 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical Point-Finding Methods Reveal Gradient-Flat Regions of Deep Network Losses
Mar 23, 2020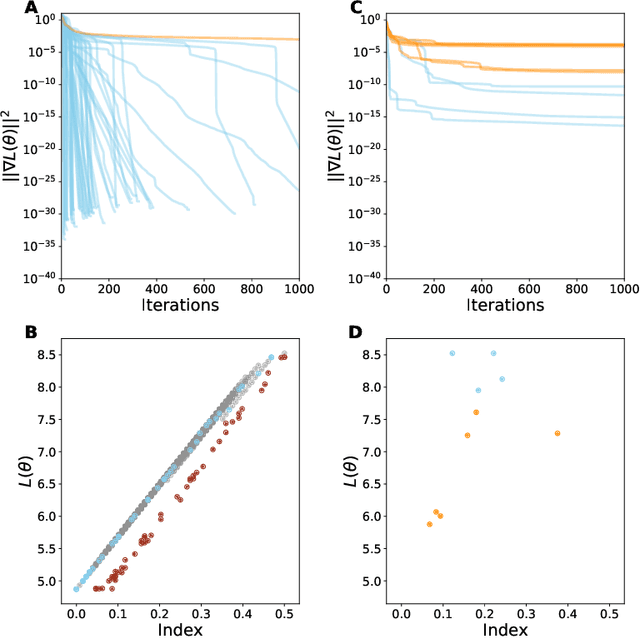
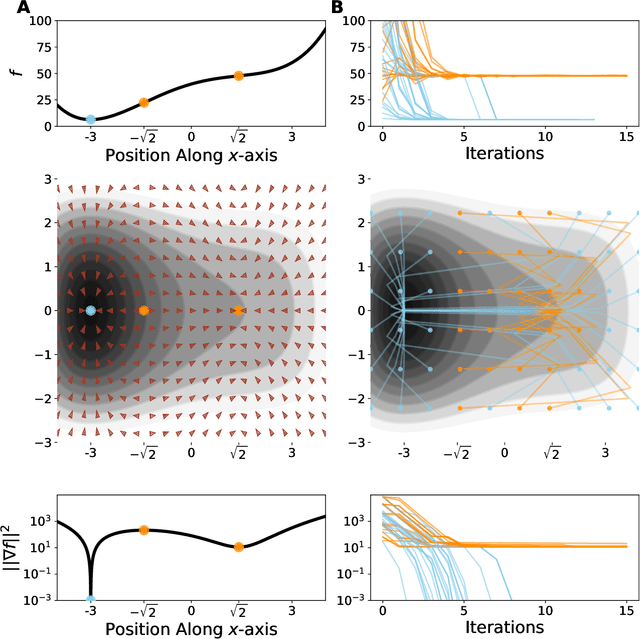
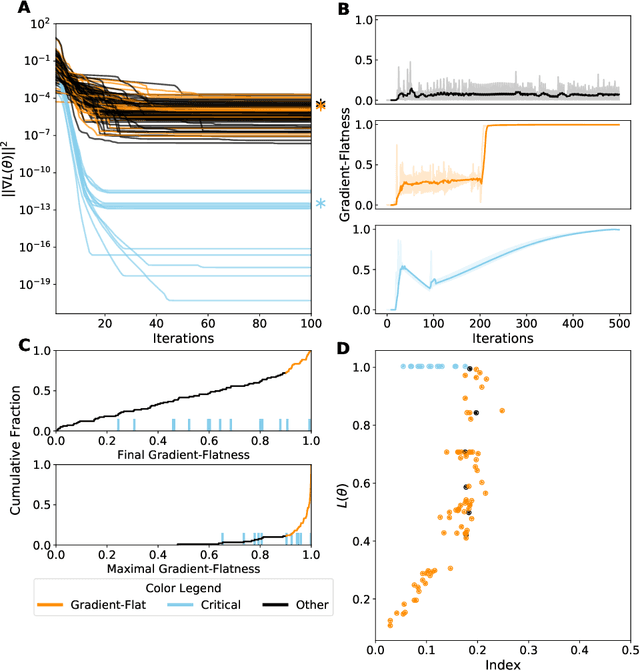
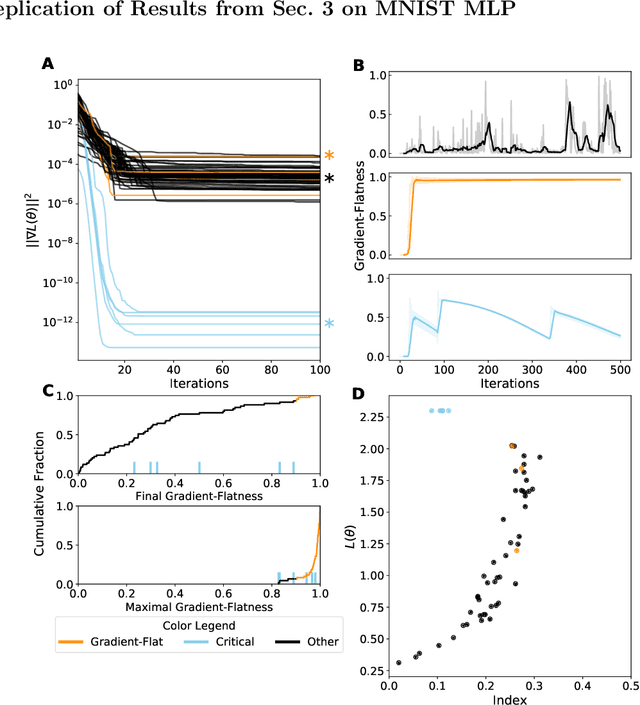
Despite the fact that the loss functions of deep neural networks are highly non-convex, gradient-based optimization algorithms converge to approximately the same performance from many random initial points. One thread of work has focused on explaining this phenomenon by characterizing the local curvature near critical points of the loss function, where the gradients are near zero, and demonstrating that neural network losses enjoy a no-bad-local-minima property and an abundance of saddle points. We report here that the methods used to find these putative critical points suffer from a bad local minima problem of their own: they often converge to or pass through regions where the gradient norm has a stationary point. We call these gradient-flat regions, since they arise when the gradient is approximately in the kernel of the Hessian, such that the loss is locally approximately linear, or flat, in the direction of the gradient. We describe how the presence of these regions necessitates care in both interpreting past results that claimed to find critical points of neural network losses and in designing second-order methods for optimizing neural networks.
