 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogistic-beta processes for modeling dependent random probabilities with beta marginals
Feb 10, 2024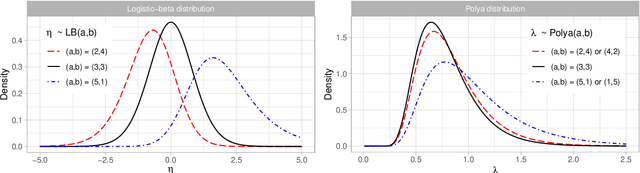
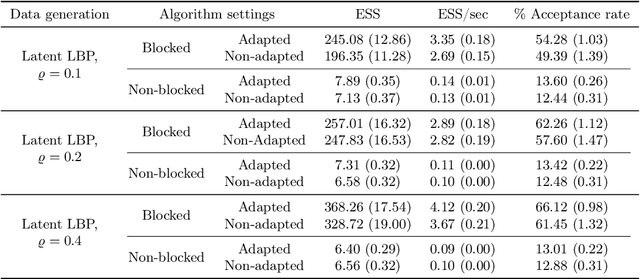
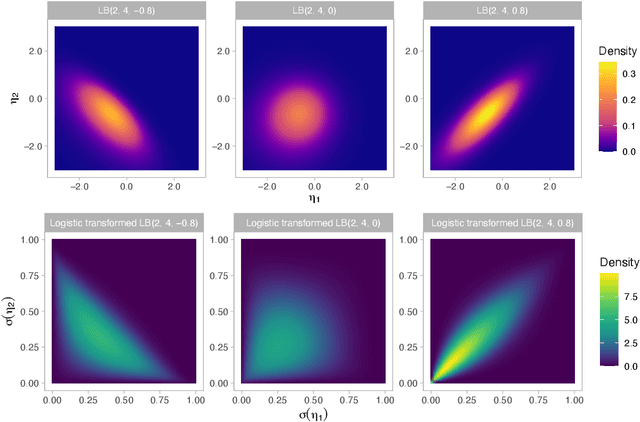
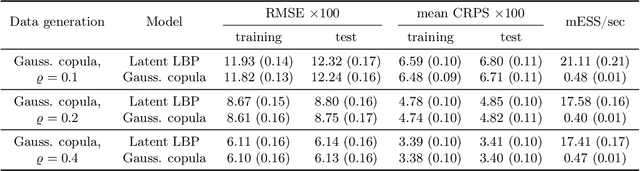
The beta distribution serves as a canonical tool for modeling probabilities and is extensively used in statistics and machine learning, especially in the field of Bayesian nonparametrics. Despite its widespread use, there is limited work on flexible and computationally convenient stochastic process extensions for modeling dependent random probabilities. We propose a novel stochastic process called the logistic-beta process, whose logistic transformation yields a stochastic process with common beta marginals. Similar to the Gaussian process, the logistic-beta process can model dependence on both discrete and continuous domains, such as space or time, and has a highly flexible dependence structure through correlation kernels. Moreover, its normal variance-mean mixture representation leads to highly effective posterior inference algorithms. The flexibility and computational benefits of logistic-beta processes are demonstrated through nonparametric binary regression simulation studies. Furthermore, we apply the logistic-beta process in modeling dependent Dirichlet processes, and illustrate its application and benefits through Bayesian density regression problems in a toxicology study.
Why the Rich Get Richer? On the Balancedness of Random Partition Models
Jan 30, 2022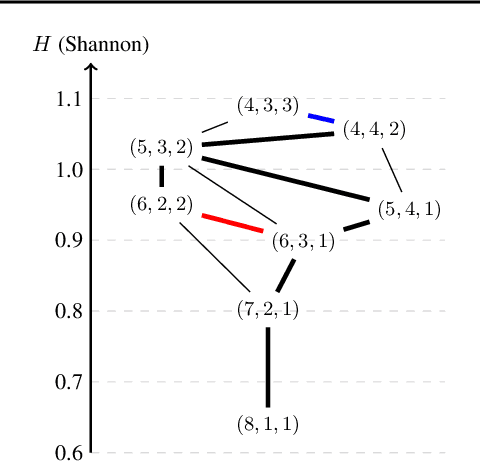

