 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVESR-Net: The Winning Solution to Youku Video Enhancement and Super-Resolution Challenge
Mar 04, 2020



This paper introduces VESR-Net, a method for video enhancement and super-resolution (VESR). We design a separate non-local module to explore the relations among video frames and fuse video frames efficiently, and a channel attention residual block to capture the relations among feature maps for video frame reconstruction in VESR-Net. We conduct experiments to analyze the effectiveness of these designs in VESR-Net, which demonstrates the advantages of VESR-Net over previous state-of-the-art VESR methods. It is worth to mention that among more than thousands of participants for Youku video enhancement and super-resolution (Youku-VESR) challenge, our proposed VESR-Net beat other competitive methods and ranked the first place.
A Coarse-to-Fine Framework for Learned Color Enhancement with Non-Local Attention
Jul 20, 2019
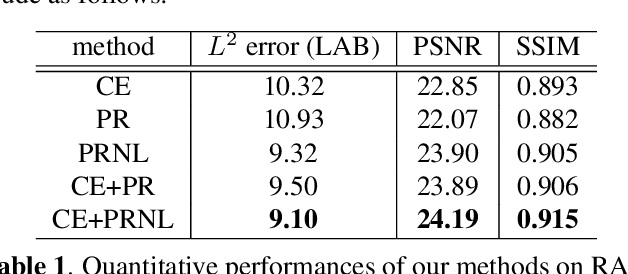
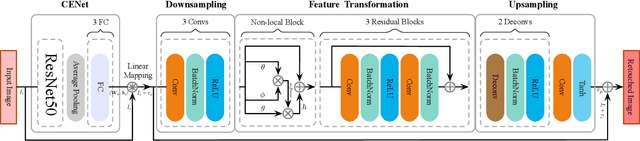

Automatic color enhancement is aimed to adaptively adjust photos to expected styles and tones. For current learned methods in this field, global harmonious perception and local details are hard to be well-considered in a single model simultaneously. To address this problem, we propose a coarse-to-fine framework with non-local attention for color enhancement in this paper. Within our framework, we propose to divide enhancement process into channel-wise enhancement and pixel-wise refinement performed by two cascaded Convolutional Neural Networks (CNNs). In channel-wise enhancement, our model predicts a global linear mapping for RGB channels of input images to perform global style adjustment. In pixel-wise refinement, we learn a refining mapping using residual learning for local adjustment. Further, we adopt a non-local attention block to capture the long-range dependencies from global information for subsequent fine-grained local refinement. We evaluate our proposed framework on the commonly using benchmark and conduct sufficient experiments to demonstrate each technical component within it.