 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECOD: Unsupervised Outlier Detection Using Empirical Cumulative Distribution Functions
Jan 02, 2022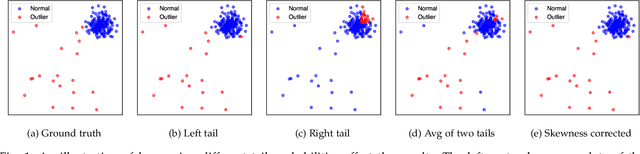
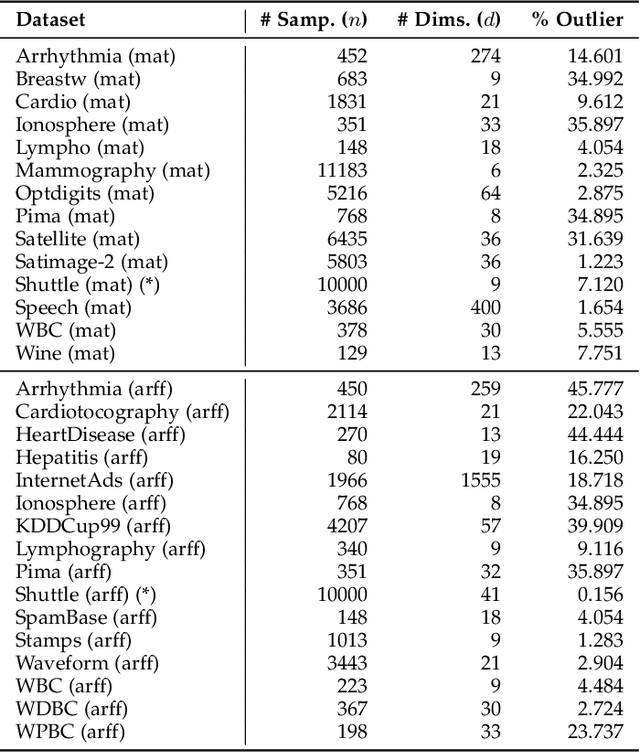
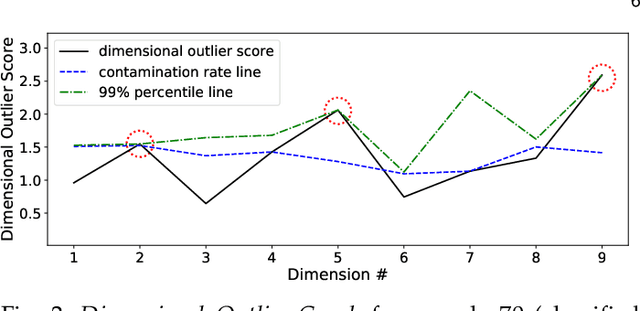
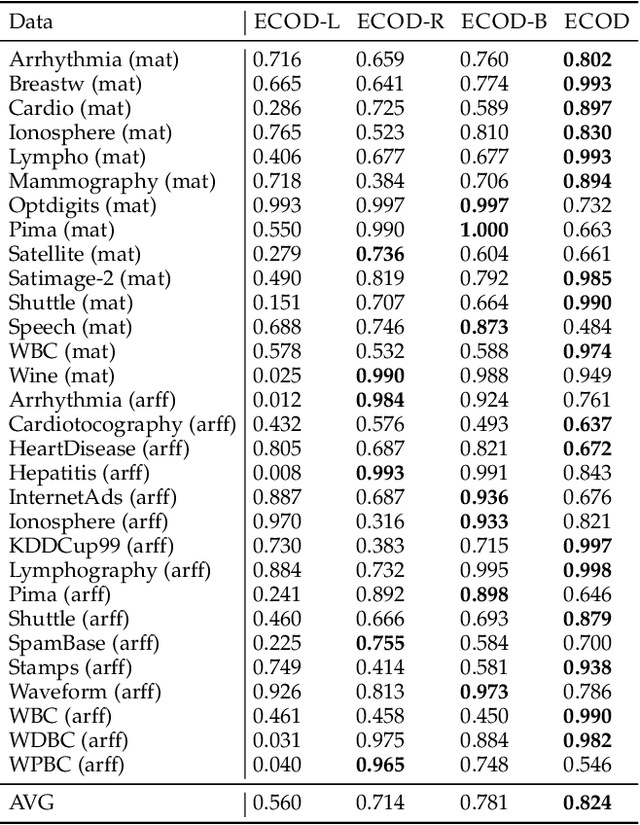
Outlier detection refers to the identification of data points that deviate from a general data distribution. Existing unsupervised approaches often suffer from high computational cost, complex hyperparameter tuning, and limited interpretability, especially when working with large, high-dimensional datasets. To address these issues, we present a simple yet effective algorithm called ECOD (Empirical-Cumulative-distribution-based Outlier Detection), which is inspired by the fact that outliers are often the "rare events" that appear in the tails of a distribution. In a nutshell, ECOD first estimates the underlying distribution of the input data in a nonparametric fashion by computing the empirical cumulative distribution per dimension of the data. ECOD then uses these empirical distributions to estimate tail probabilities per dimension for each data point. Finally, ECOD computes an outlier score of each data point by aggregating estimated tail probabilities across dimensions. Our contributions are as follows: (1) we propose a novel outlier detection method called ECOD, which is both parameter-free and easy to interpret; (2) we perform extensive experiments on 30 benchmark datasets, where we find that ECOD outperforms 11 state-of-the-art baselines in terms of accuracy, efficiency, and scalability; and (3) we release an easy-to-use and scalable (with distributed support) Python implementation for accessibility and reproducibility.
