 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Matrix Theory for Stochastic Gradient Descent
Dec 29, 2024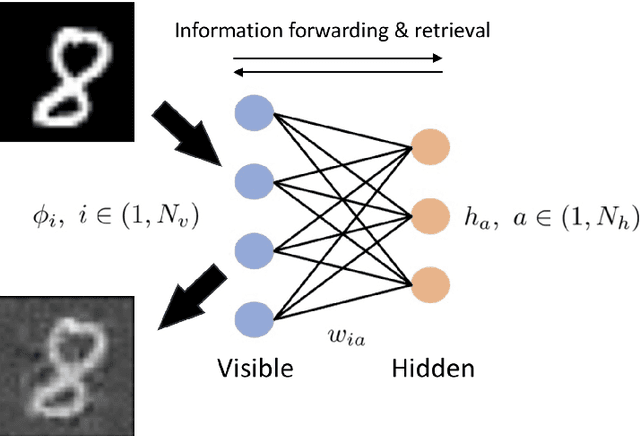
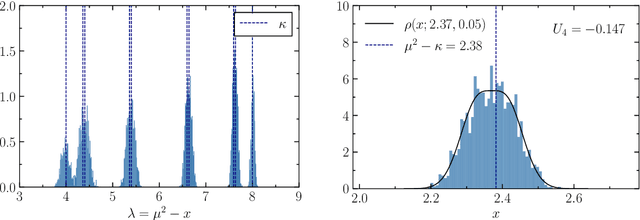


Investigating the dynamics of learning in machine learning algorithms is of paramount importance for understanding how and why an approach may be successful. The tools of physics and statistics provide a robust setting for such investigations. Here we apply concepts from random matrix theory to describe stochastic weight matrix dynamics, using the framework of Dyson Brownian motion. We derive the linear scaling rule between the learning rate (step size) and the batch size, and identify universal and non-universal aspects of weight matrix dynamics. We test our findings in the (near-)solvable case of the Gaussian Restricted Boltzmann Machine and in a linear one-hidden-layer neural network.
Dyson Brownian motion and random matrix dynamics of weight matrices during learning
Nov 20, 2024



During training, weight matrices in machine learning architectures are updated using stochastic gradient descent or variations thereof. In this contribution we employ concepts of random matrix theory to analyse the resulting stochastic matrix dynamics. We first demonstrate that the dynamics can generically be described using Dyson Brownian motion, leading to e.g. eigenvalue repulsion. The level of stochasticity is shown to depend on the ratio of the learning rate and the mini-batch size, explaining the empirically observed linear scaling rule. We verify this linear scaling in the restricted Boltzmann machine. Subsequently we study weight matrix dynamics in transformers (a nano-GPT), following the evolution from a Marchenko-Pastur distribution for eigenvalues at initialisation to a combination with additional structure at the end of learning.
Stochastic weight matrix dynamics during learning and Dyson Brownian motion
Jul 23, 2024



We demonstrate that the update of weight matrices in learning algorithms can be described in the framework of Dyson Brownian motion, thereby inheriting many features of random matrix theory. We relate the level of stochasticity to the ratio of the learning rate and the mini-batch size, providing more robust evidence to a previously conjectured scaling relationship. We discuss universal and non-universal features in the resulting Coulomb gas distribution and identify the Wigner surmise and Wigner semicircle explicitly in a teacher-student model and in the (near-)solvable case of the Gaussian restricted Boltzmann machine.