 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Beamforming with Doppler-Aware Sparse Attention for High Mobility Environments
Nov 05, 2025Beamforming has significance for enhancing spectral efficiency and mitigating interference in multi-antenna wireless systems, facilitating spatial multiplexing and diversity in dense and high mobility scenarios. Traditional beamforming techniques such as zero-forcing beamforming (ZFBF) and minimum mean square error (MMSE) beamforming experience performance deterioration under adverse channel conditions. Deep learning-based beamforming offers an alternative with nonlinear mappings from channel state information (CSI) to beamforming weights by improving robustness against dynamic channel environments. Transformer-based models are particularly effective due to their ability to model long-range dependencies across time and frequency. However, their quadratic attention complexity limits scalability in large OFDM grids. Recent studies address this issue through sparse attention mechanisms that reduce complexity while maintaining expressiveness, yet often employ patterns that disregard channel dynamics, as they are not specifically designed for wireless communication scenarios. In this work, we propose a Doppler-aware Sparse Neural Network Beamforming (Doppler-aware Sparse NNBF) model that incorporates a channel-adaptive sparse attention mechanism in a multi-user single-input multiple-output (MU-SIMO) setting. The proposed sparsity structure is configurable along 2D time-frequency axes based on channel dynamics and is theoretically proven to ensure full connectivity within p hops, where p is the number of attention heads. Simulation results under urban macro (UMa) channel conditions show that Doppler-aware Sparse NNBF significantly outperforms both a fixed-pattern baseline, referred to as Standard Sparse NNBF, and conventional beamforming techniques ZFBF and MMSE beamforming in high mobility scenarios, while maintaining structured sparsity with a controlled number of attended keys per query.
Transformer-Driven Neural Beamforming with Imperfect CSI in Urban Macro Wireless Channels
Apr 15, 2025
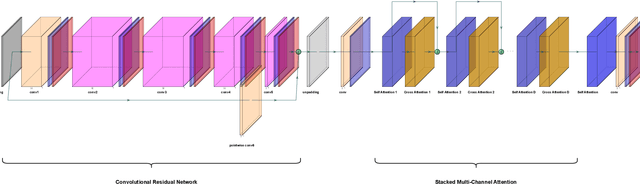
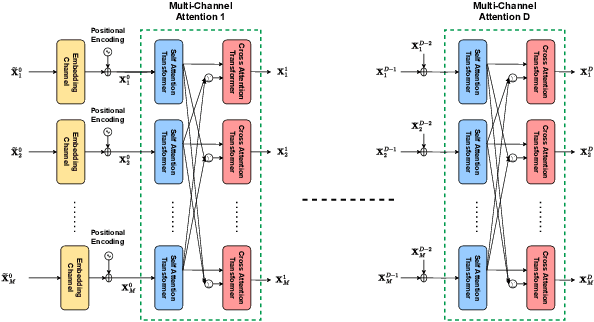

The literature is abundant with methodologies focusing on using transformer architectures due to their prominence in wireless signal processing and their capability to capture long-range dependencies via attention mechanisms. In particular, depthwise separable convolutions enhance parameter efficiency for the process of high-dimensional data characteristics of MIMO systems. In this work, we introduce a novel unsupervised deep learning framework that integrates depthwise separable convolutions and transformers to generate beamforming weights under imperfect channel state information (CSI) for a multi-user single-input multiple-output (MU-SIMO) system in dense urban environments. The primary goal is to enhance throughput by maximizing sum-rate while ensuring reliable communication. Spectral efficiency and block error rate (BLER) are considered as performance metrics. Experiments are carried out under various conditions to compare the performance of the proposed NNBF framework against baseline methods zero-forcing beamforming (ZFBF) and minimum mean square error (MMSE) beamforming. Experimental results demonstrate the superiority of the proposed framework over the baseline techniques.
