 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA zone-based training approach for last-mile routing using Graph Neural Networks and Pointer Networks
Jan 08, 2026Rapid e-commerce growth has pushed last-mile delivery networks to their limits, where small routing gains translate into lower costs, faster service, and fewer emissions. Classical heuristics struggle to adapt when travel times are highly asymmetric (e.g., one-way streets, congestion). A deep learning-based approach to the last-mile routing problem is presented to generate geographical zones composed of stop sequences to minimize last-mile delivery times. The presented approach is an encoder-decoder architecture. Each route is represented as a complete directed graph whose nodes are stops and whose edge weights are asymmetric travel times. A Graph Neural Network encoder produces node embeddings that captures the spatial relationships between stops. A Pointer Network decoder then takes the embeddings and the route's start node to sequentially select the next stops, assigning a probability to each unvisited node as the next destination. Cells of a Discrete Global Grid System which contain route stops in the training data are obtained and clustered to generate geographical zones of similar size in which the process of training and inference are divided. Subsequently, a different instance of the model is trained per zone only considering the stops of the training routes which are included in that zone. This approach is evaluated using the Los Angeles routes from the 2021 Amazon Last Mile Routing Challenge. Results from general and zone-based training are compared, showing a reduction in the average predicted route length in the zone-based training compared to the general training. The performance improvement of the zone-based approach becomes more pronounced as the number of stops per route increases.
Data Cleansing for Indoor Positioning Wi-Fi Fingerprinting Datasets
May 04, 2022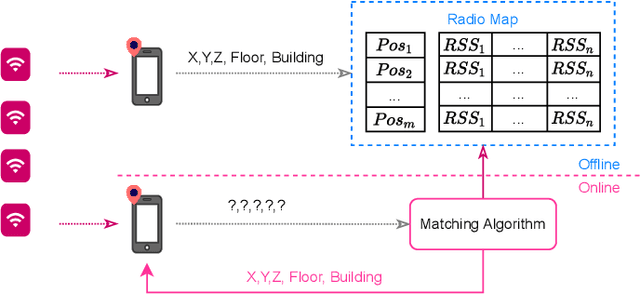
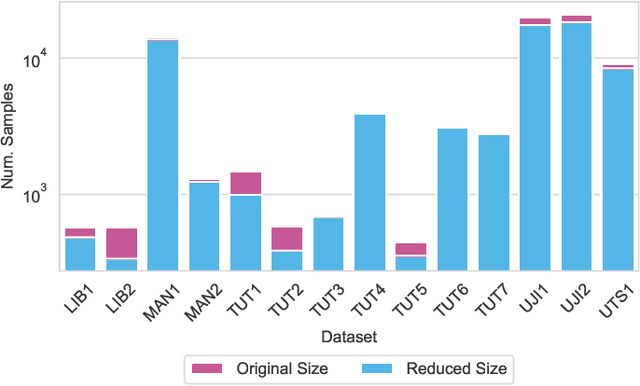

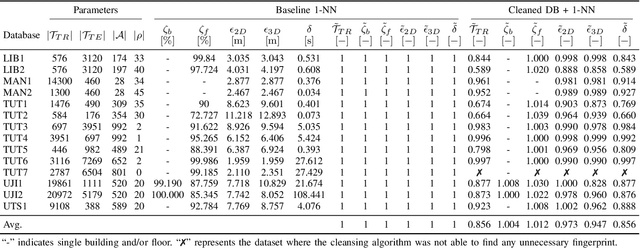
Wearable and IoT devices requiring positioning and localisation services grow in number exponentially every year. This rapid growth also produces millions of data entries that need to be pre-processed prior to being used in any indoor positioning system to ensure the data quality and provide a high Quality of Service (QoS) to the end-user. In this paper, we offer a novel and straightforward data cleansing algorithm for WLAN fingerprinting radio maps. This algorithm is based on the correlation among fingerprints using the Received Signal Strength (RSS) values and the Access Points (APs)'s identifier. We use those to compute the correlation among all samples in the dataset and remove fingerprints with low level of correlation from the dataset. We evaluated the proposed method on 14 independent publicly-available datasets. As a result, an average of 14% of fingerprints were removed from the datasets. The 2D positioning error was reduced by 2.7% and 3D positioning error by 5.3% with a slight increase in the floor hit rate by 1.2% on average. Consequently, the average speed of position prediction was also increased by 14%.
