 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved YOLOv3 Object Classification in Intelligent Transportation System
Apr 08, 2020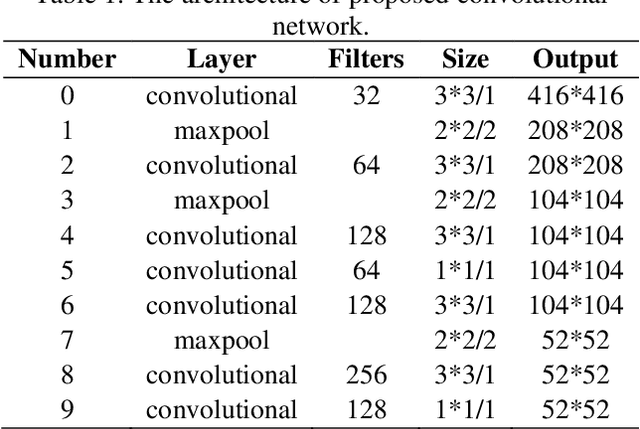

The technology of vehicle and driver detection in Intelligent Transportation System(ITS) is a hot topic in recent years. In particular, the driver detection is still a challenging problem which is conductive to supervising traffic order and maintaining public safety. In this paper, an algorithm based on YOLOv3 is proposed to realize the detection and classification of vehicles, drivers, and people on the highway, so as to achieve the purpose of distinguishing driver and passenger and form a one-to-one correspondence between vehicles and drivers. The proposed model and contrast experiment are conducted on our self-build traffic driver's face database. The effectiveness of our proposed algorithm is validated by extensive experiments and verified under various complex highway conditions. Compared with other advanced vehicle and driver detection technologies, the model has a good performance and is robust to road blocking, different attitudes, and extreme lighting.
Adaptive Multiscale Illumination-Invariant Feature Representation for Undersampled Face Recognition
Apr 07, 2020

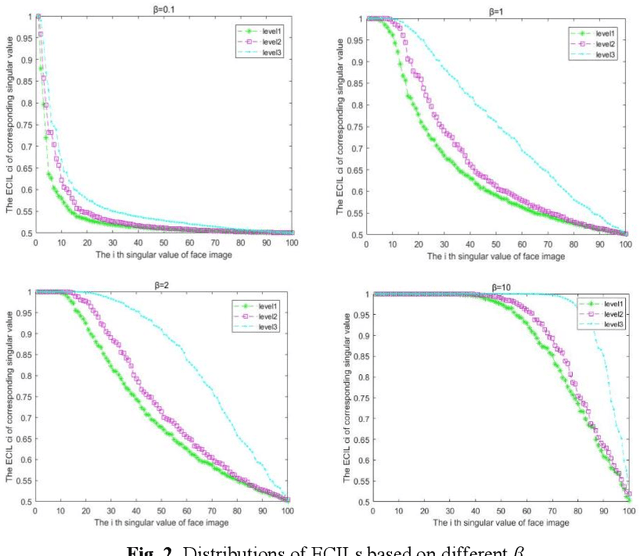
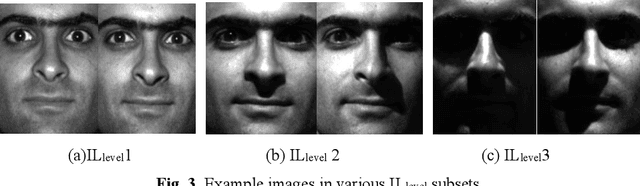
This paper presents an novel illumination-invariant feature representation approach used to eliminate the varying illumination affection in undersampled face recognition. Firstly, a new illumination level classification technique based on Singular Value Decomposition (SVD) is proposed to judge the illumination level of input image. Secondly, we construct the logarithm edgemaps feature (LEF) based on lambertian model and local near neighbor feature of the face image, applying to local region within multiple scales. Then, the illumination level is referenced to construct the high performance LEF as well realize adaptive fusion for multiple scales LEFs for the face image, performing JLEF-feature. In addition, the constrain operation is used to remove the useless high-frequency interference, disentangling useful facial feature edges and constructing AJLEF-face. Finally, the effects of the our methods and other state-of-the-art algorithms including deep learning methods are tested on Extended Yale B, CMU PIE, AR as well as our Self-build Driver database (SDB). The experimental results demonstrate that the JLEF-feature and AJLEF-face outperform other related approaches for undersampled face recognition under varying illumination.
