 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Driven State Aggregation Approach for Dynamic Discrete Choice Models
Apr 20, 2023We study dynamic discrete choice models, where a commonly studied problem involves estimating parameters of agent reward functions (also known as "structural" parameters), using agent behavioral data. Maximum likelihood estimation for such models requires dynamic programming, which is limited by the curse of dimensionality. In this work, we present a novel algorithm that provides a data-driven method for selecting and aggregating states, which lowers the computational and sample complexity of estimation. Our method works in two stages. In the first stage, we use a flexible inverse reinforcement learning approach to estimate agent Q-functions. We use these estimated Q-functions, along with a clustering algorithm, to select a subset of states that are the most pivotal for driving changes in Q-functions. In the second stage, with these selected "aggregated" states, we conduct maximum likelihood estimation using a commonly used nested fixed-point algorithm. The proposed two-stage approach mitigates the curse of dimensionality by reducing the problem dimension. Theoretically, we derive finite-sample bounds on the associated estimation error, which also characterize the trade-off of computational complexity, estimation error, and sample complexity. We demonstrate the empirical performance of the algorithm in two classic dynamic discrete choice estimation applications.
Deep PQR: Solving Inverse Reinforcement Learning using Anchor Actions
Aug 15, 2020

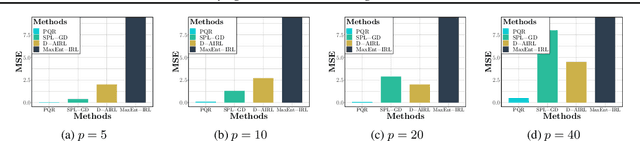

We propose a reward function estimation framework for inverse reinforcement learning with deep energy-based policies. We name our method PQR, as it sequentially estimates the Policy, the $Q$-function, and the Reward function by deep learning. PQR does not assume that the reward solely depends on the state, instead it allows for a dependency on the choice of action. Moreover, PQR allows for stochastic state transitions. To accomplish this, we assume the existence of one anchor action whose reward is known, typically the action of doing nothing, yielding no reward. We present both estimators and algorithms for the PQR method. When the environment transition is known, we prove that the PQR reward estimator uniquely recovers the true reward. With unknown transitions, we bound the estimation error of PQR. Finally, the performance of PQR is demonstrated by synthetic and real-world datasets.