Towards Accelerated Localization Performance Across Indoor Positioning Datasets
Apr 22, 2022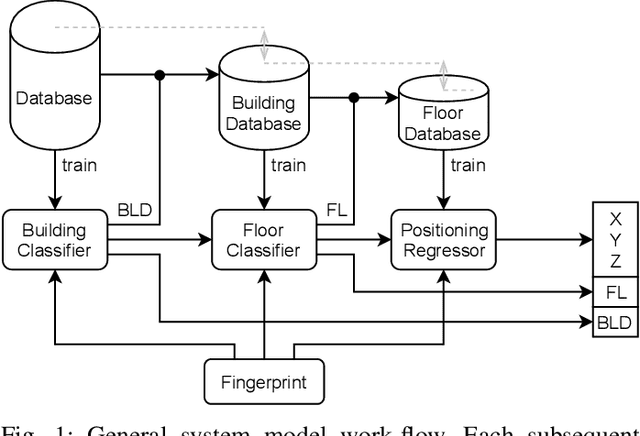
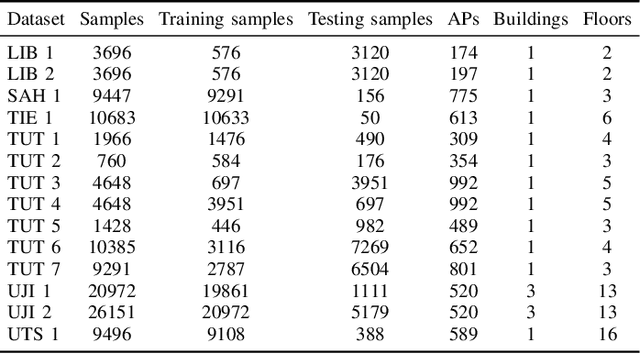
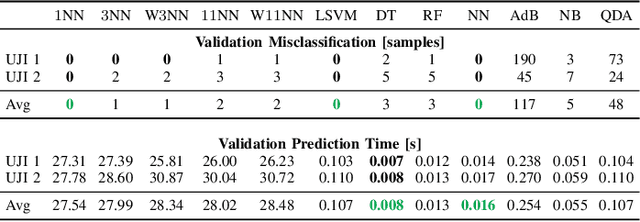
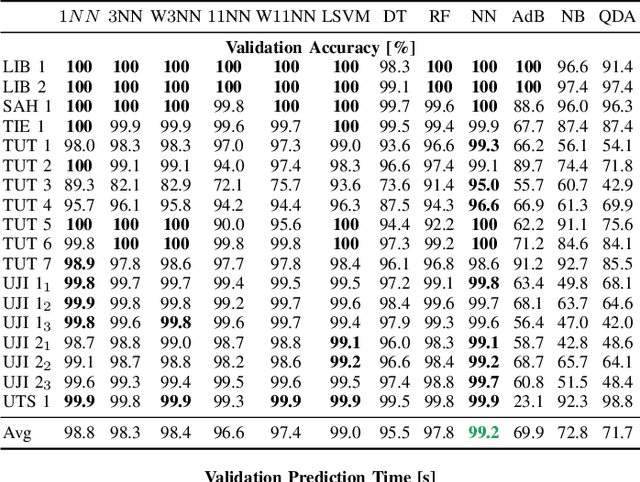
The localization speed and accuracy in the indoor scenario can greatly impact the Quality of Experience of the user. While many individual machine learning models can achieve comparable positioning performance, their prediction mechanisms offer different complexity to the system. In this work, we propose a fingerprinting positioning method for multi-building and multi-floor deployments, composed of a cascade of three models for building classification, floor classification, and 2D localization regression. We conduct an exhaustive search for the optimally performing one in each step of the cascade while validating on 14 different openly available datasets. As a result, we bring forward the best-performing combination of models in terms of overall positioning accuracy and processing speed and evaluate on independent sets of samples. We reduce the mean prediction time by 71% while achieving comparable positioning performance across all considered datasets. Moreover, in case of voluminous training dataset, the prediction time is reduced down to 1% of the benchmark's.