Deep Attentive Generative Adversarial Network for Photo-Realistic Image De-Quantization
Apr 07, 2020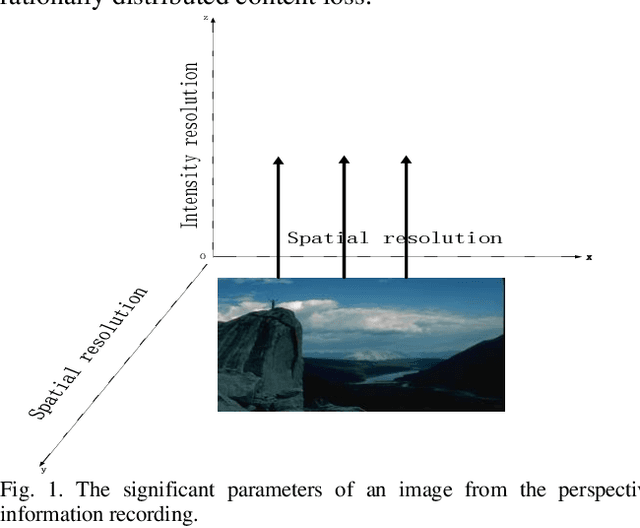
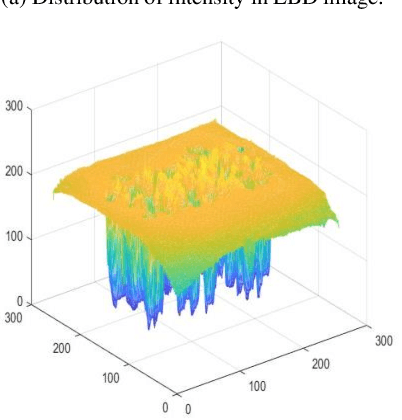
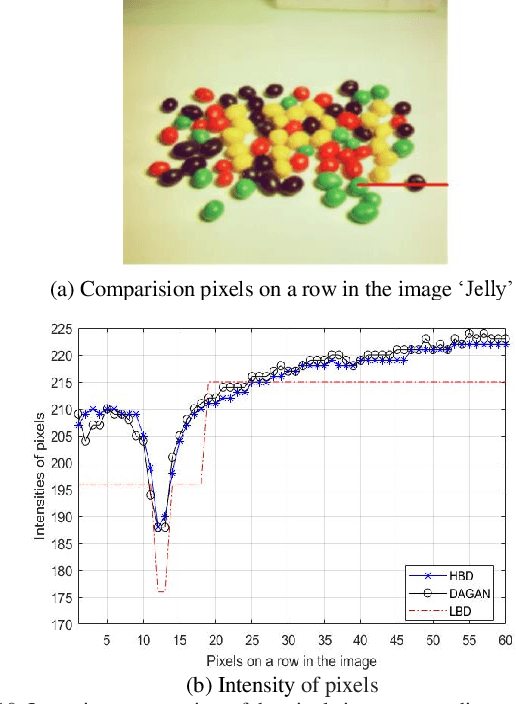
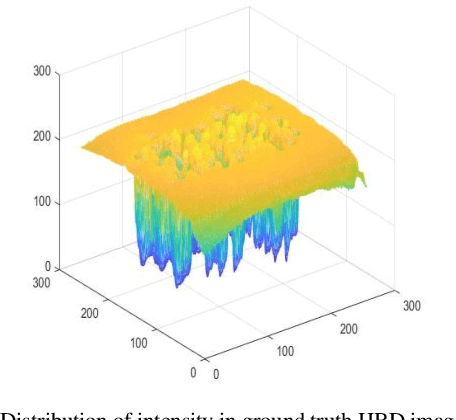
Most of current display devices are with eight or higher bit-depth. However, the quality of most multimedia tools cannot achieve this bit-depth standard for the generating images. De-quantization can improve the visual quality of low bit-depth image to display on high bit-depth screen. This paper proposes DAGAN algorithm to perform super-resolution on image intensity resolution, which is orthogonal to the spatial resolution, realizing photo-realistic de-quantization via an end-to-end learning pattern. Until now, this is the first attempt to apply Generative Adversarial Network (GAN) framework for image de-quantization. Specifically, we propose the Dense Residual Self-attention (DenseResAtt) module, which is consisted of dense residual blocks armed with self-attention mechanism, to pay more attention on high-frequency information. Moreover, the series connection of sequential DenseResAtt modules forms deep attentive network with superior discriminative learning ability in image de-quantization, modeling representative feature maps to recover as much useful information as possible. In addition, due to the adversarial learning framework can reliably produce high quality natural images, the specified content loss as well as the adversarial loss are back-propagated to optimize the training of model. Above all, DAGAN is able to generate the photo-realistic high bit-depth image without banding artifacts. Experiment results on several public benchmarks prove that the DAGAN algorithm possesses ability to achieve excellent visual effect and satisfied quantitative performance.
