 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling the Dynamics of Online Learning Activity
Oct 18, 2016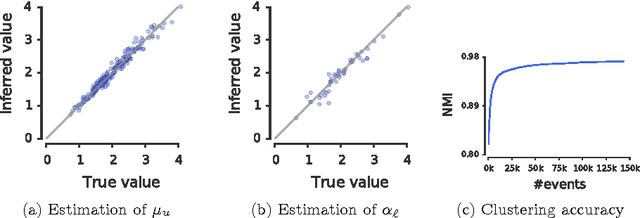

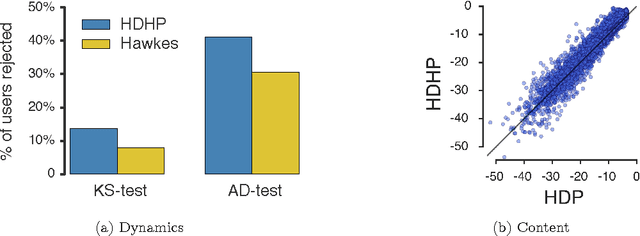
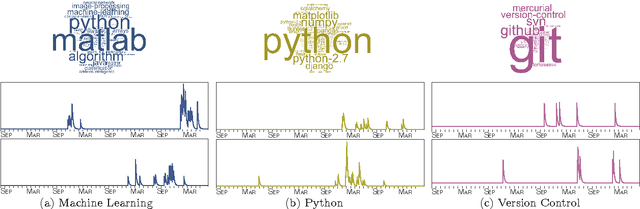
People are increasingly relying on the Web and social media to find solutions to their problems in a wide range of domains. In this online setting, closely related problems often lead to the same characteristic learning pattern, in which people sharing these problems visit related pieces of information, perform almost identical queries or, more generally, take a series of similar actions. In this paper, we introduce a novel modeling framework for clustering continuous-time grouped streaming data, the hierarchical Dirichlet Hawkes process (HDHP), which allows us to automatically uncover a wide variety of learning patterns from detailed traces of learning activity. Our model allows for efficient inference, scaling to millions of actions taken by thousands of users. Experiments on real data gathered from Stack Overflow reveal that our framework can recover meaningful learning patterns in terms of both content and temporal dynamics, as well as accurately track users' interests and goals over time.
Complex Support Vector Machines for Regression and Quaternary Classification
Jul 15, 2014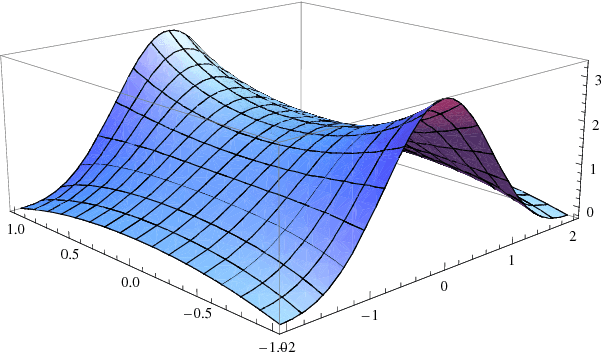
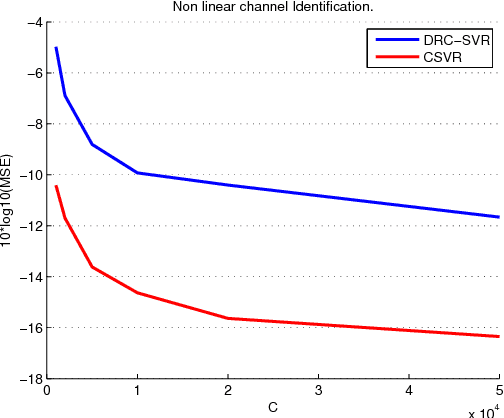
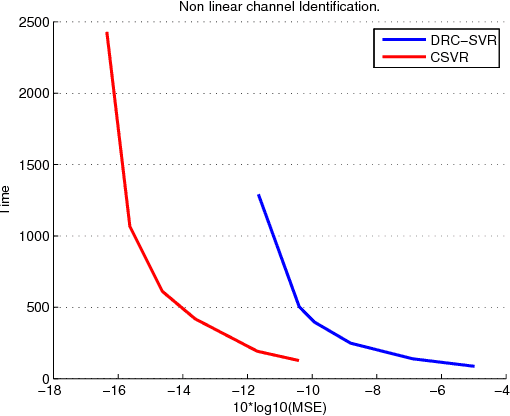
The paper presents a new framework for complex Support Vector Regression as well as Support Vector Machines for quaternary classification. The method exploits the notion of widely linear estimation to model the input-out relation for complex-valued data and considers two cases: a) the complex data are split into their real and imaginary parts and a typical real kernel is employed to map the complex data to a complexified feature space and b) a pure complex kernel is used to directly map the data to the induced complex feature space. The recently developed Wirtinger's calculus on complex reproducing kernel Hilbert spaces (RKHS) is employed in order to compute the Lagrangian and derive the dual optimization problem. As one of our major results, we prove that any complex SVM/SVR task is equivalent with solving two real SVM/SVR tasks exploiting a specific real kernel which is generated by the chosen complex kernel. In particular, the case of pure complex kernels leads to the generation of new kernels, which have not been considered before. In the classification case, the proposed framework inherently splits the complex space into four parts. This leads naturally in solving the four class-task (quaternary classification), instead of the typical two classes of the real SVM. In turn, this rationale can be used in a multiclass problem as a split-class scenario based on four classes, as opposed to the one-versus-all method; this can lead to significant computational savings. Experiments demonstrate the effectiveness of the proposed framework for regression and classification tasks that involve complex data.