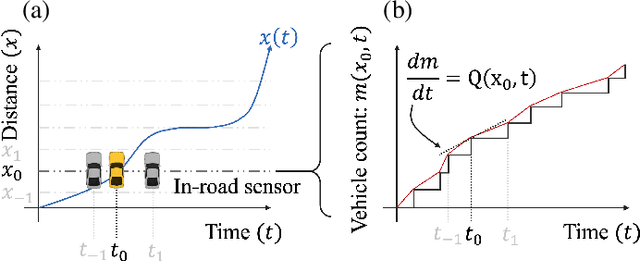
Fundamental diagrams describe the relationship between speed, flow, and density for some roadway (or set of roadway) configuration(s). These diagrams typically do not reflect, however, information on how speed-flow relationships change as a function of exogenous variables such as curb configuration, weather or other exogenous, contextual information. In this paper we present a machine learning methodology that respects known engineering constraints and physical laws of roadway flux - those that are captured in fundamental diagrams - and show how this can be used to introduce contextual information into the generation of these diagrams. The modeling task is formulated as a probe vehicle trajectory reconstruction problem with Neural Ordinary Differential Equations (Neural ODEs). With the presented methodology, we extend the fundamental diagram to non-idealized roadway segments with potentially obstructed traffic data. For simulated data, we generalize this relationship by introducing contextual information at the learning stage, i.e. vehicle composition, driver behavior, curb zoning configuration, etc, and show how the speed-flow relationship changes as a function of these exogenous factors independent of roadway design.
Benchmarking Named Entity Disambiguation approaches for Streaming Graphs
Jul 14, 2014
Named Entity Disambiaguation (NED) is a central task for applications dealing with natural language text. Assume that we have a graph based knowledge base (subsequently referred as Knowledge Graph) where nodes represent various real world entities such as people, location, organization and concepts. Given data sources such as social media streams and web pages Entity Linking is the task of mapping named entities that are extracted from the data to those present in the Knowledge Graph. This is an inherently difficult task due to several reasons. Almost all these data sources are generated without any formal ontology; the unstructured nature of the input, limited context and the ambiguity involved when multiple entities are mapped to the same name make this a hard task. This report looks at two state of the art systems employing two distinctive approaches: graph based Accurate Online Disambiguation of Entities (AIDA) and Mined Evidence Named Entity Disambiguation (MENED), which employs a statistical inference approach. We compare both approaches using the data set and queries provided by the Knowledge Base Population (KBP) track at 2011 NIST Text Analytics Conference (TAC). This report begins with an overview of the respective approaches, followed by detailed description of the experimental setup. It concludes with our findings from the benchmarking exercise.