 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain Programming is Immune to Adversarial Attacks: Towards Accurate and Robust Image Classification using Symbolic Learning
Mar 01, 2021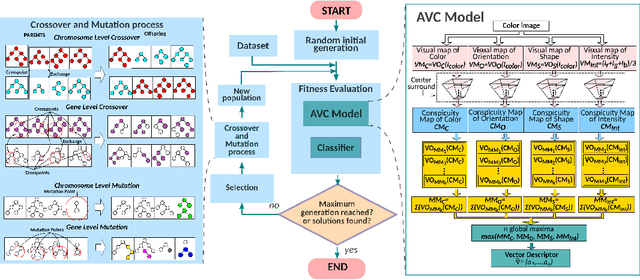



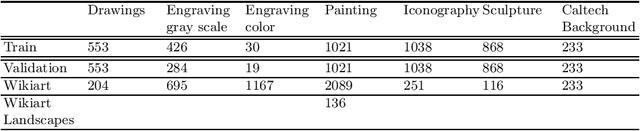
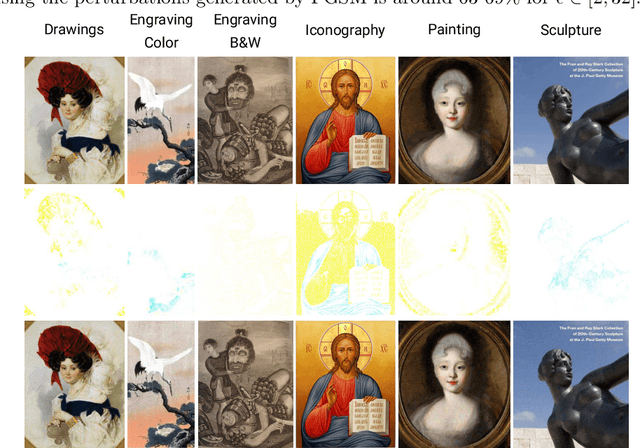
In recent years, the security concerns about the vulnerability of Deep Convolutional Neural Networks (DCNN) to Adversarial Attacks (AA) in the form of small modifications to the input image almost invisible to human vision make their predictions untrustworthy. Therefore, it is necessary to provide robustness to adversarial examples in addition to an accurate score when developing a new classifier. In this work, we perform a comparative study of the effects of AA on the complex problem of art media categorization, which involves a sophisticated analysis of features to classify a fine collection of artworks. We tested a prevailing bag of visual words approach from computer vision, four state-of-the-art DCNN models (AlexNet, VGG, ResNet, ResNet101), and the Brain Programming (BP) algorithm. In this study, we analyze the algorithms' performance using accuracy. Besides, we use the accuracy ratio between adversarial examples and clean images to measure robustness. Moreover, we propose a statistical analysis of each classifier's predictions' confidence to corroborate the results. We confirm that BP predictions' change was below 2\% using adversarial examples computed with the fast gradient sign method. Also, considering the multiple pixel attack, BP obtained four out of seven classes without changes and the rest with a maximum error of 4\% in the predictions. Finally, BP also gets four categories using adversarial patches without changes and for the remaining three classes with a variation of 1\%. Additionally, the statistical analysis showed that the predictions' confidence of BP were not significantly different for each pair of clean and perturbed images in every experiment. These results prove BP's robustness against adversarial examples compared to DCNN and handcrafted features methods, whose performance on the art media classification was compromised with the proposed perturbations.
A Deep Genetic Programming based Methodology for Art Media Classification Robust to Adversarial Perturbations
Oct 03, 2020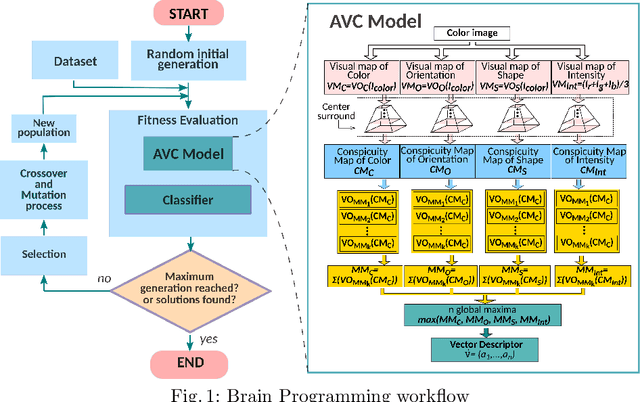
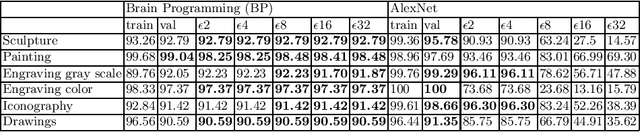
Art Media Classification problem is a current research area that has attracted attention due to the complex extraction and analysis of features of high-value art pieces. The perception of the attributes can not be subjective, as humans sometimes follow a biased interpretation of artworks while ensuring automated observation's trustworthiness. Machine Learning has outperformed many areas through its learning process of artificial feature extraction from images instead of designing handcrafted feature detectors. However, a major concern related to its reliability has brought attention because, with small perturbations made intentionally in the input image (adversarial attack), its prediction can be completely changed. In this manner, we foresee two ways of approaching the situation: (1) solve the problem of adversarial attacks in current neural networks methodologies, or (2) propose a different approach that can challenge deep learning without the effects of adversarial attacks. The first one has not been solved yet, and adversarial attacks have become even more complex to defend. Therefore, this work presents a Deep Genetic Programming method, called Brain Programming, that competes with deep learning and studies the transferability of adversarial attacks using two artworks databases made by art experts. The results show that the Brain Programming method preserves its performance in comparison with AlexNet, making it robust to these perturbations and competing to the performance of Deep Learning.