 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Distillation: Channel-Wise Attention for Knowledge Distillation
Jun 02, 2020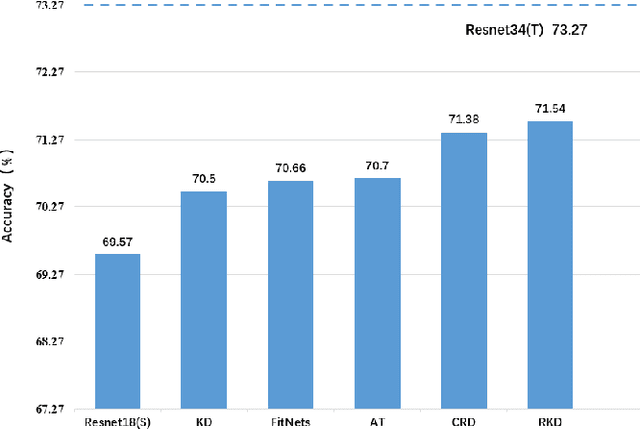
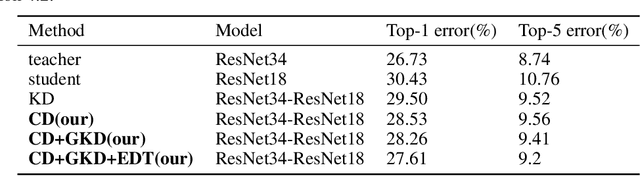
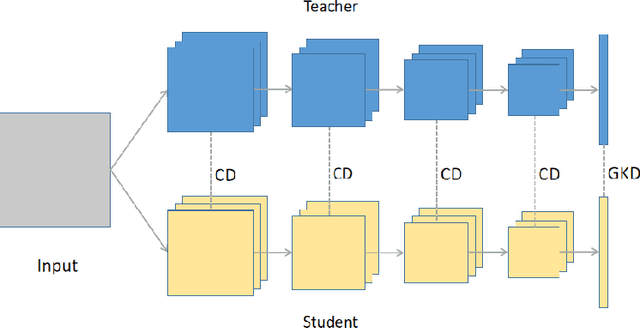
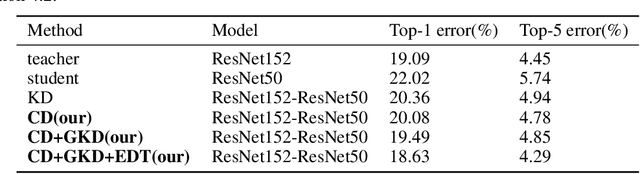
Knowledge distillation is to transfer the knowledge from the data learned by the teacher network to the student network, so that the student has the advantage of less parameters and less calculations, and the accuracy is close to the teacher. In this paper, we propose a new distillation method, which contains two transfer distillation strategies and a loss decay strategy. The first transfer strategy is based on channel-wise attention, called Channel Distillation (CD). CD transfers the channel information from the teacher to the student. The second is Guided Knowledge Distillation (GKD). Unlike Knowledge Distillation (KD), which allows the student to mimic each sample's prediction distribution of the teacher, GKD only enables the student to mimic the correct output of the teacher. The last part is Early Decay Teacher (EDT). During the training process, we gradually decay the weight of the distillation loss. The purpose is to enable the student to gradually control the optimization rather than the teacher. Our proposed method is evaluated on ImageNet and CIFAR100. On ImageNet, we achieve 27.68% of top-1 error with ResNet18, which outperforms state-of-the-art methods. On CIFAR100, we achieve surprising result that the student outperforms the teacher. Code is available at https://github.com/zhouzaida/channel-distillation.
Attribute-guided Feature Extraction and Augmentation Robust Learning for Vehicle Re-identification
May 13, 2020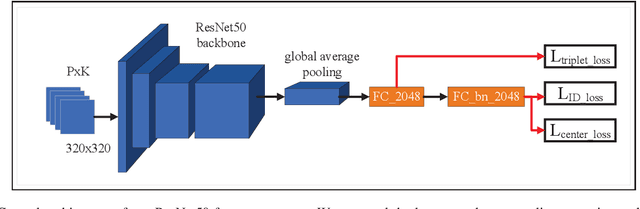
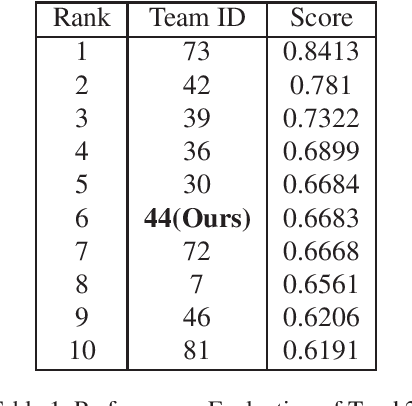
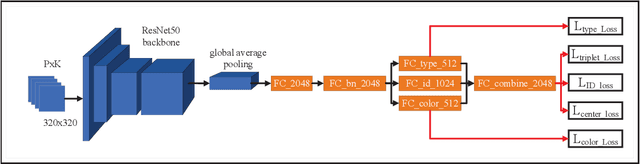

Vehicle re-identification is one of the core technologies of intelligent transportation systems and smart cities, but large intra-class diversity and inter-class similarity poses great challenges for existing method. In this paper, we propose a multi-guided learning approach which utilizing the information of attributes and meanwhile introducing two novel random augments to improve the robustness during training. What's more, we propose an attribute constraint method and group re-ranking strategy to refine matching results. Our method achieves mAP of 66.83% and rank-1 accuracy 76.05% in the CVPR 2020 AI City Challenge.