 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinically Labeled Contrastive Learning for OCT Biomarker Classification
May 24, 2023



This paper presents a novel positive and negative set selection strategy for contrastive learning of medical images based on labels that can be extracted from clinical data. In the medical field, there exists a variety of labels for data that serve different purposes at different stages of a diagnostic and treatment process. Clinical labels and biomarker labels are two examples. In general, clinical labels are easier to obtain in larger quantities because they are regularly collected during routine clinical care, while biomarker labels require expert analysis and interpretation to obtain. Within the field of ophthalmology, previous work has shown that clinical values exhibit correlations with biomarker structures that manifest within optical coherence tomography (OCT) scans. We exploit this relationship by using the clinical data as pseudo-labels for our data without biomarker labels in order to choose positive and negative instances for training a backbone network with a supervised contrastive loss. In this way, a backbone network learns a representation space that aligns with the clinical data distribution available. Afterwards, we fine-tune the network trained in this manner with the smaller amount of biomarker labeled data with a cross-entropy loss in order to classify these key indicators of disease directly from OCT scans. We also expand on this concept by proposing a method that uses a linear combination of clinical contrastive losses. We benchmark our methods against state of the art self-supervised methods in a novel setting with biomarkers of varying granularity. We show performance improvements by as much as 5\% in total biomarker detection AUROC.
OLIVES Dataset: Ophthalmic Labels for Investigating Visual Eye Semantics
Sep 22, 2022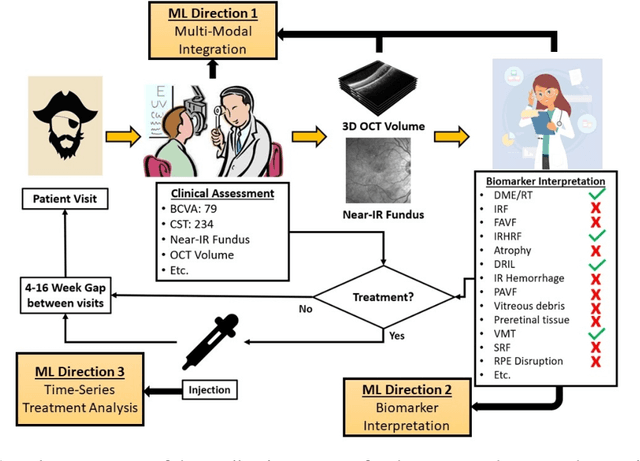
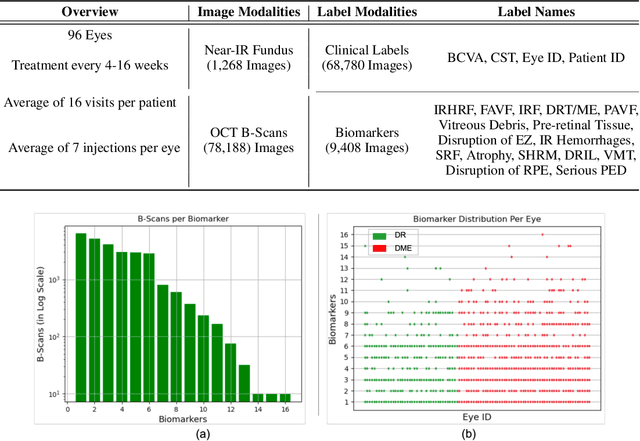
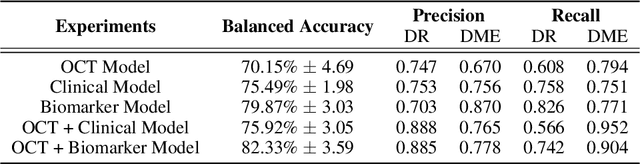
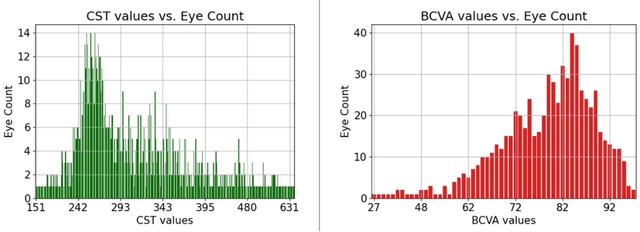
Clinical diagnosis of the eye is performed over multifarious data modalities including scalar clinical labels, vectorized biomarkers, two-dimensional fundus images, and three-dimensional Optical Coherence Tomography (OCT) scans. Clinical practitioners use all available data modalities for diagnosing and treating eye diseases like Diabetic Retinopathy (DR) or Diabetic Macular Edema (DME). Enabling usage of machine learning algorithms within the ophthalmic medical domain requires research into the relationships and interactions between all relevant data over a treatment period. Existing datasets are limited in that they neither provide data nor consider the explicit relationship modeling between the data modalities. In this paper, we introduce the Ophthalmic Labels for Investigating Visual Eye Semantics (OLIVES) dataset that addresses the above limitation. This is the first OCT and near-IR fundus dataset that includes clinical labels, biomarker labels, disease labels, and time-series patient treatment information from associated clinical trials. The dataset consists of 1268 near-IR fundus images each with at least 49 OCT scans, and 16 biomarkers, along with 4 clinical labels and a disease diagnosis of DR or DME. In total, there are 96 eyes' data averaged over a period of at least two years with each eye treated for an average of 66 weeks and 7 injections. We benchmark the utility of OLIVES dataset for ophthalmic data as well as provide benchmarks and concrete research directions for core and emerging machine learning paradigms within medical image analysis.