Deep Learning Based Joint Multi-User MISO Power Allocation and Beamforming Design
Jun 12, 2024



The evolution of fifth generation (5G) wireless communication networks has led to an increased need for wireless resource management solutions that provide higher data rates, wide coverage, low latency, and power efficiency. Yet, many of existing traditional approaches remain non-practical due to computational limitations, and unrealistic presumptions of static network conditions and algorithm initialization dependencies. This creates an important gap between theoretical analysis and real-time processing of algorithms. To bridge this gap, deep learning based techniques offer promising solutions with their representational capabilities for universal function approximation. We propose a novel unsupervised deep learning based joint power allocation and beamforming design for multi-user multiple-input single-output (MU-MISO) system. The objective is to enhance the spectral efficiency by maximizing the sum-rate with the proposed joint design framework, NNBF-P while also offering computationally efficient solution in contrast to conventional approaches. We conduct experiments for diverse settings to compare the performance of NNBF-P with zero-forcing beamforming (ZFBF), minimum mean square error (MMSE) beamforming, and NNBF, which is also our deep learning based beamforming design without joint power allocation scheme. Experiment results demonstrate the superiority of NNBF-P compared to ZFBF, and MMSE while NNBF can have lower performances than MMSE and ZFBF in some experiment settings. It can also demonstrate the effectiveness of joint design framework with respect to NNBF.
Deep Learning Based Uplink Multi-User SIMO Beamforming Design
Sep 28, 2023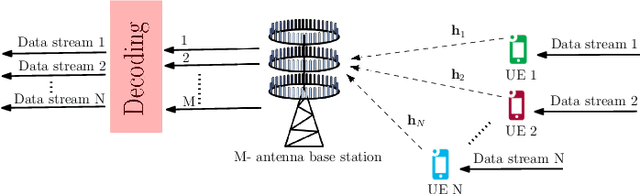
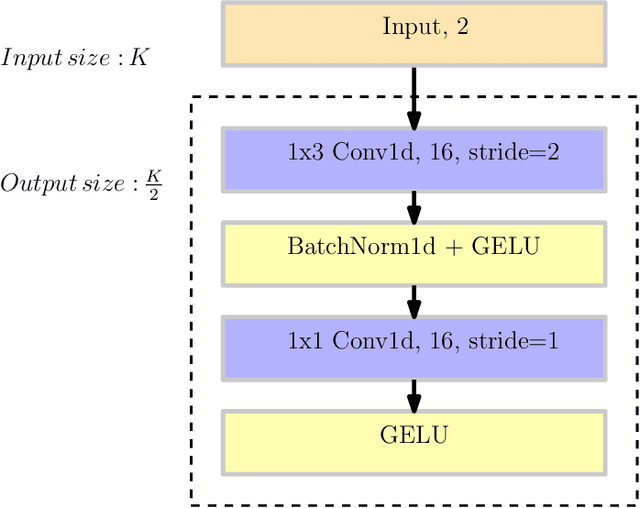
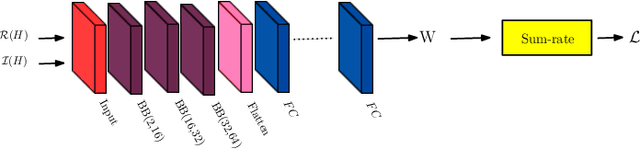
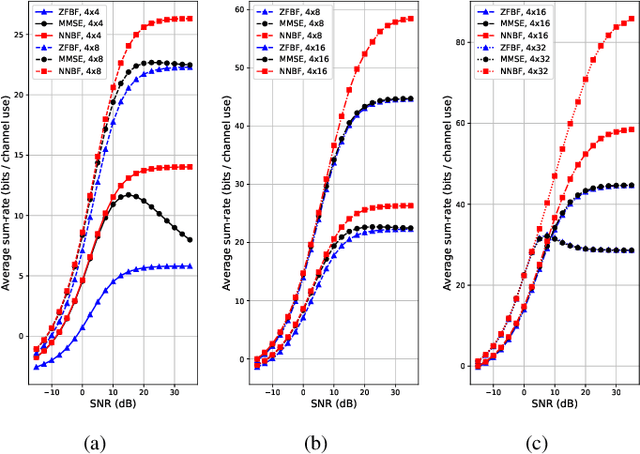
The advancement of fifth generation (5G) wireless communication networks has created a greater demand for wireless resource management solutions that offer high data rates, extensive coverage, minimal latency and energy-efficient performance. Nonetheless, traditional approaches have shortcomings when it comes to computational complexity and their ability to adapt to dynamic conditions, creating a gap between theoretical analysis and the practical execution of algorithmic solutions for managing wireless resources. Deep