Copy and Paste GAN: Face Hallucination from Shaded Thumbnails
Mar 19, 2020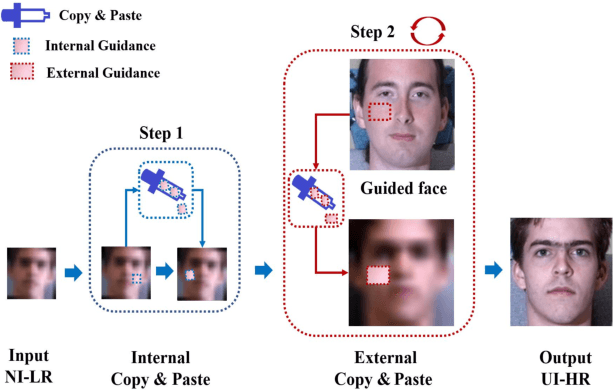
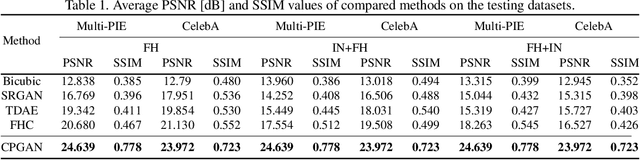

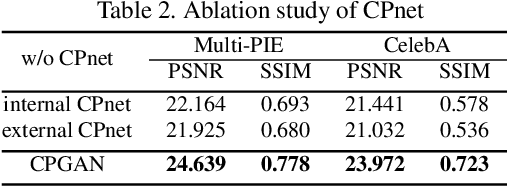
Existing face hallucination methods based on convolutional neural networks (CNN) have achieved impressive performance on low-resolution (LR) faces in a normal illumination condition. However, their performance degrades dramatically when LR faces are captured in low or non-uniform illumination conditions. This paper proposes a Copy and Paste Generative Adversarial Network (CPGAN) to recover authentic high-resolution (HR) face images while compensating for low and non-uniform illumination. To this end, we develop two key components in our CPGAN: internal and external Copy and Paste nets (CPnets). Specifically, our internal CPnet exploits facial information residing in the input image to enhance facial details; while our external CPnet leverages an external HR face for illumination compensation. A new illumination compensation loss is thus developed to capture illumination from the external guided face image effectively. Furthermore, our method offsets illumination and upsamples facial details alternately in a coarse-to-fine fashion, thus alleviating the correspondence ambiguity between LR inputs and external HR inputs. Extensive experiments demonstrate that our method manifests authentic HR face images in a uniform illumination condition and outperforms state-of-the-art methods qualitatively and quantitatively.