COPOD: Copula-Based Outlier Detection
Sep 20, 2020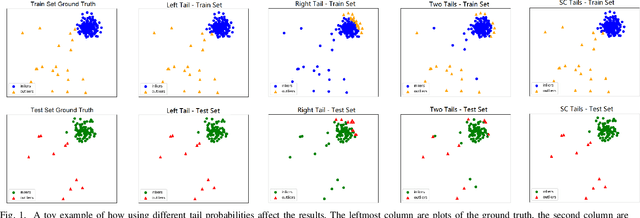
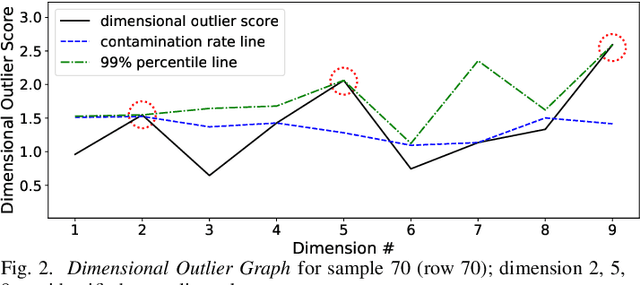
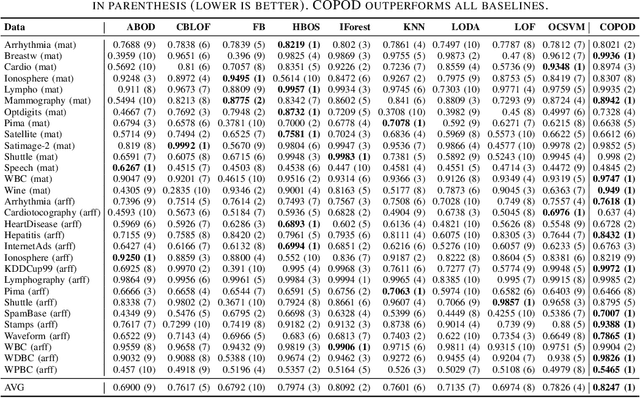
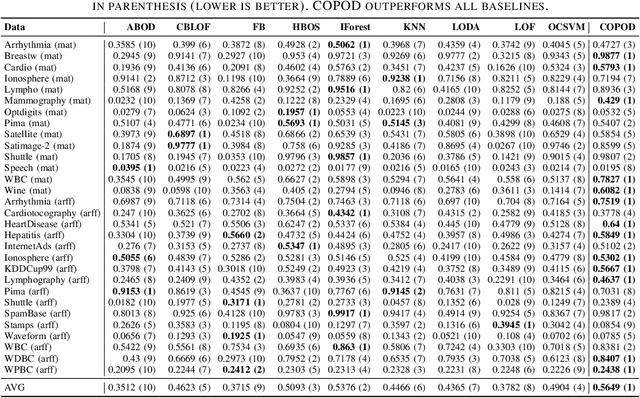
Outlier detection refers to the identification of rare items that are deviant from the general data distribution. Existing approaches suffer from high computational complexity, low predictive capability, and limited interpretability. As a remedy, we present a novel outlier detection algorithm called COPOD, which is inspired by copulas for modeling multivariate data distribution. COPOD first constructs an empirical copula, and then uses it to predict tail probabilities of each given data point to determine its level of "extremeness". Intuitively, we think of this as calculating an anomalous p-value. This makes COPOD both parameter-free, highly interpretable, and computationally efficient. In this work, we make three key contributions, 1) propose a novel, parameter-free outlier detection algorithm with both great performance and interpretability, 2) perform extensive experiments on 30 benchmark datasets to show that COPOD outperforms in most cases and is also one of the fastest algorithms, and 3) release an easy-to-use Python implementation for reproducibility.
Domain-Specific Languages of Mathematics: Presenting Mathematical Analysis Using Functional Programming
Nov 29, 2016We present the approach underlying a course on "Domain-Specific Languages of Mathematics", currently being developed at Chalmers in response to difficulties faced by third-year students in learning and applying classical mathematics (mainly real and complex analysis). The main idea is to encourage the students to approach mathematical domains from a functional programming perspective: to identify the main functions and types involved and, when necessary, to introduce new abstractions; to give calculational proofs; to pay attention to the syntax of the mathematical expressions; and, finally, to organise the resulting functions and types in domain-specific languages.
* In Proceedings TFPIE 2015/6, arXiv:1611.08651