learning-based techniques offer promising solutions for bridging this gap with their substantial representation capabilities. We propose a novel unsupervised deep learning framework, which is called NNBF, for the design of uplink receive multi-user single input multiple output (MU-SIMO) beamforming. The primary objective is to enhance the throughput by focusing on maximizing the sum-rate while also offering computationally efficient solution, in contrast to established conventional methods. We conduct experiments for several antenna configurations. Our experimental results demonstrate that NNBF exhibits superior performance compared to our baseline methods, namely, zero-forcing beamforming (ZFBF) and minimum mean square error (MMSE) equalizer. Additionally, NNBF is scalable to the number of single-antenna user equipments (UEs) while baseline methods have significant computational burden due to matrix pseudo-inverse operation.
Hierarchical Over-the-Air FedGradNorm
Dec 14, 2022



Multi-task learning (MTL) is a learning paradigm to learn multiple related tasks simultaneously with a single shared network where each task has a distinct personalized header network for fine-tuning. MTL can be integrated into a federated learning (FL) setting if tasks are distributed across clients and clients have a single shared network, leading to personalized federated learning (PFL). To cope with statistical heterogeneity in the federated setting across clients which can significantly degrade the learning performance, we use a distributed dynamic weighting approach. To perform the communication between the remote parameter server (PS) and the clients efficiently over the noisy channel in a power and bandwidth-limited regime, we utilize over-the-air (OTA) aggregation and hierarchical federated learning (HFL). Thus, we propose hierarchical over-the-air (HOTA) PFL with a dynamic weighting strategy which we call HOTA-FedGradNorm. Our algorithm considers the channel conditions during the dynamic weight selection process. We conduct experiments on a wireless communication system dataset (RadComDynamic). The experimental results demonstrate that the training speed with HOTA-FedGradNorm is faster compared to the algorithms with a naive static equal weighting strategy. In addition, HOTA-FedGradNorm provides robustness against the negative channel effects by compensating for the channel conditions during the dynamic weight selection process.