Numerically Recovering the Critical Points of a Deep Linear Autoencoder
Jan 29, 2019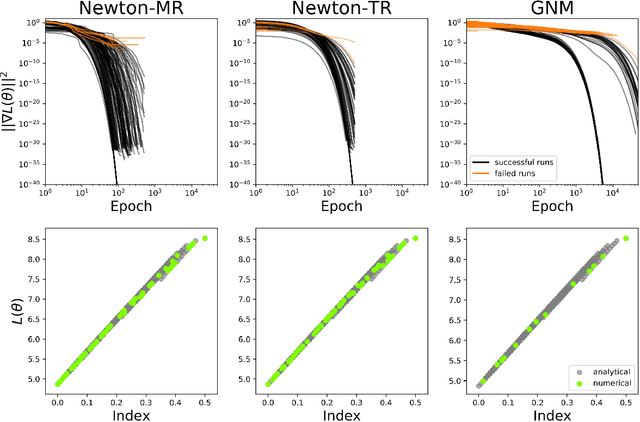
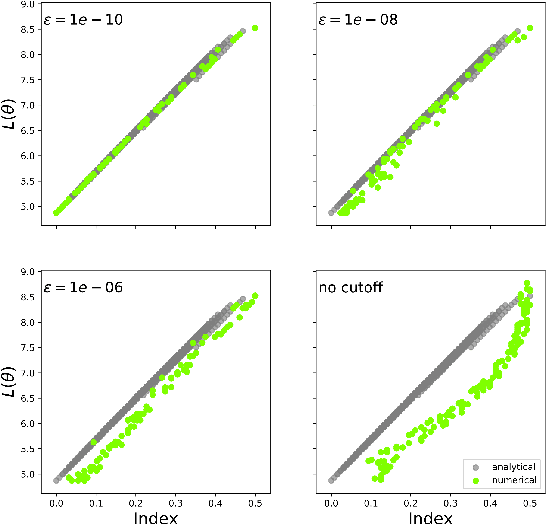
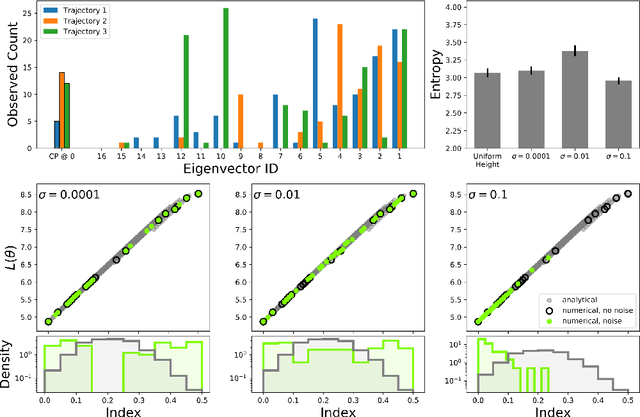
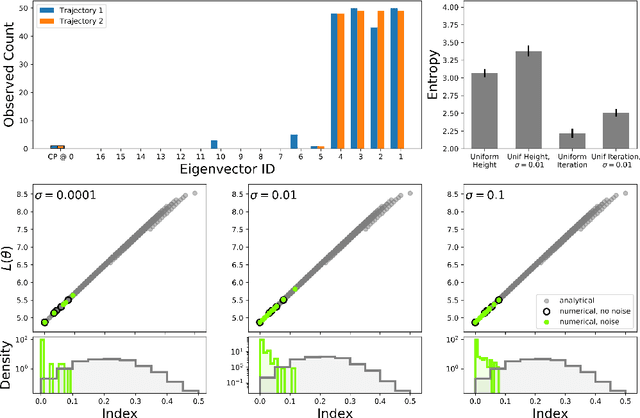
Numerically locating the critical points of non-convex surfaces is a long-standing problem central to many fields. Recently, the loss surfaces of deep neural networks have been explored to gain insight into outstanding questions in optimization, generalization, and network architecture design. However, the degree to which recently-proposed methods for numerically recovering critical points actually do so has not been thoroughly evaluated. In this paper, we examine this issue in a case for which the ground truth is known: the deep linear autoencoder. We investigate two sub-problems associated with numerical critical point identification: first, because of large parameter counts, it is infeasible to find all of the critical points for contemporary neural networks, necessitating sampling approaches whose characteristics are poorly understood; second, the numerical tolerance for accurately identifying a critical point is unknown, and conservative tolerances are difficult to satisfy. We first identify connections between recently-proposed methods and well-understood methods in other fields, including chemical physics, economics, and algebraic geometry. We find that several methods work well at recovering certain information about loss surfaces, but fail to take an unbiased sample of critical points. Furthermore, numerical tolerance must be very strict to ensure that numerically-identified critical points have similar properties to true analytical critical points. We also identify a recently-published Newton method for optimization that outperforms previous methods as a critical point-finding algorithm. We expect our results will guide future attempts to numerically study critical points in large nonlinear neural networks.