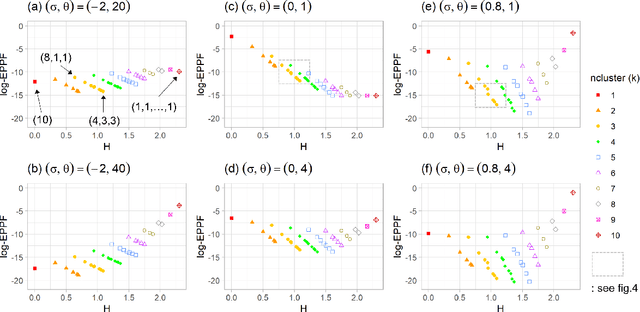

Random partition models are widely used in Bayesian methods for various clustering tasks, such as mixture models, topic models, and community detection problems. While the number of clusters induced by random partition models has been studied extensively, another important model property regarding the balancedness of cluster sizes has been largely neglected. We formulate a framework to define and theoretically study the balancedness of exchangeable random partition models, by analyzing how a model assigns probabilities to partitions with different levels of balancedness. We demonstrate that the "rich-get-richer" characteristic of many existing popular random partition models is an inevitable consequence of two common assumptions: product-form exchangeability and projectivity. We propose a principled way to compare the balancedness of random partition models, which gives a better understanding of what model works better and what doesn't for different applications. We also introduce the "rich-get-poorer" random partition models and illustrate their application to entity resolution tasks.
T-LoHo: A Bayesian Regularization Model for Structured Sparsity and Smoothness on Graphs
Jul 06, 2021
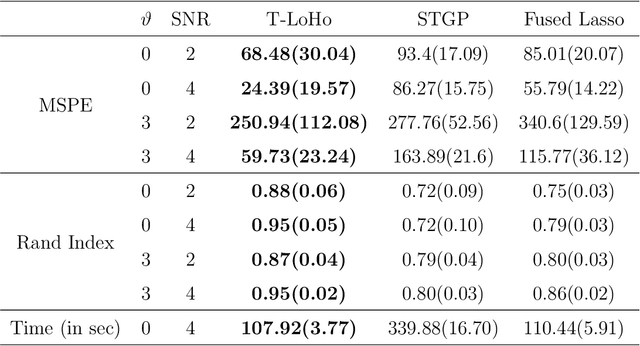

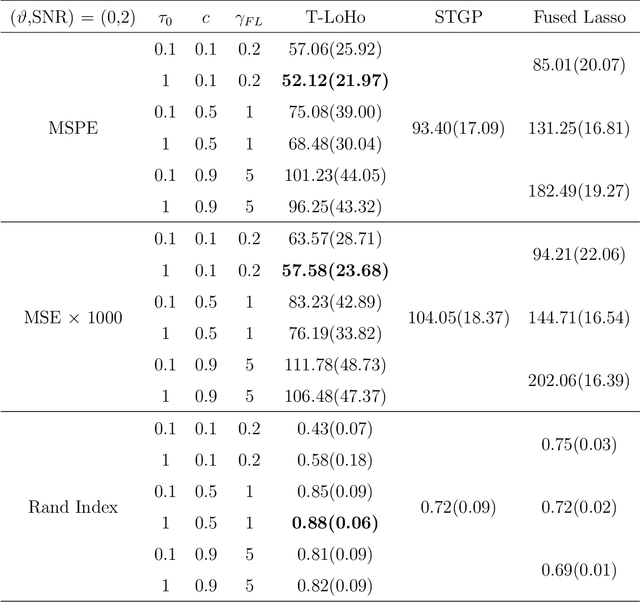
Many modern complex data can be represented as a graph. In models dealing with graph-structured data, multivariate parameters are not just sparse but have structured sparsity and smoothness in the sense that both zero and non-zero parameters tend to cluster together. We propose a new prior for high dimensional parameters with graphical relations, referred to as a Tree-based Low-rank Horseshoe(T-LoHo) model, that generalizes the popular univariate Bayesian horseshoe shrinkage prior to the multivariate setting to detect structured sparsity and smoothness simultaneously. The prior can be embedded in many hierarchical high dimensional models. To illustrate its utility, we apply it to regularize a Bayesian high-dimensional regression problem where the regression coefficients are linked on a graph. The resulting clusters have flexible shapes and satisfy the cluster contiguity constraint with respect to the graph. We design an efficient Markov chain Monte Carlo algorithm that delivers full Bayesian inference with uncertainty measures for model parameters including the number of clusters. We offer theoretical investigations of the clustering effects and posterior concentration results. Finally, we illustrate the performance of the model with simulation studies and real data applications such as anomaly detection in road networks. The results indicate substantial improvements over other competing methods such as sparse fused lasso.