FedGradNorm: Personalized Federated Gradient-Normalized Multi-Task Learning
Mar 24, 2022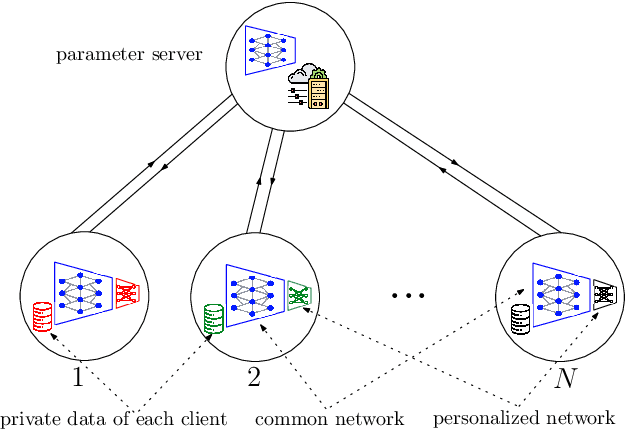
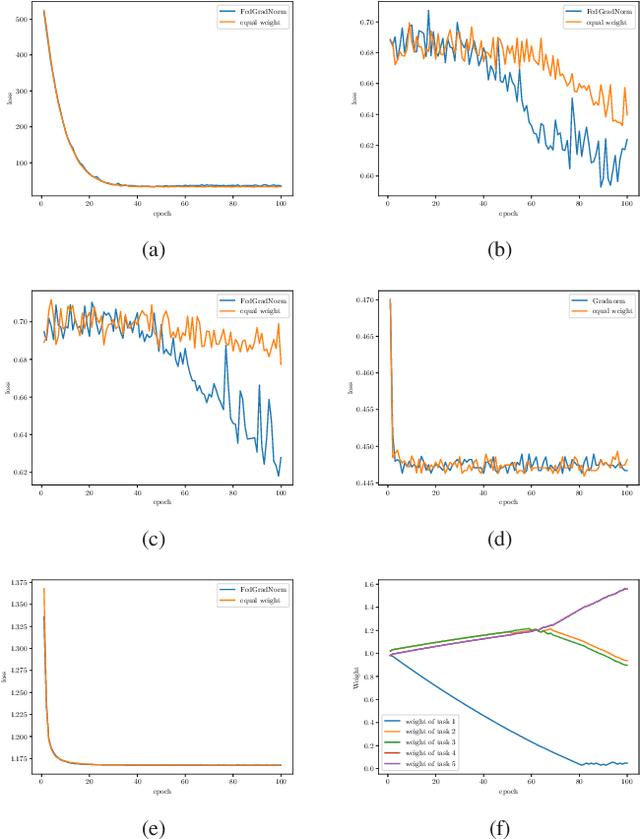
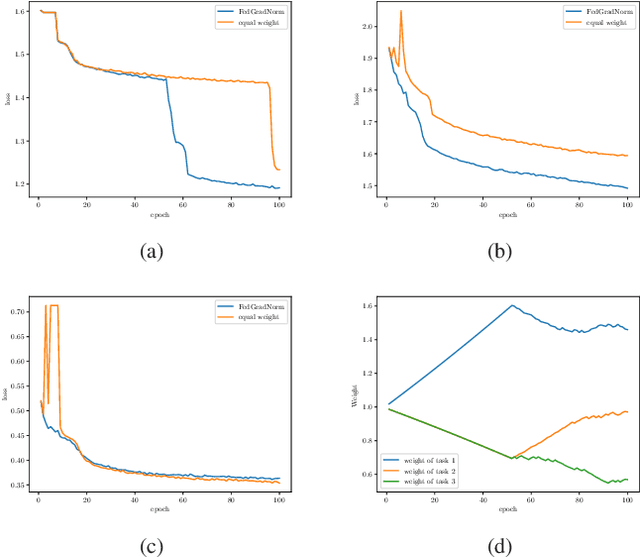
Multi-task learning (MTL) is a novel framework to learn several tasks simultaneously with a single shared network where each task has its distinct personalized header network for fine-tuning. MTL can be implemented in federated learning settings as well, in which tasks are distributed across clients. In federated settings, the statistical heterogeneity due to different task complexities and data heterogeneity due to non-iid nature of local datasets can both degrade the learning performance of the system. In addition, tasks can negatively affect each other's learning performance due to negative transference effects. To cope with these challenges, we propose FedGradNorm which uses a dynamic-weighting method to normalize gradient norms in order to balance learning speeds among different tasks. FedGradNorm improves the overall learning performance in a personalized federated learning setting. We provide convergence analysis for FedGradNorm by showing that it has an exponential convergence rate. We also conduct experiments on multi-task facial landmark (MTFL) and wireless communication system dataset (RadComDynamic). The experimental results show that our framework can achieve faster training performance compared to equal-weighting strategy. In addition to improving training speed, FedGradNorm also compensates for the imbalanced datasets among clients.